機器學習技術之預測性維護
本文要點:
- 學習預測性維護系統(PMS),監控未來的系統故障并提前安排維護時間表
- 探討如何構建機器學習模型進行系統的預測性維護
- 了解機器學習的處理步驟,如選擇模型以及用Auto-Encoder技術去除傳感器噪聲
- 了解如何訓練機器學習模型,并在WSO2復雜事件處理器產品中運行模型
- 應用例子,在NASA引擎故障數據集上用回歸模型來預測剩余使用壽命(RUL)
在日常生活中,我們依賴于很多系統和機器。我們要開車出門、乘坐電梯或者搭乘飛機。渦輪能產生電,醫院里的機器能讓我們活著。這些系統會發生故障。有些故障只是給人的生活帶來不方便,而有些故障則生死攸關。
當風險很高的時候,我們要對系統進行常規性維護。譬如,車每幾個月保養一次,飛機每天保養一次。但是,如同我們在此文后面所討論的那樣,這些方法導致資源的浪費。
預測性維護能預測故障,采取行動來維修、更換系統,甚至計劃何時出現故障。它能極大地節省開銷、帶來高的可預測性和增強系統的可用性。
預測性維護有兩種形式來節省開銷:
- 避免或最小化故障停機時間。它會避免出現對故障停機不滿意的客戶,省錢,有時候還能挽救生命。
- 優化周期性的維護操作。
為了了解這些,我們來看看出租車公司。如果一輛出租車壞了,該公司需要安慰不滿意的顧客并派出替換的車輛,而該出租車和司機在維修期間都將閑著。故障的代價要遠高于表面上的代價。
解決這個問題的一種方法是,做一個消極者,在出現故障之前就更換不可靠的組件。譬如,進行常規的維護操作,如更換機油或輪胎。盡管常規維護比出現故障好,但是我們會在系統真正需要維護之前就進行維護。因此,這不是一個***的解決辦法。比如,每跑3000英里就換一次機油,不一定能有效地使用機油。如果我們能更準確地預測故障,那么該出租車可以跑幾百英里而不用換油。
預測性維護避免了兩種極端,***化地利用資源。它將檢測異常和故障模式,早早地給出警報。這些警報能促使人們更有效地維護這些組件。
在這篇文章中,我們將探討如何構建一個用于預測性維護的機器學習模型。下一章節討論機器學習技術,隨后討論例子中的NASA數據集。第四和第五章節討論如何訓練機器學習模型。“用WSO2 CEP運行模型”這一章節涵蓋了如何將模型應用于實際數據流上。
用于預測性維護的機器學習技術
為了進行預測性維護,首先,我們向系統中加入了傳感器,用于監控和收集系統運行的數據。預測性維護所需要的數據是時間序列數據。數據包括時間戳、在該時間戳所收集的傳感器讀數以及設備號。預測性維護的目的是,在時間“t”,使用截至到該時間的數據來預測設備在近期是否會發生故障。
預測性維護可通過以下兩種方法之一來實現:
- 分類方法 – 預測在接下來的n步中是否有可能發生故障。
- 回歸方法 – 預測在下次故障發生之前的剩余時間。我們稱之為剩余使用壽命(RUL)。
前一種方法只能提供一個由布爾值表示的答案,但是能從很少的數據上獲得很高的準確率。后一種方法可以提供關于故障發生時間的更多的信息,但也需要更多的數據。我們將在NASA引擎故障數據集上嘗試這兩種方法。
Turbofan引擎退化數據集
Turbofan引擎是一種現代的汽油渦輪引擎,NASA空間探索局用的就是這種引擎。NASA生成了下面的數據集來預測Turbofan引擎運行一段時間后的故障。可以從PCoE數據集獲得該數據集。
數據集包括每個引擎的時間序列。所有的引擎都是同一類型,但在制造過程中,每個引擎的初期的磨損程度和差異是不同的,這一點用戶是不知道的。有三種可選的配置,可用于改變每個引擎的性能。每個引擎有21個傳感器,當引擎運行時,傳感器收集與引擎狀態相關的測量數據。收集到的數據中有一些傳感器噪聲。
逐漸地,每個引擎會有一些不足,這些可以從傳感器讀數中發現。時間序列在發生故障前的某個時間結束。數據包括引擎單元號、時間戳、三種配置以及21個傳感器讀取的數據。
下面圖1和圖2顯示了數據的子集。

