LLM準確率飆升27%!谷歌DeepMind提出全新「后退一步」提示技術
前段時間,谷歌DeepMind提出了一種全新的「Step-Back Prompting」方法,直接讓prompt技術變得腦洞大開。
簡單來說,就是讓大語言模型自己把問題抽象化,得到一個更高維度的概念或者原理,再把抽象出來的知識當作工具,推理并得出問題的答案。

論文地址:https://arxiv.org/abs/2310.06117
結果也是非常不錯的,在他們用PaLM-2L模型做了實驗,證明這種新型的Prompt技巧對某些任務和問題的處理表現極佳。
比方說,MMLU物理和化學方面的性能提高了7%,TimeQA提高了27%,MuSiQue則提高了7%。
其中MMLU是大規模多任務語言理解測試數據集,TimeOA是時間敏感問題測試數據集,MusiQue則是多跳問答數據集,包含25000個2至4跳的問題。
其中,多跳問題指的是,需要使用多個三元組所形成的多跳推理路徑才能夠回答的問題。
下面,讓我們來看看這項技術是如何實現的。
后退!
看完開頭的介紹,可能讀者朋友還沒太理解。什么叫讓LLM自己把問題抽象化,得到一個更高維度的概念或者原理呢。
我們拿一個具體的實例來講。
比方說,假如用戶想問的問題和物理學中的「力」相關,那么LLM在回答此類問題時,就可以后退到有關力的基礎定義和原理的層面,作為進一步推理出答案的根據。
基于這個思路,用戶在一開始輸入prompt的時候,大概就是這樣:
你現在是世界知識的專家,擅長用后退的提問策略,一步步仔細思考并回答問題。
后退提問是一種思考策略,為的是從一個更宏觀、更基礎的角度去理解和分析一個特定問題或情境。從而更好地回答原始問題。
當然,上面舉的那個物理學的例子只體現了一種情況。有些問題下,后退策略可能會讓LLM嘗試識別問題的范圍和上下文。有的問題后退的多一點,有的少一些。
論文
首先,研究人員指出,自然語言處理(NLP)領域因為有了基于Transformer的LLM而迎來了一場突破性的變革。
模型規模的擴大和預訓練語料庫的增加,帶來了模型能力和采樣效率的顯著提高,同時也帶來了多步推理和指令遵循等新興能力。
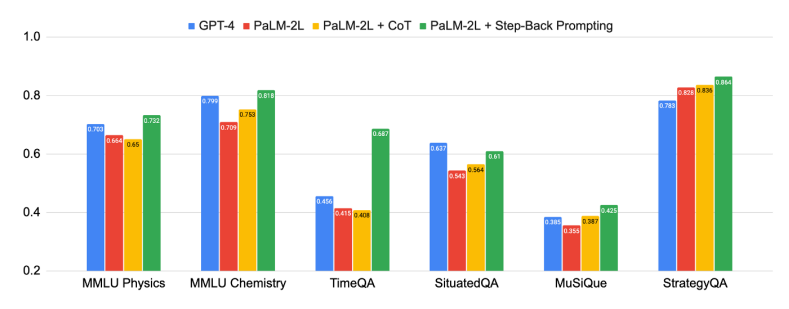
上圖顯示了后退推理的強大性能,本篇論文中所提出的「抽象-推理」法,在科學、技術、工程與數學和多跳推理等需要復雜推理的各種高難度任務中取得了重大改進。
有些任務非常具有挑戰性,一開始,PaLM-2L和GPT-4在TimeQA和MuSiQue上的準確率僅為40%。而在應用了后退推理以后,PaLM-2L的性能全線提高。在MMLU物理和化學任務中分別提高了7%和11%,在TimeQA任務中提高了27%,在MuSiQue任務中提高了7%。
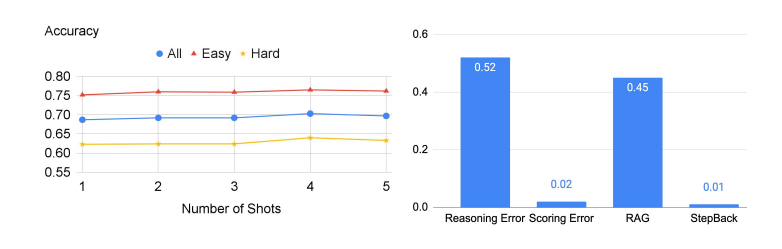
不僅如此,研究人員還進行了錯誤分析,他們發現大部分應用后退推理時出現的錯誤,都是由于LLMs推理能力的內在局限性造成的,與新的prompt技術無關。
