













一張照片、一段聲音秒生超逼真視頻!南大等提出全新框架,口型動作精準還原
一段音頻+一張照片,瞬間照片里的人就能開始講話了。
生成的講話動畫不但口型和音頻能夠無縫對齊,面部表情和頭部姿勢都非常自然而且有表現力。
而且支持的圖像風格也非常的多樣,除了一般的照片,卡通圖片,證件照等生成的效果都非常自然。
再加上多語言的支持,瞬間照片里的人物就活了過來,張嘴就能飆外語。
這是由來自南京大學等機構的研究人員提出的一個通用框架——VividTalk,只需要語音和一張圖片,就能生成高質量的說話視頻。

論文地址:https://arxiv.org/abs/2312.01841
這個框架是一個由音頻到網格生成,和網格到視頻生成組成的兩階段框架。
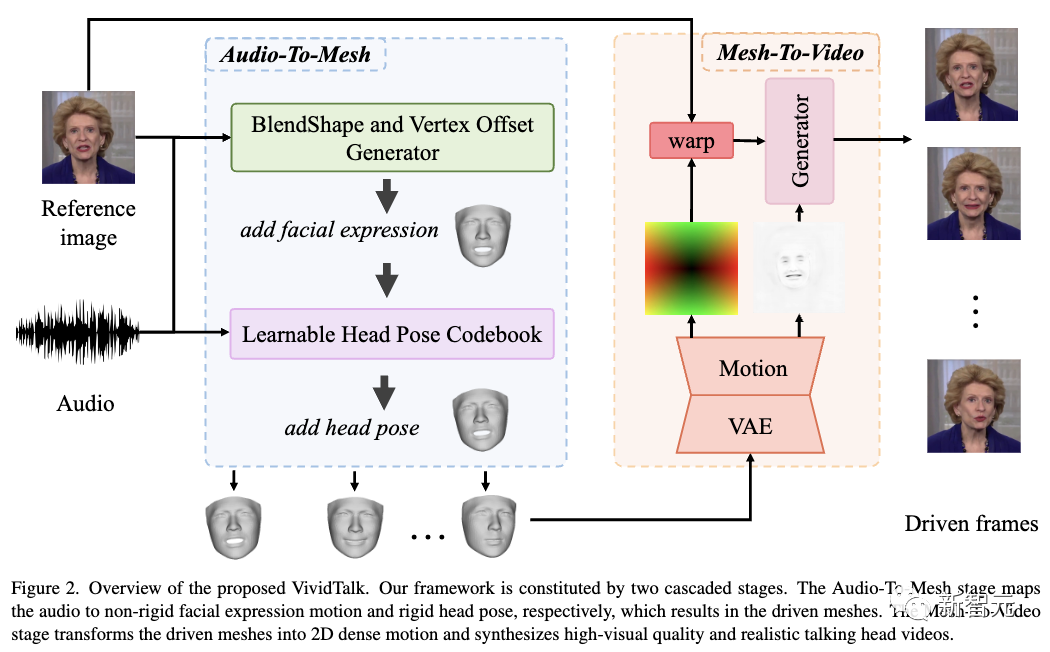
在第一階段,考慮面部運動和blendshape分布之間的一對多映射,利用blendshape和3D頂點作為中間表征,其中blendshape提供粗略運動,頂點偏移描述細粒度嘴唇運動。
此外,還采用了基于多分支Transformer網絡,以充分利用音頻上下文來建模與中間表征的關系。
為了更合理地從音頻中學習剛性頭部運動,研究人員將此問題轉化為離散有限空間中的代碼查詢任務,并構建具有重建和映射機制的可學習頭部姿勢代碼本。
之后,學習到的兩個運動都應用于參考標識,從而產生驅動網格。
在第二階段,基于驅動網格和參考圖像,渲染內表面和外表面(例如軀干)的投影紋理,從而全面建模運動。
然后設計一種新穎的雙分支運動模型來模擬密集運動,將其作為輸入發送到生成器,以逐幀方式合成最終視頻。
VividTalk可以生成具有表情豐富的面部表情和自然頭部姿勢的口型同步頭部說話視頻。