圖1:數據子集
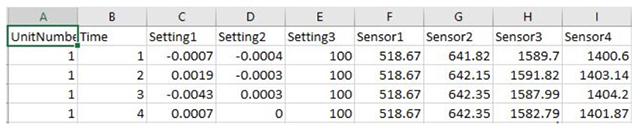
圖2:數據子集的前幾列
該實驗的目的是預測下一次故障發生的時間。
用回歸來預測剩余使用壽命(RUL)
預測RUL的目標是減小實際RUL值與預測RUL值之間的誤差。我們用均方根誤差作為衡量值,因為它會嚴厲地懲罰大的誤差,迫使算法預測結果接近實際RUL。
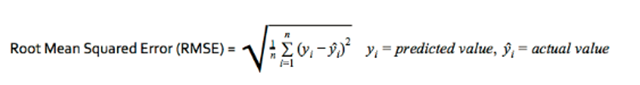
***階段:下面的管道描述了預測過程。作為***個階段,我們運行管道中的幾個突出的步驟,大致了解下可行性。我們沒有運行特征工程,而是在原始數據上運行算法。
第1階段:選擇模型
下面的圖3顯示了預測性維護的模型選擇管道。這里只用到了深顏色的管道步驟。

圖3:用于模型選擇的預測性維護管道
我們用到了scikit learn和H2O中的很多回歸算法。關于深度學習,我們用到了H2O中的深度學習算法,它既可以用于分類應用,也可以用于回歸應用。該算法基于多層結構的前饋神經網絡,用后向傳播的隨機梯度下降法來訓練神經網絡。
下面圖4顯示了結果。模型可以產生25-35的均方根誤差,也就是說,RUL將有約25-35時間步長的誤差。

圖4:模型選擇的均方根誤差
下面的幾個步驟,我們將集中在深度學習模型上。
第2階段:用Auto-Encoder去除傳感器噪聲
下圖5顯示了帶去噪功能的預測性維護管道。這里只用到了深顏色的管道步驟。

圖5:用于模型選擇的預測性維護管道
一般而言,傳感器讀數含有噪聲。軟件中自帶的ReadMe文件證實了這一點。因此,我們用autoencoder來去除噪聲。Autoencoder是一種簡單的神經網絡,它用同一個數據集作為網絡的輸入和輸出來訓練模型,網絡的參數個數少于數據集的維度。這與主成分分析(PCA)(http://setosa.io/ev/principal-component-analysis/)非常類似,在PCA中,數據被表示為它的幾個主要維度。由于噪聲的維度要遠高于常規數據,該過程能降低噪聲。
我們用到了有三個隱藏層的H2O Auto-encoder和下面的標準來去除噪聲。
去除噪聲后,均方根誤差降低了2。

表1:去除噪聲前后的均方根誤差
第3階段:特征工程
下面的圖6顯示了預測性維護的特征工程管道。這里只用到了深顏色的步驟。

圖6:用于模型選擇的預測性維護管道
在這一步,我們嘗試了很多特征,保留了最有預測能力的特征子集。我們用到的數據集是時間序列數據集,因此傳感器讀數是自相關的。因此,在時間“t”時的預測很有可能受到“t”之前的某些時間窗的影響。我們用到的大多數特征都是基于這些時間窗的。
在第三章節中,我們討論了數據集含有21個傳感器的讀數。更多的細節信息可參看與數據集一起提供的ReadMe文件。經過一些實驗之后,我們只用到了傳感器2、3、4、6、7、8、9、11、12、13、14、15、17、20和21。對于每一個被選中的傳感器,我們通過運用以下方法來生成特征:滑動標準差(窗口大小是5)、滑動k-最近平均值(窗口大小是5)以及窗口內的概率分布(窗口大小是10)。
我們試過其他某些特征但最終沒有使用它們,包括:滑動平均值、自相關、直方圖、滑動熵和滑動加權平均值。
這些特征使得均方根誤差降低了1。

