













如何鎖住數據庫中幾十億小姐姐?
數據庫中有一張叫后宮佳麗的表,每天都有幾百萬新的小姐姐插到表中,光陰荏苒,夜以繼日,日久生情,時間長了,表中就有了幾十億的小姐姐數據。
圖片來自 Pexels
看到幾十億的小姐姐,每到晚上,我可愁死了,這么多小姐姐,我翻張牌呢?
辦法當然是精兵簡政,刪除那些 age>18 的,給年輕的小姐姐們留位置...
于是我在數據庫中添加了一個定時執行的小程序,每到周日,就自動運行如下的腳本:
- delete from `后宮佳麗` where age>18
一開始還自我感覺良好,后面我就發現不對了,每到周日,這個腳本一執行就是一整天。
運行的時間有點長是小事,重點是這大好周日,我再想讀這張表的數據,怎么也讀不出來了,怎是一句空虛了得,我好難啊......
為什么?編不下去了,真實背景是公司中遇到的一張有海量數據表,每次一旦執行歷史數據的清理,我們的程序就因為讀不到這張表的數據,瘋狂地報錯。
后面一查了解到,原來是因為定時刪除的語句設計不合理,導致數據庫中數據由行鎖(Row lock)升級為表鎖(Table lock)了!😂
解決這個問題的過程中把數據庫鎖相關的學習了一下,這里把學習成果,分享給大家,希望對大家有所幫助。
我將討論 SQL Server 鎖機制以及如何使用 SQL Server 標準動態管理視圖監視 SQL Server 中的鎖,相信其他數據的鎖也大同小異,具有一定參考意義。
鋪墊知識
在我開始解釋 SQL Server 鎖定體系結構之前,讓我們花點時間來描述ACID(原子性,一致性,隔離性和持久性)是什么。
ACID 是指數據庫管理系統(DBMS)在寫入或更新資料的過程中,為保證事務(transaction)是正確可靠的,所必須具備的四個特性:
- 原子性(atomicity,或稱不可分割性)
- 一致性(consistency)
- 隔離性(isolation,又稱獨立性)
- 持久性(durability)
ACID
①原子性(Atomicity)
一個事務(transaction)中的所有操作,或者全部完成,或者全部不完成,不會結束在中間某個環節。
事務在執行過程中發生錯誤,會被回滾(Rollback)到事務開始前的狀態,就像這個事務從來沒有執行過一樣。即,事務不可分割、不可約簡。
②一致性(Consistency)
在事務開始之前和事務結束以后,數據庫的完整性沒有被破壞。這表示寫入的資料必須完全符合所有的預設約束、觸發器、級聯回滾等。
③隔離性(Isolation)
數據庫允許多個并發事務同時對其數據進行讀寫和修改的能力,隔離性可以防止多個事務并發執行時由于交叉執行而導致數據的不一致。