而抽象能力又是LLMs比較容易學會的,所以這為后退推理的進一步發展指明了方向。。
雖說確實取得了不小進步,但復雜的多步驟推理還是很有挑戰性的。即使對最先進的LLMs來說也是如此。
論文表明,具有逐步驗證功能的過程監督是提高中間推理步驟正確性的一種有效補救方法。
他們引入了思維鏈(Chain-of-Thought)提示等技術,以產生一系列連貫的中間推理步驟,從而提高了遵循正確解碼路徑的成功率。
而談到這種promp技術的起源時,研究者指出,人類在面對具有挑戰性的任務時,往往會退一步進行抽象,從而得出高層次的概念和原則來指導推理過程,受此啟發,研究人員才提出了后退的prompt技術,將推理建立在抽象概念的基礎上,從而降低在中間推理步驟中出錯的幾率。
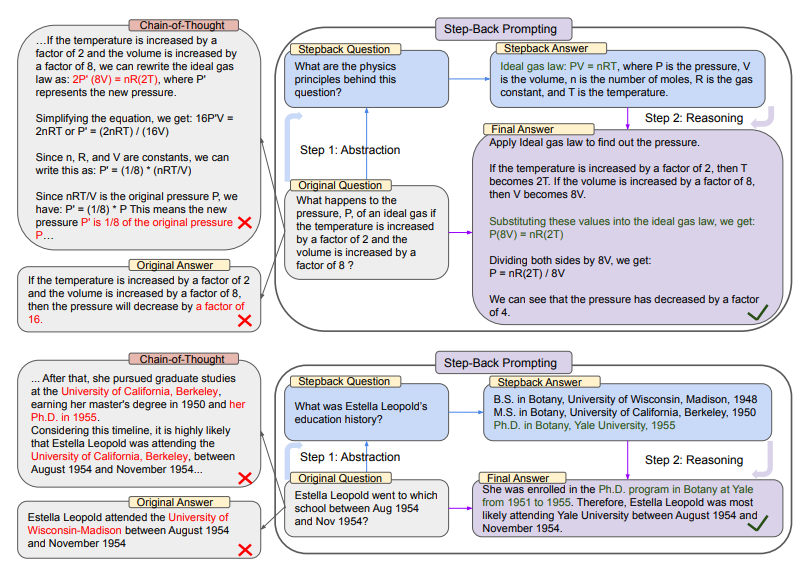
上圖的上半部分中,以MMLU的高中物理為例,通過后退抽象,LLM得到理想氣體定律的第一條原理。
而在下半部分中,是來自TimeQA的示例,教育史這一高層次概念是依照這種策略,LLM抽象出來的結果。
從整張圖的左邊我們可以看到,PaLM-2L未能成功回答原始問題。思維鏈提示在中間推理步驟中,LLM出現了錯誤(紅色高亮部分)。
而右邊,應用了后退prompt技術的PaLM-2L則成功回答了問題。
在眾多認知技能中,抽象思考對于人類處理大量信息并推導出一般規則和原理的能力來說無處不在。
隨便舉幾個例子,開普勒將成千上萬的測量結果凝練成開普勒行星運動三定律,精確地描述了行星圍繞太陽的軌道。
又或者,在關鍵決策制定中,人類也發現抽象是有幫助的,因為它提供了一個更廣闊的環境視角。
而LLM是如何通過抽象和推理兩步法來處理涉及許多低級細節的復雜任務,則是本篇論文的重點。
第一步就是教會LLMs退一步這個思路,讓它們從具體實例中推導出高級、抽象的概念,如某領域內的基礎概念和第一原理。
第二步則是利用推理能力,將解決方案建立在高級概念和第一原理的基礎上。
研究人員在LLM上使用了少量的示例演示來執行后退推理這一技術。他們在一系列涉及特定領域推理、需要事實知識的知識密集型問題解答、多跳常識推理的任務中進行了實驗。
結果表明,PaLM-2L的性能有了明顯提高(高達27%),這證明了后退推理在處理復雜任務方面的性能十分顯著。
在實驗環節,研究人員對以下不同種類的任務進行了實驗:
(1)STEM
(2)知識QA
(3)多跳推理
研究人員評估了在STEM任務中的應用,以衡量新方法在高度專業化領域中的推理效果。(本文中僅以此類問題進行講解)
顯然,在MMLU基準中的問題,需要LLM進行更深層次的推理。此外,它們還要求理解和應用公式,而這些公式往往是物理和化學原理和概念。
在這種情況下,研究人員首先要教會模型以概念和第一原理的形式進行抽象,如牛頓第一運動定律、多普勒效應和吉布斯自由能等。這里隱含的退一步問題是「解決這項任務所涉及的物理或化學原理和概念是什么?」
