ChatGPT 使用到的機器學習技術
作者 | Bright Liao
在《程序員眼中的 ChatGPT》一文中,我們聊到了開發(fā)人員對于ChatGPT的認知。本文來聊一聊ChatGPT用到的機器學習技術。

機器學習技術的發(fā)展
要聊ChatGPT用到的機器學習技術,我們不得不回顧一下機器學習技術的發(fā)展。因為,ChatGPT用到的技術不是完全從零的發(fā)明,它也是站在巨人的肩膀上發(fā)展起來的。
1.機器學習技術的分類
實際上機器學習技術可以追溯到上個世紀三四十年代,一開始就與統(tǒng)計學分不開。早在1936年,著名的統(tǒng)計學家Fisher發(fā)明了線性判別分析方法(LDA)。LDA利用方差分析的思想,試圖將高維數(shù)據(jù)分開。這后來演化為一類基礎的機器學習技術要解決的問題,即分類問題。
在計算機出現(xiàn)之后,大量的基于計算機的機器學習算法出現(xiàn),比如決策樹、SVM、隨機森林、樸素貝葉斯、邏輯回歸等。它們也都可以用于解決分類問題。
分類問題是指我們事先知道要分為哪幾類,這些類通常是人為定義的。比如人分為男性和女性,編程語言分為C/C++/Java等。
還有一類問題是我們無法預先知道要分為幾類的,比如給定一系列的新聞,按照主題進行分組,而我們可能無法事先人為確定有幾個主題。此時可以利用機器學習算法自動去發(fā)現(xiàn)新聞中有幾個類,然后再把不同的新聞放到不同的分類。這種問題是聚類問題。
有時,這個分類可能是連續(xù)的,比如,我們要用一個機器學習模型去預測某個人的身高,此時可以認為結果是在某一個范圍內(nèi)連續(xù)變化的值。這類問題,我們把它叫做回歸問題。與分類的問題的區(qū)別僅僅在于我們希望輸出一個連續(xù)的值。
除此之外,一些典型的機器學習問題還包括:降維、強化學習(通過智能體與環(huán)境的交互來學習最佳行動策略)等。
除了根據(jù)問題不同進行分類,還可以從機器學習技術使用數(shù)據(jù)的方式進行分類。從這個角度可以將機器學習技術分為有監(jiān)督學習、無監(jiān)督學習、半監(jiān)督學習等。有監(jiān)督學習要求我們?yōu)槟P蜏蕚浜脴撕炛怠o監(jiān)督學習則無需我們準備標簽值,只需數(shù)據(jù)即可開始訓練。半監(jiān)督學習是指需要一部分有標簽值的數(shù)據(jù)。
從解決的問題上來看,ChatGPT可以認為是一個分類模型,它根據(jù)輸入的文本預測下一個要輸出的詞是什么,而詞的范圍是確定的,即模型的輸出是一個確定的分類。
從ChatGPT使用數(shù)據(jù)的方式來看,可以認為是使用了大量的無監(jiān)督數(shù)據(jù),加上少量的有監(jiān)督的數(shù)據(jù)。所以,可以認為ChatGPT是一個半監(jiān)督的機器學習技術。
2.傳統(tǒng)的機器學習算法與基于人工神經(jīng)網(wǎng)絡的機器學習算法
上面提到的決策樹、SVM、隨機森林、樸素貝葉斯、邏輯回歸等算法,多是基于可驗證的可理解的統(tǒng)計學知識設計的算法。它們的局限性主要在于效果比較有限,即便使用海量數(shù)據(jù)也無法繼續(xù)提升,這要歸因于這些模型都是相對簡單的模型。由于這些算法都是很早就被開發(fā)出來了,并且一直很穩(wěn)定,沒有什么更新,我們一般稱這些算法為傳統(tǒng)的機器學習算法。
另一類機器學習算法是基于人工神經(jīng)網(wǎng)絡的機器學習算法。這一類算法試圖模擬人類的神經(jīng)網(wǎng)絡結構。其起源也很早,要追溯到1943年,W. S. McCulloch和W. Pitts提出的M-P模型。該模型根據(jù)生物神經(jīng)元的結構和工作機理構造了一個簡化的數(shù)學模型,如下圖。
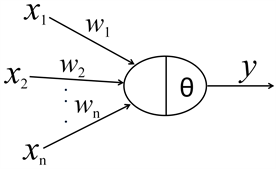
其中,xi代表神經(jīng)元的第i個輸入,權值wi為輸入xi對神經(jīng)元不同突觸強度的表征,θ代表神經(jīng)元的興奮閥值,y表示神經(jīng)元的輸出,其值的正和負,分別代表神經(jīng)元的興奮和抑制。
該模型的數(shù)學公式可以表示為:??=∑????*??????? ,如果所有輸入之和大于閥值θ則y值為正,神經(jīng)元激活,否則神經(jīng)元抑制。該模型作為人工神經(jīng)網(wǎng)絡研究的最簡模型,一直沿用至今。
雖然這個模型看起來很簡單,但是由于其可擴展可堆疊的特性,實際上可以用于構造一個非常復雜的網(wǎng)絡。至于如何擴展和堆疊,其實就是人工神經(jīng)網(wǎng)絡數(shù)十年的發(fā)展要解決的問題。
這個模型如何優(yōu)化呢?這里的優(yōu)化其實就是修改wi的值,依靠一種名為反向傳播的優(yōu)化方式可以優(yōu)化它。其計算過程,相當于對wi求偏導數(shù),然后和學習率相乘再加回到原來的wi值上。