事務隔離分為不同級別,包括未提交讀(Read uncommitted)、提交讀(read committed)、可重復讀(repeatable read)和串行化(Serializable)。
④持久性(Durability)
事務處理結束后,對數據的修改就是永久的,即便系統故障也不會丟失。
來源維基百科:
- https://zh.wikipedia.org/wiki/ACID
事務(Transaction)
事務是進程中最小的堆棧,不能分成更小的部分。
此外,某些事務處理組可以按順序執行,但正如我們在原子性原則中所解釋的那樣,即使其中一個事務失敗,所有事務塊也將失敗。
鎖定(Lock)
鎖定是一種確保數據一致性的機制。SQL Server 在事務啟動時鎖定對象。事務完成后,SQL Server 將釋放鎖定的對象。可以根據 SQL Server 進程類型和隔離級別更改此鎖定模式。
這些鎖定模式是:
①鎖定層次結構
SQL Server 具有鎖定層次結構,用于獲取此層次結構中的鎖定對象。數據庫位于層次結構的頂部,行位于底部。
下圖說明了 SQL Server 的鎖層次結構:

②共享(S)鎖(Shared (S) Locks)
當需要讀取對象時,會發生此鎖定類型。這種鎖定類型不會造成太大問題。
③獨占(X)鎖定(Exclusive (X) Locks)
發生此鎖定類型時,會發生以防止其他事務修改或訪問鎖定對象。
④更新(U)鎖(Update (U) Locks)
此鎖類型與獨占鎖類似,但它有一些差異。我們可以將更新操作劃分為不同的階段:讀取階段和寫入階段。
在讀取階段,SQL Server 不希望其他事務有權訪問此對象以進行更改,因此,SQL Server 使用更新鎖。
⑤意圖鎖定(Intent Locks)
當 SQL Server 想要在鎖定層次結構中較低的某些資源上獲取共享(S)鎖定或獨占(X)鎖定時,會發生意圖鎖定。
實際上,當 SQL Server 獲取頁面或行上的鎖時,表中需要設置意圖鎖。
SQL Server locking
了解了這些背景知識后,我們嘗試再 SQL Server 找到這些鎖。SQL Server 提供了許多動態管理視圖來訪問指標。
要識別 SQL Server 鎖,我們可以使用 sys.dm_tran_locks 視圖。在此視圖中,我們可以找到有關當前活動鎖管理的大量信息。
在第一個示例中,我們將創建一個不包含任何索引的演示表,并嘗試更新此演示表:
- CREATE TABLE TestBlock
- (Id INT ,
- Nm VARCHAR(100))
- INSERT INTO TestBlock
- values(1,'CodingSight')
