不用LLM,遺傳編程可控Python代碼!谷歌DeepMind等提出全新ARZ框架
谷歌等團隊發布了遺傳編程最新成果——AutoRobotics-Zero(ARZ)。最新論文已被IROS 2023接收。

論文地址:https://arxiv.org/pdf/2307.16890.pdf
這是一種使用AutoML-Zero的搜索方法,能夠構建緊湊、可解釋的機器人策略,可以快速適應環境的劇烈變化。
即使在隨機選擇的一條腿折斷后,ARZ策略能夠控制步態,讓其繼續行走。

而這一挑戰任務,在2個流行的神經網絡基線MLP+LSTM中,取得了失敗結果。
甚至,ARZ使用的參數和FLOPS比基線少得多。

英偉達高級研究科學家Jim Fan表示,令人耳目一新的機器人技術!無需LLM,甚至無需神經網絡:只需使用進化搜索控制機器人的Python代碼。可解釋,并且自適應。

全新ARZ框架
現實世界中的機器人,面臨著不同類型的挑戰,比如物理磨損、地形障礙等等。
如果僅是依靠將相同狀態映射到,相同動作的靜態控制器,只能暫且逃過這一劫。
但不能將萬事萬物都映射出來,而需要機器人能夠根據不同變化的環境,來持續調整控制策略。
要實現這種能力,它們必須在沒有外部提示的情況下,通過觀察行動如何隨時間改變系統狀態,來識別環境變化,并更新其控制以做出響應。
當前,遞歸深度神經網絡是支持快速適應的常用策略表示法。然而,它的問題在于,單一,參數過高,難以解釋。
由此,谷歌等研究人員提出了基于AMLZ的AutoRobotics-Zero (ARZ)方法,以支持四足機器人適應任務中動態、自我修正的控制策略進化。
研究人員將這些策略表示為程序,而非神經網絡。
他們演示了如何從零開始,僅使用基本數學運算作為構建模塊,進化出適應性策略及其初始參數。