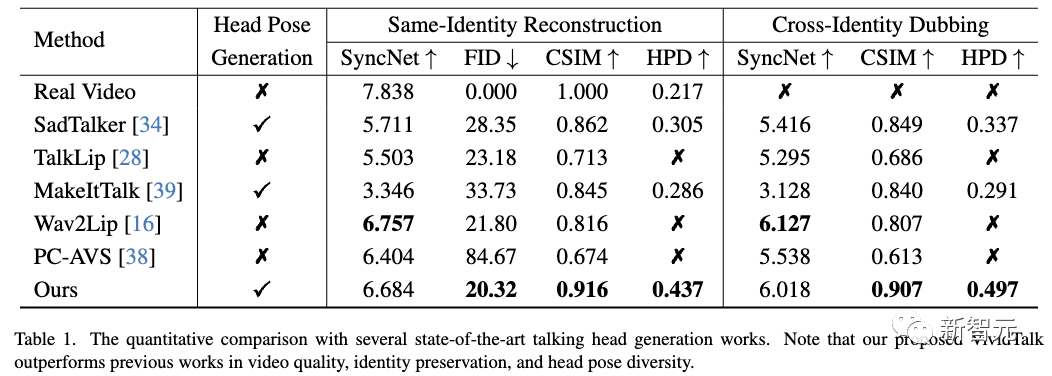
如下表所示,視覺結果和定量分析都證明了新方法在生成質量和模型泛化方面的優越性。
框架實現方法
給定音頻序列和參考面部圖像作為輸入,新方法可以生成具有不同面部表情和自然頭部姿勢的頭部說話視頻。
VividTalk框架由兩個階段組成,分別稱為音頻到網格生成和網格到視頻生成。
音頻到網格生成
這一階段的目標是根據輸入音頻序列和參考面部圖像生成3D驅動的網格。
具體來說,首先利用FaceVerse來重建參考面部圖像。
接下來,從音頻中學習非剛性面部表情運動和剛性頭部運動來驅動重建的網格。
為此,研究人員提出了多分支BlendShape和頂點偏移生成器以及可學習的頭部姿勢代碼本。
BlendShape和頂點偏移生成器
學習通用模型來生成準確的嘴部動作和具有特定人風格的富有表現力的面部表情在兩個方面具有挑戰性:
1)第一個挑戰是音頻運動相關性問題。由于音頻信號與嘴部運動最相關,因此很難根據音頻對非嘴部運動進行建模。
2)從音頻到面部表情動作的映射自然具有一對多的屬性,這意味著相同的音頻輸入可能有不止一種正確的動作模式,從而導致沒有個人特征的面部形象。
為了解決音頻運動相關性問題,研究人員使用blendshape和頂點偏移作為中間表征,其中blendshape提供全局粗粒度的面部表情運動,而與嘴唇相關的頂點偏移提供局部細粒度的嘴唇運動。
對于缺乏面部特征的問題,研究人員提出了一種基于多分支transformer的生成器來單獨建模每個部分的運動,并注入特定于主題的風格以保持個人特征。
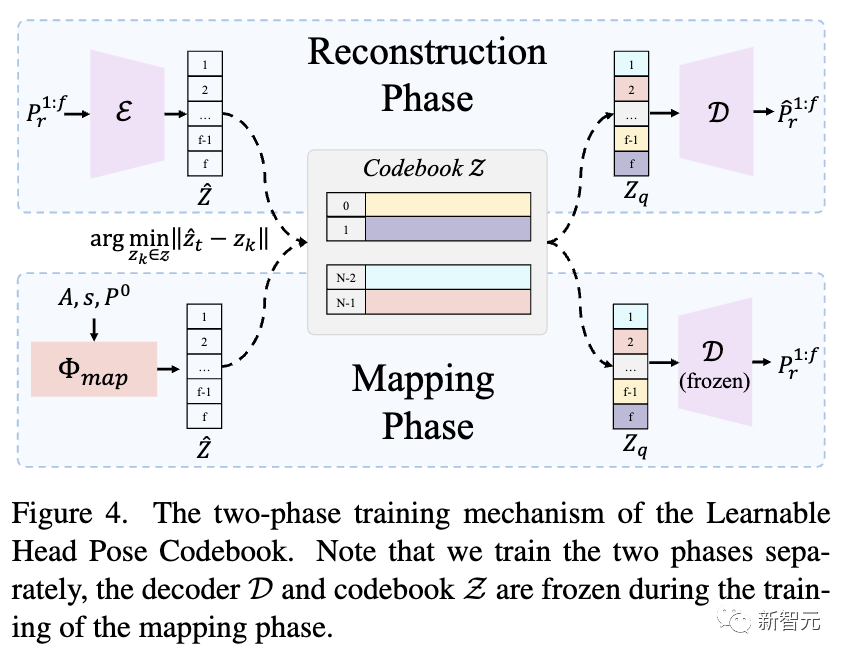
可學習的頭部姿勢密碼本
頭部姿勢是影響頭部說話視頻真實感的另一個重要因素。然而,直接從音頻中學習它并不容易,因為它們之間的關系很弱,這會導致不合理和不連續的結果。