- In this step, we will create an open transaction and analyze the locked resources.
- BEGIN TRAN
- UPDATE TestBlock SET Nm='NewValue_CodingSight' where Id=1
- select @@SPID
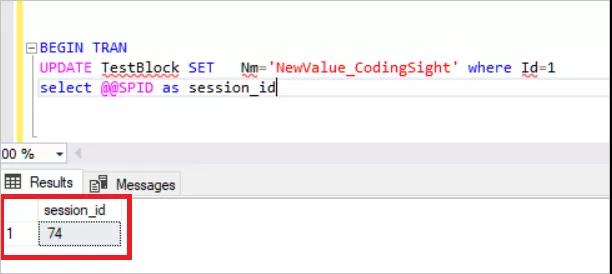
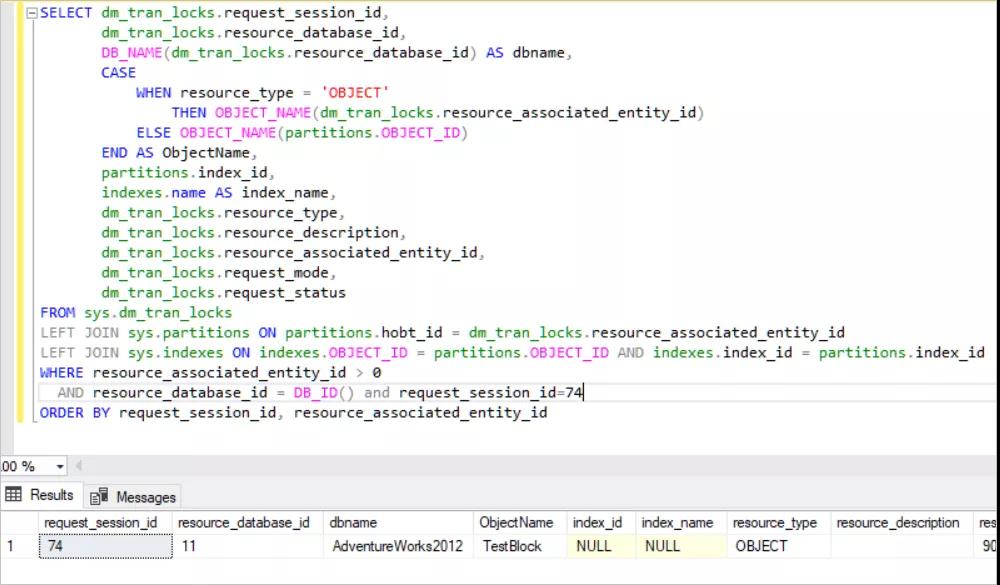
再獲取到了 SPID 后,我們來看看 sys.dm_tran_lock 視圖里有什么:
- select * from sys.dm_tran_locks WHERE request_session_id=74
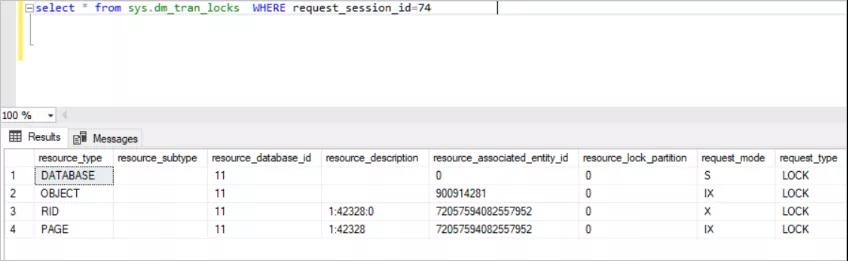
此視圖返回有關活動鎖資源的大量信息,但是是一些我們難以理解的一些數據。
因此,我們必須將 sys.dm_tran_locks join 一些其他表:
- SELECT dm_tran_locks.request_session_id,
- dm_tran_locks.resource_database_id,
- DB_NAME(dm_tran_locks.resource_database_id) AS dbname,
- CASE
- WHEN resource_type = 'OBJECT'
- THEN OBJECT_NAME(dm_tran_locks.resource_associated_entity_id)
- ELSE OBJECT_NAME(partitions.OBJECT_ID)
- END AS ObjectName,
- partitions.index_id,
- indexes.name AS index_name,
- dm_tran_locks.resource_type,
- dm_tran_locks.resource_description,
- dm_tran_locks.resource_associated_entity_id,
- dm_tran_locks.request_mode,
- dm_tran_locks.request_status
- FROM sys.dm_tran_locks
- LEFT JOIN sys.partitions ON partitions.hobt_id = dm_tran_locks.resource_associated_entity_id
- LEFT JOIN sys.indexes ON indexes.OBJECT_ID = partitions.OBJECT_ID AND indexes.index_id = partitions.index_id