自動發現Python代碼,代表四足機器人模擬器的可適應策略
演化可以發現控制程序,這些程序在與環境交互的過程中,利用其感官-運動經驗來微調其策略參數或即時改變其控制邏輯。
這就實現了在不斷變化的環境條件下,保持接近最佳性能所需的自適應行為。
與AMLZ不同,研究人員為Laikago機器人設計了模擬器,在倒立擺任務(Cataclysmic Cartpole)中取得良好性能。為此,團隊還放棄了AMLZ的監督學習范式。
研究表明,進化程序可以在其生命周期內進行自適應,而無需明確接收任何監督輸入,比如獎勵信號。
此外,AMLZ依靠的是人為應用三個已發現的函數,而ARZ允許進化程序中使用的函數數量,由進化過程本身決定。
為此,研究人員使用了條件自動定義函數(CADF),并展示了其影響。
通過這種方法,發現進化的適應性策略比先進解決方案要簡單得多,因為進化搜索從最小的程序開始,并通過與任務領域的交互逐步增加復雜性。
因此,它們的行為具有很高的可解釋性。
在四足機器人中,即使隨機選擇的一條腿上的所有電機都無法產生任何扭矩,ARZ也能進化出適應性策略,保持向前運動并避免摔倒。
相比之下,盡管進行了全面的超參數調整,并采用了最先進的強化學習方法進行訓練,但MLP和LSTM基線仍無法在這種具有挑戰性的條件下學習到穩健的行為。
由于模擬真實機器人卻非常耗時,自適應控制缺乏高效且具有挑戰性的基準,研究人員還創建了一個簡易自適應任務,名為「倒立擺」。
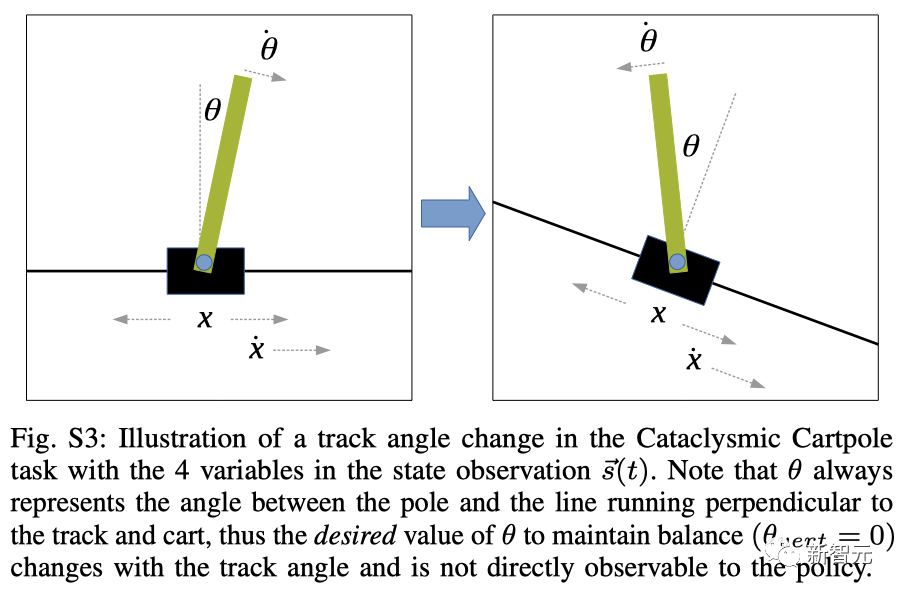
倒立擺任務中軌道角度變化的示意圖
總而言之,本論文開發了一種進化方法,用于從零開始自動發現適應性機器人策略。在每個任務中,得到的策略具有以下特點:
? 超越經過精心訓練的MLP和LSTM基線;
? 表示為可解釋的、符號化的程序;
? 使用的參數和操作比基線更少。
2種搜索算法:自然選擇第一性原理
算法由兩個核心函數組成:StartEpisode() 和 GetAction()。
StartEpisode() 會在與環境交互的每episode開始時運行一次。它的唯一目的是用進化常量初始化虛擬內存的內容。
這些內存在任何時間的內容,都可以被描述為控制程序的狀態。研究人員的目標是發現,能夠在與環境交互的同時,通過調整內存狀態,或改變控制代碼來適應環境的算法。
而這種適應性以及算法的決策策略,由 GetAction() 函數實現,其中每條指令都執行一個操作,比如「0=s7*s1 or s3=v1[i2]」。
同時,研究人員定義了一個更大的操作庫,對程序的復雜度不設限制。
進化搜索被用來發現 GetAction() 函數中出現的操作序列和相關內存地址。
論文中,采用了2種進化算法:(a) 多目標搜索采用NSGA-II,(b) 單目標搜索采用RegEvo.
這兩種搜索算法都,采用了達爾文自然選擇原理的算法模型,對候選控制程序群體進行迭代更新。
進化搜索的一般步驟如下:
1. 初始化一組隨機控制程序
2. 評估任務中的每個程序

進化控制算法的評估過程:單目標進化搜索采用均值episode獎勵作為算法的適應度,而多目標搜索優化了兩個適應度指標:均值獎勵(第一個返回值),每個episode的均值步長(第二個返回值)
3. 使用特定任務的適應度指標選擇有前途的程序
4. 通過交叉和變異改變選定的個體