團隊提供了示范,教導模型從自身知識中背誦解決任務的相關原理。
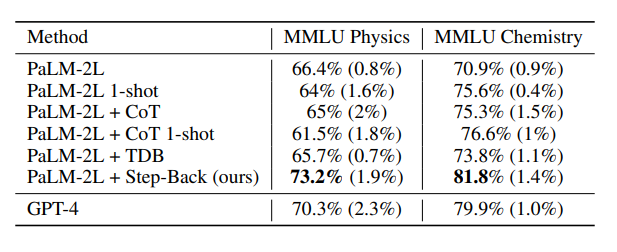
上表中就是應用了后退推理技術的模型性能,應用了新技術的LLM在STEM任務中表現出色,達到了超越GPT-4的最先進水平。
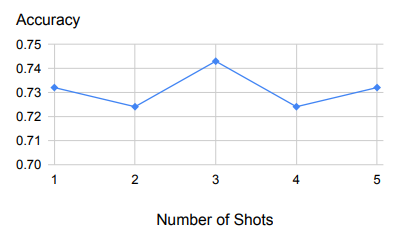
上表是針對少數幾個樣本的示例,展示了樣本數量變化時的穩健性能。
首先,從上圖中我們可以看出,后退推理對用作示范的少量示例具有很強的魯棒性。
除了一個示例之外,增加更多的示例結果也還會是這樣。
這表明,檢索相關原理和概念的任務相對來說比較容易學習,一個示范例子就足夠了。
當然,在實驗過程中,還是會出現一些問題。
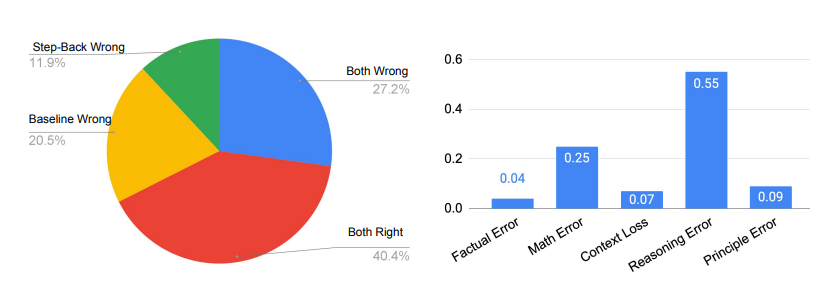
其中除原則錯誤外,所有論文中出現的五類錯誤都發生在LLM的推理步驟中,而原則錯誤則表明抽象步驟的失敗。
如下圖右側所示,原則錯誤實際上只占模型錯誤的一小部分,90%以上的錯誤發生在推理步驟。在推理過程中的四種錯誤類型中,推理錯誤和數學錯誤是主要的失誤所在地。
這與消融研究中的發現相吻合,即只需要很少的示例就能教會LLM如何進行抽象。推理步驟仍然是后退推理能否很好地完成MMLU等需要復雜推理的任務的瓶頸。
特別是對于MMLU物理來說,更是如此,推理和數學技能是成功解決問題的關鍵。意思就是說,哪怕LLM正確地檢索了第一原理,也還是得通過典型的多步驟推理過程得出正確的最終答案,也就是還需要LLM有深入的推理和數學能力。
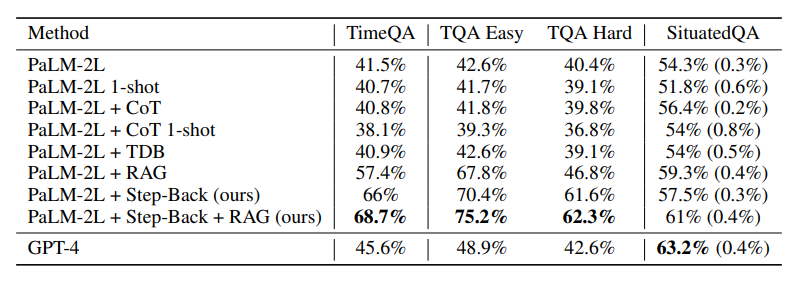
之后,研究人員在TimeQA的測試集上對模型進行了評估。
如下圖所示,GPT-4和PaLM-2L的基線模型分別達到了45.6%和41.5%,凸顯了任務的難度。
在基線模型上應用CoT或TDB零次(和一次),prompt沒有任何改進。
相比之下,通過常規檢索增強(RAG)對基線模型進行增強后,準確率提高到了57.4%,凸顯了任務的事實密集性。
Step-Back + RAG的結果顯示了后退推理中,LLM回到高級概念這一步是很有效的,這會讓LLM的檢索環節更為可靠,我們可以看到,TimeQA的準確率達到了驚人的68.7%。
接下來,研究人員又將TimeQA分成了原始數據集中提供的簡單和困難兩個難度級別。
不出意外的是,LLM在困難這個級別上的表現都較差。雖然RAG可以將簡單級的準確率從42.6%提高到67.8%,但對困難級準確率的提高幅度要小得多,數據顯示僅從40.4%增加到了46.8%。
而這也正是后退推理的prompt技術的真正優勢所在,它能檢索到高層次概念的相關事實,為最終推理奠定基礎。
后退推理再加RAG,就能進一步將準確率提高到62.3%,超過了GPT-4的42.6%。
當然,在TimeQA類問題上,這項prompt技術還是存在一些問題的。
下圖就顯示了在這部分實驗中LLM的準確性,右側則是錯誤發生的概率。