- WHERE resource_associated_entity_id > 0
- AND resource_database_id = DB_ID()
- and request_session_id=74
- ORDER BY request_session_id, resource_associated_entity_id
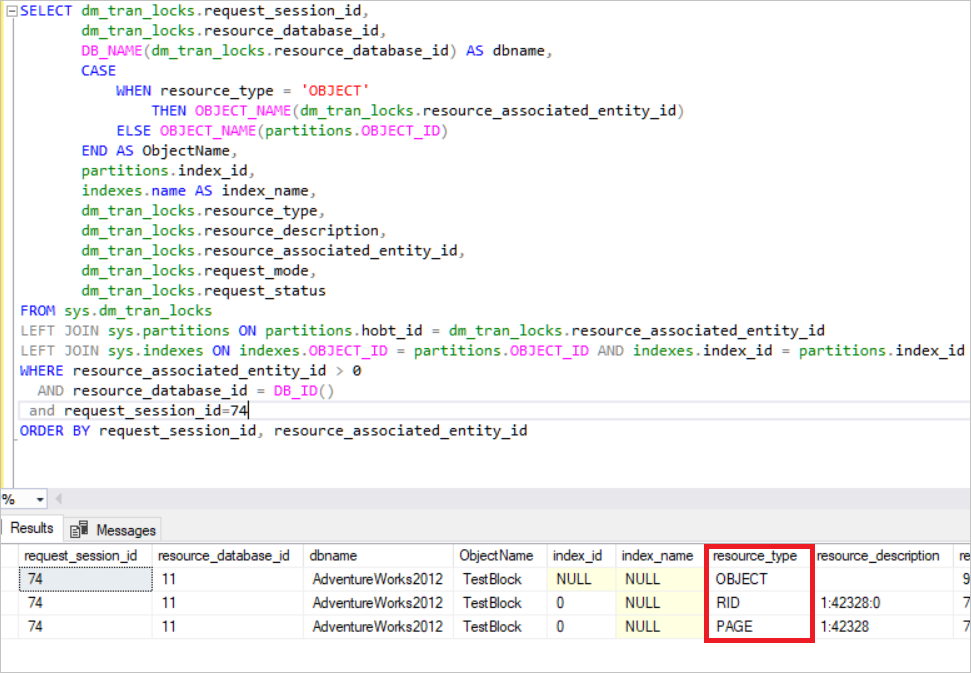
在上圖中,您可以看到鎖定的資源。SQL Server 獲取該行中的獨占鎖。(RID:用于鎖定堆中單個行的行標識符)同時,SQL Server 獲取頁中的獨占鎖和 TestBlock 表意向鎖。
這意味著在 SQL Server 釋放鎖之前,任何其他進程都無法讀取此資源,這是 SQL Server 中的基本鎖定機制。
現在,我們將在測試表上填充一些合成數據:
- TRUNCATE TABLE TestBlock
- DECLARE @K AS INT=0
- WHILE @K <8000
- BEGIN
- INSERT TestBlock VALUES(@K, CAST(@K AS varchar(10)) + ' Value' )
- SET @K=@K+1
- END
- --After completing this step, we will run two queries and check the sys.dm_tran_locks view.
- BEGIN TRAN
- UPDATE TestBlock set Nm ='New_Value' where Id<5000
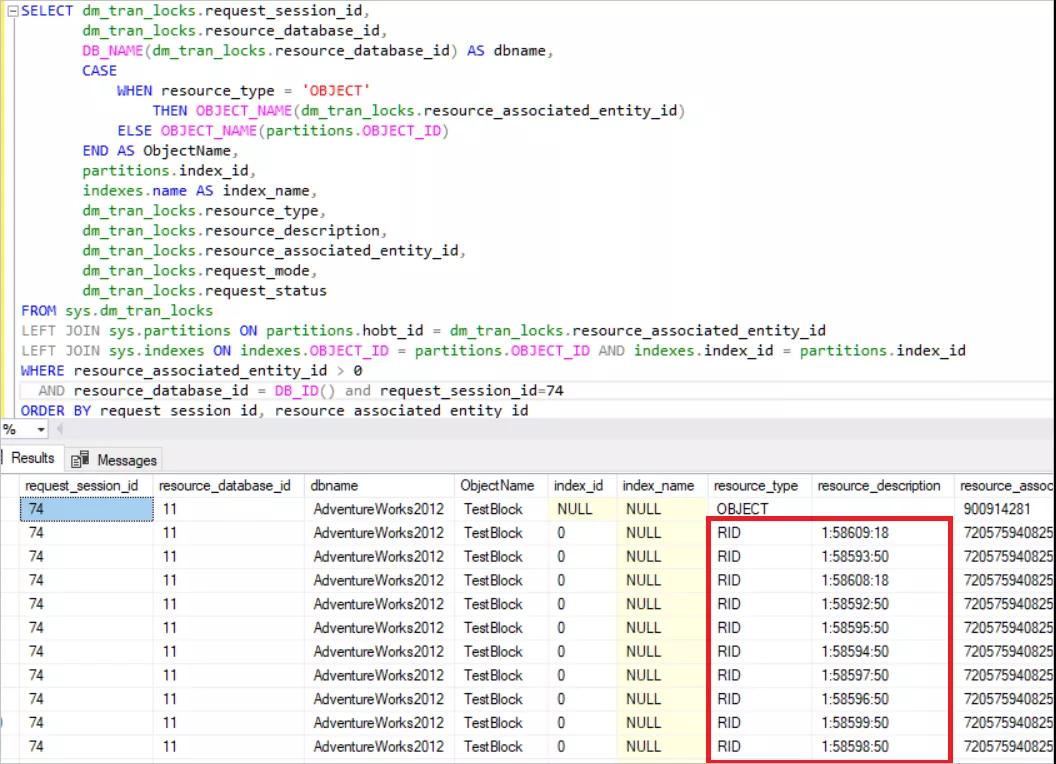
在上面的查詢中,SQL Server 獲取每一行的獨占鎖。現在,我們將運行另一個查詢:
- BEGIN TRAN
- UPDATE TestBlock set Nm ='New_Value' where Id<7000
在上面的查詢中,SQL Server 在表上創建了獨占鎖,因為 SQL Server 嘗試為這些將要更新的行獲取大量 RID 鎖。
這種情況會導致數據庫引擎中的大量資源消耗,因此,SQL Server 會自動將此獨占鎖定移動到鎖定層次結構中的上級對象(Table)。
我們將此機制定義為 Lock Escalation,這就是我開篇所說的鎖升級,它由行鎖升級成了表鎖。
根據官方文檔的描述存在以下任一條件,則會觸發鎖定升級:
- 單個 Transact-SQL 語句在單個非分區表或索引上獲取至少 5,000 個鎖。
