一張照片,TikTok小姐姐就都能跳舞了
前幾日,阿里研究團隊構建了一種名為 Animate Anyone 的方法,只需要一張人物照片,再配合骨骼動畫引導,就能生成自然的動畫視頻。不過,這項研究的源代碼還沒有發布。
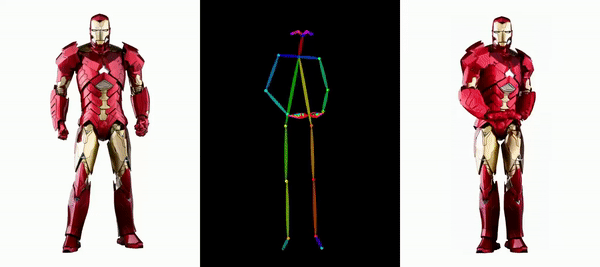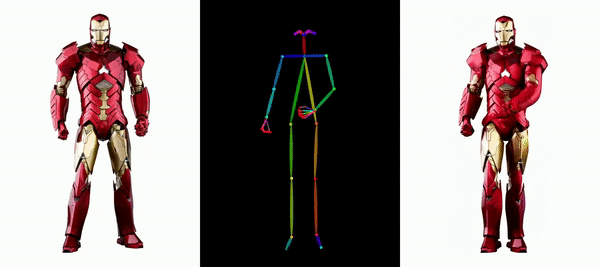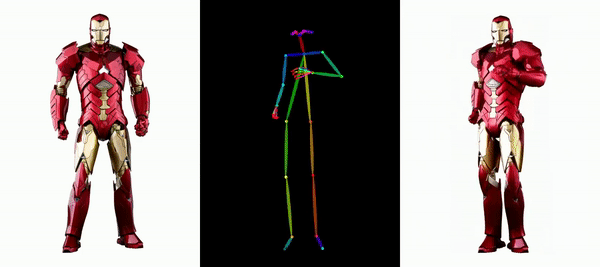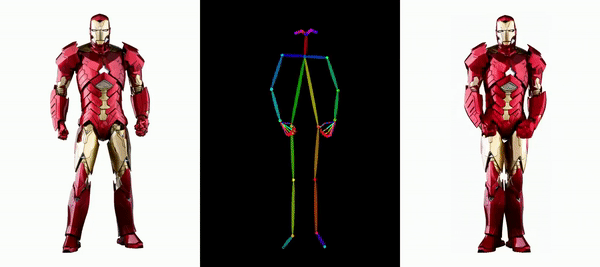
讓鋼鐵俠動起來。
其實在 Animate Anyone 這篇論文出現在 arXiv 上的前一天,新加坡國立大學 Show 實驗室和字節聯合做了一項類似的研究。他們提出了一個基于擴散的框架 MagicAnimate,旨在增強時間一致性、忠實地保留參考圖像并提升動畫保真度。并且,MagicAnimate 項目是開源的,目前推理代碼和 gradio 在線 demo 已經發布。

- 論文地址:https://arxiv.org/pdf/2311.16498.pdf
- 項目地址:https://showlab.github.io/magicanimate/
- GitHub 地址:https://github.com/magic-research/magic-animate
為了實現上述目標,研究者首先開發了一個視頻擴散模型來編碼時間信息。接著為了保持跨幀的外觀連貫性,他們引入了新穎的外觀編碼器來保留參考圖像的復雜細節。利用這兩個創新,研究者進一步使用簡單的視頻融合技術來保證長視頻動畫的平滑過渡。
實驗結果表明,MagicAnimate 在兩項基準測試上均優于基線方法。尤其在具有挑戰性的 TikTok 跳舞數據集上,本文方法在視頻保真度方面比最強基線方法高出 38%以上。
我們來看以下幾個 TikTok 小姐姐的動態展示效果。