算法群的簡化示例,通過交叉和變異產生新的算法群體
5. 在群(population)中加入新的項目,取代一定比例的現有個體
6. 返回第二步
就本研究而言,NSGA-II和RegEvo之間的最大區別在于它們的選擇方法。
NSGA-II使用多種適應性指標,比如前向運動和穩定性,來識別有潛力的個體。
而RegEvo則根據單一指標(前向運動)進行選擇。
兩種搜索方法同時演化:(1) 初始算法參數(即浮點存儲器中的初始值sX、vX、mX),由 StartEpisode() 設置;(2) GetAction() 函數和CADF的程序內容。
測試環境
研究人員考慮在兩種不同的環境中來測試ARZ:一個是四足機器人真實模擬器,另一個是全新倒立擺。
在這兩種情況下,ARZ策略必須處理過渡函數的變化,這通常會阻礙它們的正常功能。
這些變化可能是突然的,也可能是漸進的,而且沒有傳感器輸入來指示何時發生變化或環境如何變化。
結果
斷腿
與ARS+MLP和ARS+LSTM基線相比,ARZ(包括CADF)是唯一一個在四足機器人腿部折斷的任務中,生成了可行控制策略的方法。
實際上,這個問題非常困難,因為找到一種能夠保持平穩運動且對腿部折斷具有魯棒性的策略,需要重復20次進化實驗。

CADF 加快了進化速度,并產生了最佳的結果
從5個測試場景的軌跡可視化中可以發現,ARZ策略是唯一一個能夠在所有情況下避免摔倒的控制器,盡管在前左腿折斷的情況下,維持前行會有些困難。

ARZ發現了唯一能夠適應任何斷腿情況的策略
相比之下,MLP策略在右后腿折斷的情況下可以繼續前行,但在其他動態任務中都會摔倒。而LSTM策略只能在所有腿都完好的靜止任務中避免摔倒。
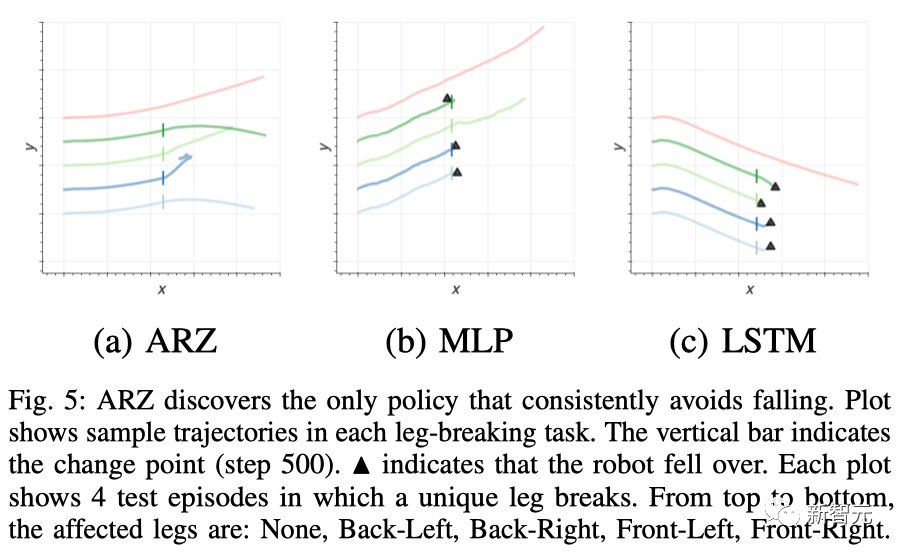
ARZ發現了唯一能持續避免摔倒的策略
簡潔性和可解釋性
研究人員提出的進化算法只用了608個參數和40行代碼,每步最多執行2080個浮點運算(FLOPs)。
這與基線MLP/LSTM模型在每一步中使用的超過2.5k/9k個參數和5k/18k個FLOPs相比顯得更為簡潔。
從下圖中可以看到,ARZ策略能夠快速識別和適應多種獨特的故障條件。
比如,當一條腿折斷時,控制器的行為會瞬時發生改變,而該策略能夠在發生變化時迅速做出調整。

