













造假AI又進(jìn)化!只要一張照片,說話唱歌視頻自動(dòng)生成
本文經(jīng)AI新媒體量子位(公眾號(hào)ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請(qǐng)聯(lián)系出處。
曾造出無數(shù)“小視頻”、惡搞過多位明星的知名換臉神器Deepfakes,這下被降維打擊了。
這個(gè)新AI不再是篡改視頻了,而是直接把一張靜態(tài)的照片變成視頻。
像這樣,一張施瓦辛格:

開始說話了:

饒舌歌手Tupac Shakur:

也能張嘴了:

只要有一張靜態(tài)的人臉照片,甭管是誰,在這個(gè)新AI的驅(qū)動(dòng)下,任意配上一段語音,就能張嘴說出來。
當(dāng)然,除了說話之外,唱歌也毫無問題,比如讓生活在一百多年前的“俄羅斯妖僧”拉斯普京唱碧昂絲的Halo。
雖然聲音和性別不太匹配,但是畫面和歌曲組合起來有種莫名的鬼畜感呢。
你也別以為這個(gè)AI只能給照片對(duì)口型,它還可以讓這個(gè)說話的人擁有喜怒哀樂各種情緒。
開心的:

難過的:

炸毛的:

這眉眼,這目光,這臉部肌肉,得拯救多少“面癱”演員啊!
這項(xiàng)研究來自帝國(guó)理工學(xué)院和三星,研究者們還準(zhǔn)備了一套包含24個(gè)真假難辨的視頻的圖靈測(cè)試,我們簡(jiǎn)單測(cè)了一下,只能猜對(duì)一半左右。
也就是說,這些AI生成的“真假美猴王”,足以蒙騙人類了。
相比此前的斯坦福輸入任意文本改變視頻人物口型的研究,以及三星的說話換臉,實(shí)現(xiàn)難度可以說高了很多。
不少網(wǎng)友聞之色變:
現(xiàn)在是拉斯普京唱Halo,以后會(huì)不會(huì)整出川普向墨西哥選戰(zhàn)啊,感覺怕怕的。
連科技媒體The Verge都評(píng)價(jià)說:

這樣的研究總讓人們擔(dān)憂,怕它會(huì)被用在謠言和政治宣傳上,實(shí)在是讓美國(guó)立法者們傷腦筋。當(dāng)然,你也可以說這種在政治領(lǐng)域的威脅沒那么嚴(yán)重,但deepfakes已經(jīng)確確實(shí)實(shí)傷害了一些人,尤其是女性,在未經(jīng)同意的情況下被用來制造了又難堪又羞辱的色情視頻。
也有人覺得,等技術(shù)普及之后會(huì)給做壞事的人掩蓋的理由:
等這技術(shù)成熟了,川普真的干壞事的小視頻出來,他就可以輕描淡寫的說這是假視頻。
呵呵,真棒,以后壞人們被捏到把柄的時(shí)候,就都能說“沒有的事啦,是假視頻。”
多鑒別器結(jié)構(gòu)
如何用一張照片做出連貫視頻?研究人員認(rèn)為,這需要時(shí)序生成對(duì)抗網(wǎng)絡(luò)(Temporal GAN)來幫忙。
邏輯上不難理解,如果想讓生成的假視頻逼真,畫面上至少得有兩點(diǎn)因素必須滿足:
一是人臉圖像必須高質(zhì)量,二是需要配合談話內(nèi)容,協(xié)調(diào)嘴唇、眉毛等面部五官的位置。也不用動(dòng)用復(fù)雜的面部捕捉技術(shù),現(xiàn)在,只用機(jī)器學(xué)習(xí)的方法,就能自動(dòng)合成人臉。
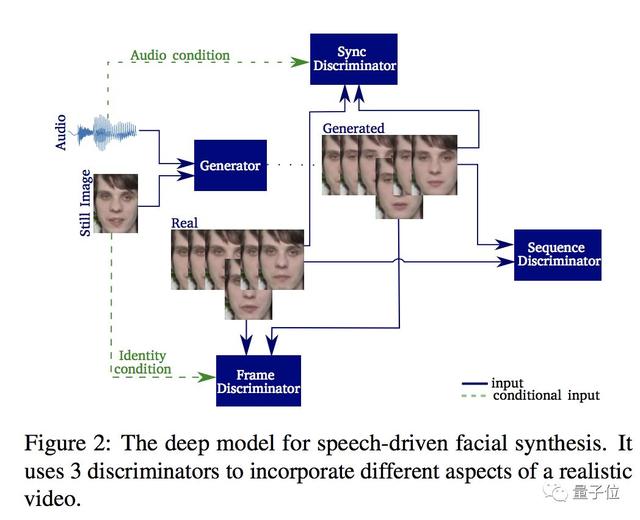
這中間的秘訣,就在于時(shí)序生成對(duì)抗網(wǎng)絡(luò),也就是Temporal GAN,此前在2018年提出過這個(gè)研究。
這是一個(gè)端對(duì)端的語音驅(qū)動(dòng)的面部動(dòng)畫合成模型,通過靜止圖像和一個(gè)語音生成人臉視頻。
在Temporal GAN中有兩個(gè)鑒別器,一個(gè)為幀鑒別器,確保生成的圖像清晰詳細(xì),另一個(gè)是序列鑒別器,負(fù)責(zé)響應(yīng)聽到的聲音并產(chǎn)生對(duì)應(yīng)的面部運(yùn)動(dòng),但效果并不那么優(yōu)異。