- 單個 Transact-SQL 語句在分區表的單個分區上獲取至少 5,000 個鎖,并且 ALTER TABLE SET LOCK_ESCALATION 選項設置為 AUTO。
- 數據庫引擎實例中的鎖數超過了內存或配置閾值。
鏈接如下:
- https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-2008-r2/ms184286(v=sql.105)
如何避免鎖升級
防止鎖升級的最簡單,最安全的方法是保持事務的簡短,并減少昂貴查詢的鎖占用空間,以便不超過鎖升級閾值,有幾種方法可以實現這一目標。
①將大批量操作分解為幾個較小的操作
例如,在我開篇所說的在幾十億條數據中刪除小姐姐的數據:
- delete from `后宮佳麗` where age>18
我們可以不要這么心急,一次只刪除 500 個,可以顯著減少每個事務累積的鎖定數量并防止鎖定升級。
例如:
- SET ROWCOUNT 500
- delete_more:
- delete from `后宮佳麗` where age>18
- IF @@ROWCOUNT > 0 GOTO delete_more
- SET ROWCOUNT 0
②創建索引使查詢盡可能高效來減少查詢的鎖定占用空間
如果沒有索引會造成表掃描可能會增加鎖定升級的可能性,更可怕的是,它增加了死鎖的可能性,并且通常會對并發性和性能產生負面影響。
根據查詢條件創建合適的索引,最大化提升索引查找的效率,此優化的一個目標是使索引查找返回盡可能少的行,以最小化查詢的的成本。
③如果其他 SPID 當前持有不兼容的表鎖,則不會發生鎖升級
鎖定升級始總是升級成表鎖,而不會升級到頁面鎖定。
如果另一個 SPID 持有與升級的表鎖沖突的 IX(intent exclusive)鎖定,則它會獲取更細粒度的級別(行,key 或頁面)鎖定,定期進行額外的升級嘗試。
表級別的 IX(intent exclusive)鎖定不會鎖定任何行或頁面,但它仍然與升級的 S(共享)或 X(獨占)TAB 鎖定不兼容。
如下所示,如果有個操作始終在不到一小時內完成,您可以創建包含以下代碼的 SQL,并安排在操作的前執行:
BEGIN TRANSELECT * FROM mytable (UPDLOCK, HOLDLOCK) WHERE 1=0WAITFOR DELAY '1:00:00'COMMIT TRAN
此查詢在 mytable 上獲取并保持 IX 鎖定一小時,這可防止在此期間對表進行鎖定升級。
Happy Ending
好了,不說了,小姐姐們因為不想離我開又打起來了(死鎖)。
作者:阿宇
編輯:陶家龍
出處:https://www.cnblogs.com/CoderAyu/






