當左前腿在途中折斷時,ARZ策略發生的變化
倒立擺
在倒立擺中,研究人員證實ARZ與ARS+LSTM基線相比,在突然、劇烈變化的任務中能產生更好的控制效果。
如下,ARZ和LSTM都解決了適應任務,并且沒有觀察到從靜態任務到動態任務的直接轉移。
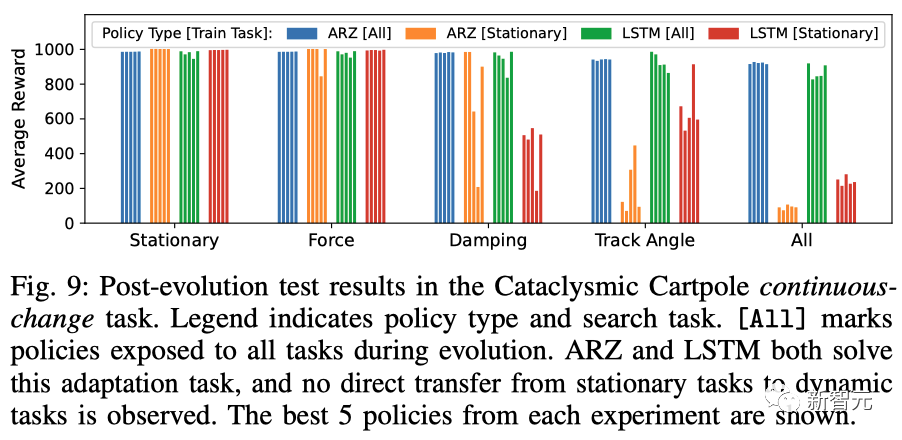
倒立擺連續變化任務的進化后測試結果
另外,在突變任務中,ARZ發現了唯一適用于所有突變的倒立擺任務的策略。
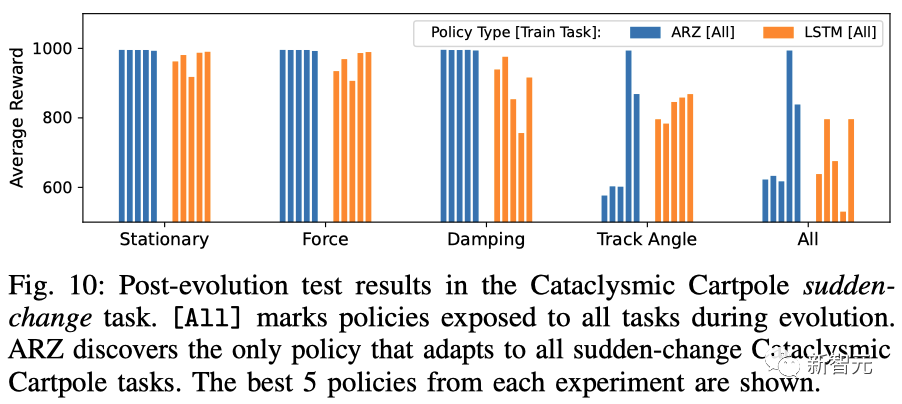
倒立擺突變任務的進化后測試結果
簡單性和可解釋性
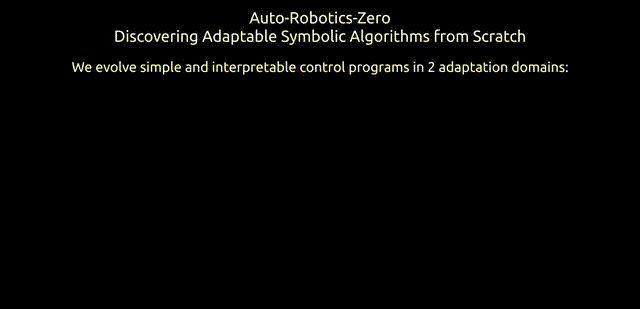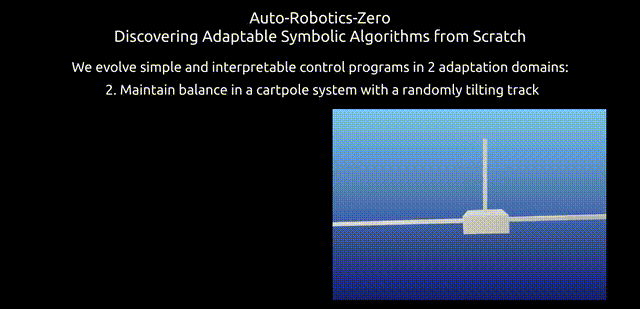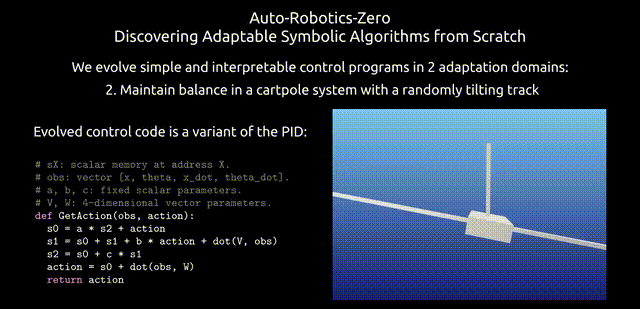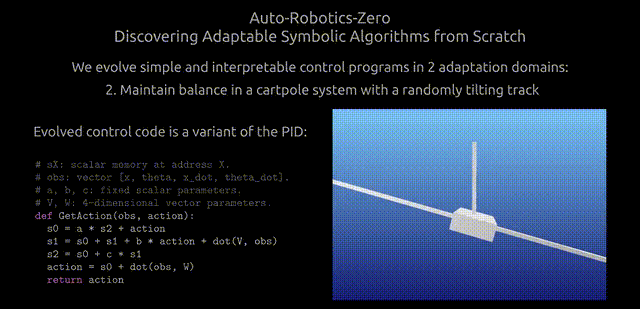
在這里,研究人員對ARZ策略進行分解,以詳細解釋它是如何在不斷變化的環境中,整合狀態觀測結果來計算最優行動的。
下圖,展示了ARZ設置中發現的算法示例。
值得注意的是,解決這項任務并不需要CADF,因此為了簡化程序分析,搜索空間中省略了CADF。
研究人員發現的是三個累加器,它們收集了觀察值和行動值的歷史記錄,從中可以推斷出當前的行動。