人工神經(jīng)網(wǎng)絡模型的算法思想非常簡單,其效果只有在網(wǎng)絡規(guī)模達到一定程度之后才會體現(xiàn)出來。但是一旦網(wǎng)絡形成規(guī)模之后,對算力和數(shù)據(jù)的要求就非常高了。這也是為什么在21世紀之前這樣的算法無法獲得發(fā)展的原因。
從2000年開始,互聯(lián)網(wǎng)進入了爆發(fā)式發(fā)展的階段,大量的數(shù)據(jù)被累積起來,并且計算機算力也經(jīng)歷了數(shù)十個摩爾周期得到了長足的發(fā)展。于是基于人工神經(jīng)網(wǎng)絡的機器學習算法得到爆發(fā)式的發(fā)展。
各個研究領域都紛紛開始嘗試利用人工神經(jīng)網(wǎng)絡來提升機器學習模型效果。
卷積神經(jīng)網(wǎng)絡(一種基于M-P模型的變種結構)在計算機視覺領域表現(xiàn)突出,逐漸演變?yōu)橛嬎銠C視覺領域的基礎結構。循環(huán)神經(jīng)網(wǎng)絡和長短期記憶網(wǎng)絡(另一種基于M-P模型的變種結構)在自然語言處理領域表現(xiàn)突出,逐漸演變?yōu)樽匀徽Z言處理領域的基礎結構。
這兩類網(wǎng)絡結構曾經(jīng)風靡一時,即便到現(xiàn)在也有很多問題是基于這兩類結構的網(wǎng)絡算法去解決的。它們在很大程度上促進了人工神經(jīng)網(wǎng)絡的機器學習算法的發(fā)展。
但是,研究人員從未停止對于網(wǎng)絡結構的探索。在2017年的時候,Google的研究團隊提出了一個名為Transformer的網(wǎng)絡結構,強調(diào)了注意力機制在網(wǎng)絡結構中的表示和應用。Transformer模型結構簡單而一致,卻表現(xiàn)出了非常好的效果。
ChatGPT的故事可以認為從這里開始了。在Transformer模型結構發(fā)布之后,后續(xù)有大量的研究基于Transformer開展起來,都取得了很好的效果,這里面就包括各類GPT模型。
最初的Transformer模型主要是應用在自然語言處理領域。近兩年的研究發(fā)現(xiàn),這一結構也可以被用到計算機視覺認為上,當前流行的Vision Transformer模型就是它在計算機視覺領域的應用成果。從這個趨勢來看,Transformer有著要統(tǒng)一所有模型結構的勢頭。
ChatGPT技術概覽
有了前面的了解,終于輪到ChatGPT出場了。
ChatGPT用到了哪些技術呢?可以簡要列舉如下:
- 基礎模型結構:基于注意力機制的Transformer模型
- 超大規(guī)模的模型堆疊:GPT3堆疊了96層網(wǎng)絡,參數(shù)數(shù)量高達1750億
- 超大的訓練數(shù)據(jù):采用了45TB的原始數(shù)據(jù)進行訓練
- 超大的計算資源:基于微軟專門設計的包含數(shù)千塊GPU的超級計算機完成訓練
- 大規(guī)模并行訓練:將模型分布到多個實例,多塊GPU上并行計算完成訓練
- 基于人類反饋數(shù)據(jù)進行調(diào)優(yōu):采用了大量的基于人類反饋的數(shù)據(jù)進行優(yōu)化,使得對話更加自然、流暢而具有邏輯性
由于OpenAI并未公布太多的ChatGPT的訓練細節(jié),所以,上述有一些模糊的估計數(shù)據(jù)。
值得注意的是,ChatGPT用到的核心技術其實并非原創(chuàng),其核心模型結構Transformer來自于Google的研究成果。
總結
自ChatGPT發(fā)布以來,很多人認為這是一個人類走向通用人工智能的突破,也有一些人認為它其實沒什么本質(zhì)的改進。有很多人對自己的職業(yè)發(fā)展產(chǎn)生了很深的焦慮感,也有很多人感覺觸碰到了科幻世界中的未來,還有很多人覺得又是一個可以好好撈一把的機會。
也許每個人都有必要去了解一下機器學習技術的原理,這樣才能形成對它的理性的認知。
參考
- wikipedia詞條羅納德·艾爾默·費希爾在 Wikipedia 的詞條。
- 人工智能與神經(jīng)網(wǎng)絡發(fā)展研究。
- OpenAI開發(fā)的ChatGPT資料(Training language models to follow instructions with human feedback)
- OpenAI開放的GPT-3資料(Language Models are Few-Shot Learners)
- OpenAI開放的GPT-2資料(Language Models are Unsupervised Multitask Learners)
- OpenAI開放的GPT資料(Improving Language Understanding by Generative Pre-Training)