受到之前研究的啟發,利用離散碼本作為先驗,即使在輸入降級的情況下也能保證高保真生成。
研究人員建議將此問題轉化為離散且有限頭部姿勢空間中的代碼查詢任務,并精心設計了兩階段訓練機制,第一階段構建豐富的頭部姿勢代碼本,第二階段將輸入音頻映射到碼本生成最終結果,如下圖所示。
網格到視頻生成
如下圖所示,研究人員提出了雙分支motionvae來對2D密集運動進行建模,該運動將作為生成器的輸入來合成最終視頻。
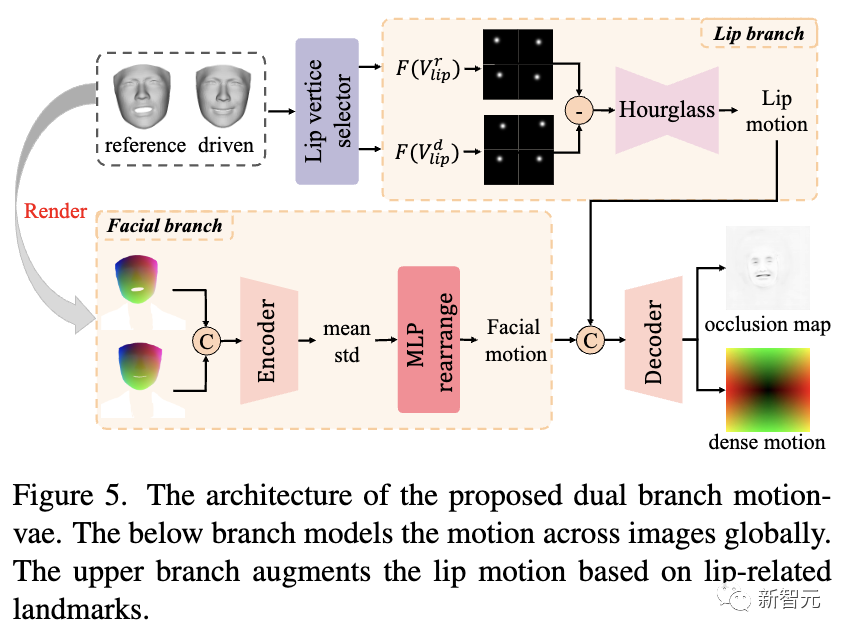
將3D域運動直接轉換為2D域運動既困難又低效,因為網絡需要尋找兩個域運動之間的對應關系以更好地建模。
為了提高網絡的性能并獲得進一步的性能,研究人員借助投影紋理表示在 2D 域中進行這種轉換。
如上圖所示,在面部分支中,參考投影紋理P T和驅動的投影紋理P Tare連接并饋入編碼器,然后輸入MLP,輸出2D面部運動圖。
為了進一步增強嘴唇運動并更準確地建模,研究人員還選擇與嘴唇相關的標志并將其轉換為高斯圖,這是一種更緊湊、更有效的表示。
然后,沙漏網絡將減去的高斯圖作為輸入并輸出 2D 嘴唇運動,該運動將與面部運動連接并解碼為密集運動和遮擋圖。
最后,研究人員根據之前預測的密集運動圖對參考圖像進行變形,獲得變形圖像,該變形圖像將與遮擋圖一起作為生成器的輸入,逐幀合成最終視頻。
實驗效果
數據集
HDTF是一個高分辨率視聽數據集,包含346個主題的超過16小時的視頻。VoxCeleb是另一個更大的數據集,涉及超過10萬個視頻和1000個身份。
研究人員首先過濾兩個數據集以刪除無效數據,例如音頻和視頻不同步的數據。
然后裁剪視頻中的人臉區域并將其大小調整為256×256。