除了跳舞的 TikTok 小姐姐之外,還有「跑起來」的神奇女俠。

戴珍珠耳環的少女、蒙娜麗莎都做起了瑜伽。


除了單人,多人跳舞也能搞定。


與其他方法比較,效果高下立判。

還有國外網友在HuggingFace上創建了一個試用空間,創建一個動畫視頻只要幾分鐘。不過這個網站已經404了。

圖源:https://twitter.com/gijigae/status/1731832513595953365

接下來介紹 MagicAnimate 的方法和實驗結果。
方法概覽
給定參考圖像 I_ref 和運動序列 ,其中 N 是幀數。MagicAnimate 旨在合成連續視頻
,其中 N 是幀數。MagicAnimate 旨在合成連續視頻
 。其中出現畫面 I_ref,同時遵循運動序列
。其中出現畫面 I_ref,同時遵循運動序列 。現有基于擴散模型的框架獨立處理每個幀,忽略了幀之間的時間一致性,從而導致生成的動畫存在「閃爍」問題。
。現有基于擴散模型的框架獨立處理每個幀,忽略了幀之間的時間一致性,從而導致生成的動畫存在「閃爍」問題。
為了解決該問題,該研究通過將時間注意力(temporal attention)塊合并到擴散主干網絡中,來構建用于時間建模的視頻擴散模型 。
。
此外,現有工作使用 CLIP 編碼器對參考圖像進行編碼,但該研究認為這種方法無法捕獲復雜細節。因此,該研究提出了一種新型外觀編碼器(appearance encoder) ,將 I_ref 編碼到外觀嵌入 y_a 中,并以此為基礎對模型進行調整。
,將 I_ref 編碼到外觀嵌入 y_a 中,并以此為基礎對模型進行調整。
MagicAnimate 的整體流程如下圖 2 所示,首先使用外觀編碼器將參考圖像嵌入到外觀嵌入中,然后再將目標姿態序列傳遞到姿態 ControlNet 中,以提取運動條件
中,以提取運動條件 。
。

在實踐中,由于內存限制,MagicAnimate 以分段的方式處理整個視頻。得益于時間建模和強大的外觀編碼,MagicAnimate 可以在很大程度上保持片段之間的時間和外觀一致性。但各部分之間仍然存在細微的不連續性,為了緩解這種情況,研究團隊利用簡單的視頻融合方法來提高過渡平滑度。
如圖 2 所示,MagicAnimate 將整個視頻分解為重疊的片段,并簡單地對重疊幀的預測進行平均。最后,該研究還引入圖像 - 視頻聯合訓練策略,以進一步增強參考圖像保留能力和單幀保真度。
實驗及結果
實驗部分,研究者在兩個數據集評估了 MagicAnimate 的性能,分別是 TikTok 和 TED-talks。其中 TikTok 數據集包含了 350 個跳舞視頻,TED-talks 包含 1,203 個提取自 YouTube 上 TED 演講視頻的片段。
首先看定量結果。下表 1 展示了兩個數據集上 MagicAnimate 與基線方法的定量結果比較,其中表 1a 顯示在 TikTok 數據集上,本文方法在 L1、PSNR、SSIM 和 LPIPS 等重建指標上超越了所有基線方法。
表 1b 顯示在 TED-talks 數據集上,MagicAnimate 在視頻保真度方面也更好,取得了最好的 FID-VID 分數(19.00)和 FVD 分數(131.51)。

再看定性結果。研究者在下圖 3 展示了 MagicAnimate 與其他基線方法的定性比較。本文方法實現了更好的保真度,展現了更強的背景保留能力, 這要歸功于從參考圖像中提取細節信息的外觀編碼器。

研究者還評估了 MagicAnimate 的跨身份動畫(Cross-identity animation),以及與 SOTA 基線方法的比較,即 DisCo 和 MRAA。具體來講,他們從 TikTok 測試集中采樣了兩個 DensePose 運動序列,并使用這些序列對其他視頻的參考圖像進行動畫處理。
下圖 1 顯示出 MRAA 無法泛化到包含大量不同姿態的驅動視頻,而 DisCo 難以保留參考圖像的細節。相比之下,本文方法忠實地為給定目標運動的參考圖像設置動畫,展示了其穩健性。

最后是消融實驗。為了驗證 MagicAnimate 中設計選擇的有效性,研究者在 TikTok 數據集上進行了消融實驗,包括下表 2 和下圖 4 中有無時間建模、外觀編碼器、推理階段視頻融合以及圖像 - 視頻聯合訓練等。


MagicAnimate 的應用前景也很廣。研究者表示,盡管僅接受了真實人類數據的訓練,但它展現出了泛化到各種應用場景的能力,包括對未見過的領域數據進行動畫處理、與文本 - 圖像擴散模型的集成以及多人動畫等。

更多細節請閱讀原論文。