△ Temporal GAN模型示意圖
論文End-to-End Speech-Driven Facial Animation with Temporal GANs 地址:
https://arxiv.org/abs/1805.09313
在這項(xiàng)工作,研究人員借用這種時(shí)序生成對(duì)抗網(wǎng)絡(luò),使用兩個(gè)時(shí)間鑒別器,對(duì)生成的視頻進(jìn)行視聽對(duì)應(yīng),來生成逼真的面部動(dòng)作。
同時(shí)還鼓勵(lì)模型進(jìn)一步自發(fā)產(chǎn)生新的面部表情,比如眨眼等動(dòng)作。
所以,最新版基于語音的人臉合成模型來了。模型由時(shí)間生成器和3個(gè)鑒別器構(gòu)成,結(jié)構(gòu)如下:
這是一個(gè)井然有序的分工結(jié)構(gòu),生成器負(fù)責(zé)接收單個(gè)圖像和音頻信號(hào)作為輸入,并將其分割為0.2秒的重疊幀,每個(gè)音頻幀必須以視頻幀為中心。
這個(gè)生成器由內(nèi)容編碼器(Content Encoder),一個(gè)鑒別編碼器(Identity Encoder)、一個(gè)幀解碼器(Frame Decoder)和聲音解碼器(Noise Generator)組成,不同模塊組合成一個(gè)可嵌入模塊,通過解碼網(wǎng)絡(luò)轉(zhuǎn)換成幀。
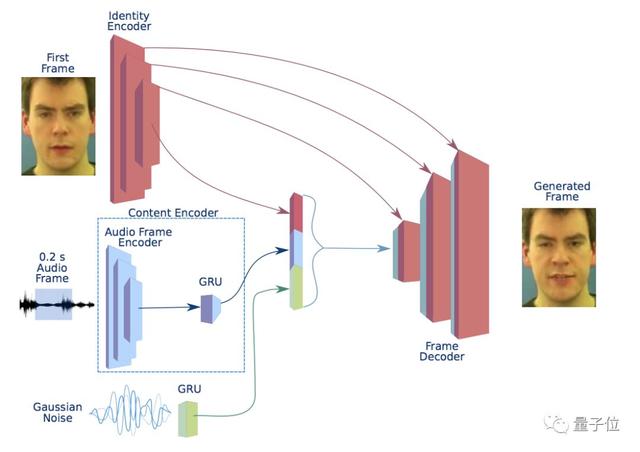
這個(gè)系統(tǒng)使用了多個(gè)鑒別器來捕捉自然視頻的不同方面,各部分各司其職。
幀鑒別器(Frame Discriminator)是一個(gè)6層的卷積神經(jīng)網(wǎng)絡(luò),來決定一幀為真還是假,同時(shí)實(shí)現(xiàn)對(duì)說話人面部的高質(zhì)量視頻重建。
序列鑒別器(Sequence Discriminator)確保各個(gè)幀能形成一個(gè)連貫的視頻,顯示自然運(yùn)動(dòng)。
同步鑒別器(Synchronization Discriminator)加強(qiáng)了對(duì)視聽同步的要求,決定畫面和音頻應(yīng)該如何同步。它使用了兩種編碼器獲取音頻和視頻的嵌入信息,并基于歐式距離給出判斷。
同步鑒別器的結(jié)構(gòu)如下:
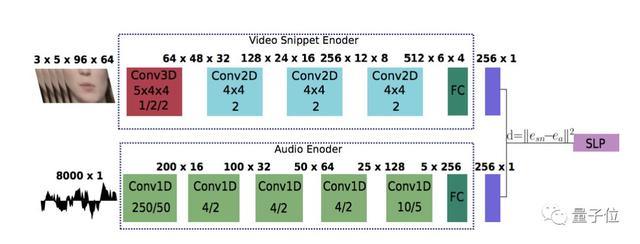
就是這樣,無需造價(jià)高昂的面部捕捉技術(shù),只需這樣一個(gè)網(wǎng)絡(luò),就能將一張照片+一段音頻組合成流暢連貫的視頻了。
30多篇CVPR的作者
這項(xiàng)研究共有三位作者,分別為Konstantinos Vougioukas、Stavros Petridis和Maja Pantic,均來自倫敦帝國(guó)學(xué)院iBUG小組,主攻智能行為理解,其中二作和三作也是英國(guó)三星AI中心的員工。

一作Konstantinos Vougioukas2011年在佩特雷大學(xué)獲得電氣與計(jì)算機(jī)工程專業(yè)的本科學(xué)位后,奔赴愛丁堡大學(xué)攻讀人工智能方向的碩士學(xué)位。
現(xiàn)在,Konstantinos Vougioukas在倫敦帝國(guó)學(xué)院的Maja Pantic教授(本文三作)的指導(dǎo)下攻讀博士,主要研究方向?yàn)槿祟愋袨楹铣珊兔娌啃袨楹铣伞?/p>
Maja Pantic教授是iBUG小組的負(fù)責(zé)人,也是劍橋三星AI中心的研究主任,她在面部表情分析、人體姿態(tài)分析、情緒和社會(huì)信號(hào)是挺分析等方面發(fā)表過超過250篇論文,引用次數(shù)超過25000次。
從2005年開始,Maja Pantic帶學(xué)生發(fā)了30多篇CVPR(包含workshop)論文。
Maja Pantic教授主頁:
https://ibug.doc.ic.ac.uk/people/mpantic
傳送門
論文Realistic Speech-Driven Facial Animation with GANs地址:
https://arxiv.org/abs/1906.06337
項(xiàng)目主頁:
https://sites.google.com/view/facial-animation
GitHub:
https://github.com/DinoMan/speech-driven-animation
