最后,將處理后的視頻分為80%、10%、10%,這將用于用于培訓、驗證和測試。
實施細節
在實驗中,研究人員使用FaceVerse這種最先進的單圖像重建方法來恢復視頻并獲得用于監督的地面實況混合形狀和網格。
在訓練過程中,Audio-To-Mesh階段和Mesh-To-Video階段是分開訓練的。
具體來說,音頻到網格階段的BlendShape和頂點偏移生成器以及可學習頭部姿勢代碼本也分別進行訓練。
在推理過程中,研究人員的模型可以通過級聯上述兩個階段以端到端的方式工作。
對于優化,使用Adam優化器,兩個階段的學習率分別為1×10和1×10。在8個NVIDIA V100 GPU上的總訓練時間為2天。
與SOTA的比較

可以看到,研究人員提出的方法可以生成高質量的頭部說話視頻,具有精確的唇形同步和富有表現力的面部運動。
相比之下:
- SadTalker無法生成準確的細粒度嘴唇運動,并且視頻質量更低。
- TalkLip產生模糊結果,并將膚色風格改為略黃,在一定程度上丟失了身份信息。
- MakeItTalk無法生成準確的嘴形,尤其是在跨身份配音設置中。
- Wav2Lip傾向于合成模糊的嘴部區域,并在輸入單個參考圖像時輸出具有靜態頭部姿勢和眼球運動的視頻。
- PC-AVS需要驅動視頻作為輸入,并努力保存身份。
定量比較
如下表所示,新方法在圖像質量和身份保留方面表現更好,這通過較低的FID和較高的CSIM指標反映出來。
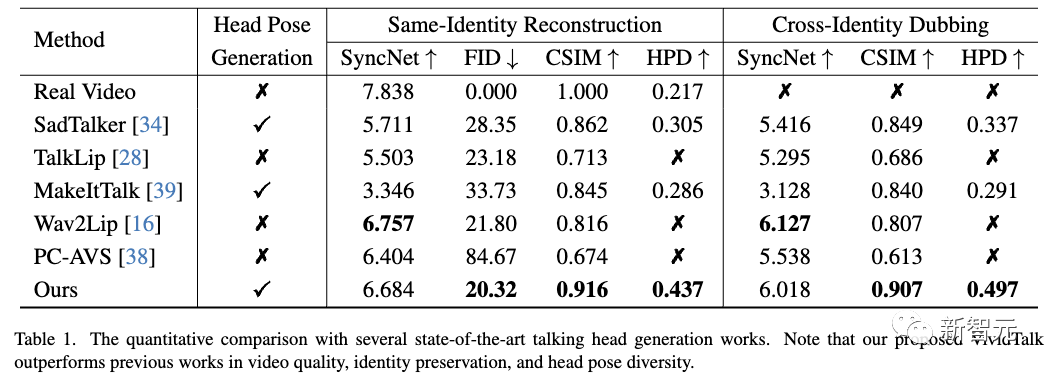
由于新穎的可學習密碼本機制,新方法生成的頭部姿勢也更加多樣化和自然。
雖然新方法的SyncNet分數低于Wav2Lip,但可以驅動使用單個音頻而不是視頻的參考圖像并生成更高質量的幀。