在所有參數都不斷變化的任務上,演化出有狀態動作函數示例
該算法使用11個變量,每步執行25 FLOPs。
與此同時,MLP和LSTM算法分別使用了超過1k和 4.5k參數,每步分別耗費超過2k和9k FLOPs
討論
使用ARZ在程序空間和參數空間中同時搜索,可以產生熟練、簡單和可解釋的控制算法。
這些算法可以進行零樣本適應,也就是在環境發生根本性變化時迅速改變其行為,從而保持接近最優的控制能力。
· CADF和分心困境
在四足機器人領域,在搜索空間中包括有條件地調用自動定義函數(CADF)可以提高進化控制算法的表現能力。
在單個最佳策略中,CADF被用于將觀測空間分成四個狀態。然后,行動完全由系統的內部狀態和這個離散化的觀測決定。其中,離散化有助于策略去定義一種切換行為,從而克服分心困境。
相比之下,僅在人工設計的MLP或LSTM網絡的參數空間中進行搜索,并不能產生能夠適應多個變化事件的策略(例如,單條腿折斷)。
· 適應未見任務動態
那么問題來了,在不知道未來可能會發生什么樣的環境變化時,應該如何構建自適應控制策略?
在倒立擺任務中,ARZ的初步結果表明,在進化(訓練)過程中注入部分可觀測性和動態執行器噪聲,可以作為非穩態任務動態的一般替代。
如果這個結論得到進一步證明,也就意味著我們能夠在完全不了解任務環境動態的情況下,進化出熟練的控制策略,從而減輕對準確物理模擬器的需求。