表2:特征選擇前后的均方根誤差
第4階段:用網格搜索來優化超參數
圖7顯示了帶超參數優化的預測性維護管道。這里只用到了深顏色的管道步驟。

圖7:用于模型選擇的預測性維護管道
超參數控制算法的行為特點。在***一步,我們優化了如下的超參數:迭代次數、分布、激活函數以及隱藏層的個數。每個參數的詳細描述可以參看H2O文檔。我們用網格搜索找到***的參數,結果如下表所示。
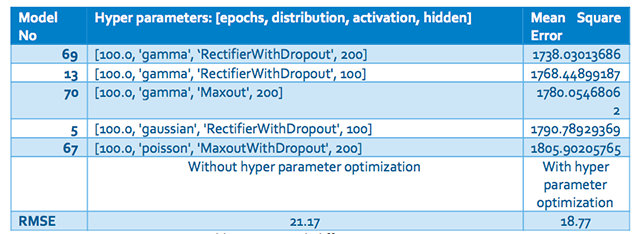
Table 3:不同超參數下的均方根誤差
如結果所描述的,超參數優化將均方根誤差減小了3。在剩余誤差直方圖(圖8)中,可以看見誤差收斂到“0”。過早預測和過遲預測的頻率都被最小化了。
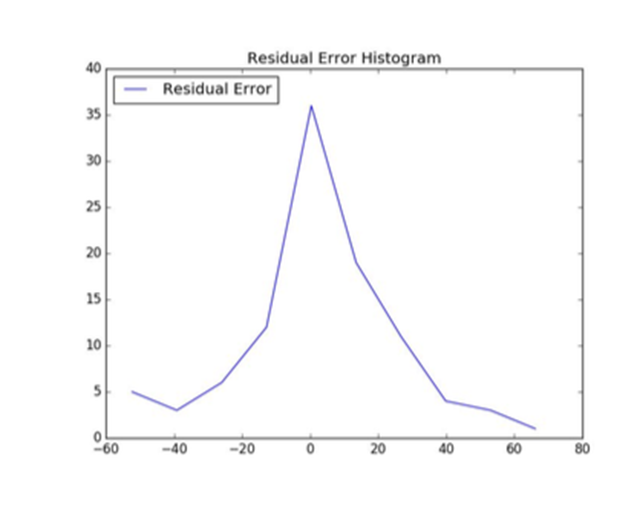
圖8:用于模型選擇的預測性維護管道
構建模型來預測后N步的故障
在這個方法中,我們將預測某機器是否會在接下來的30次循環中發生故障,而不是預測它的剩余壽命長短。我們將有故障的狀態看作正面的(P),沒有故障的狀態看作正常的(N)。我們運行一個深度學習分類模型,用到了同樣的特征工程和去噪過程。圖9給出了結果。
混淆矩陣

圖9:用于模型選擇的預測性維護管道
準確率(accuracy)描述了有多大比列的測試數據被正確地預測了。它給出了準確預測的測試案例的個數與測試案例總個數的比列。
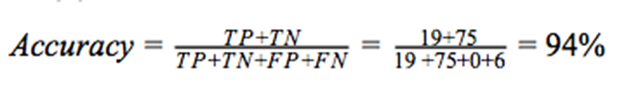
如果類的分布不均衡,那么僅僅考慮準確率會誤導人。在數據集中,當同一個類被過分表示時,就會出現不均衡的類分布。這種情況下,有些模型可能有很高的準確率但很差的預測性能。
為了避免這個問題,我們用查準率(precision)和查全率(recall)作為衡量標準。查全率是被正確預測的正面類的個數與所有實際為正面類的數據的個數的比例。
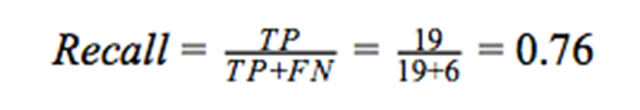
查準率被定義為一個模型能預測正面類的能力。它是被正確預測的正面類的個數與所有被預測為正面類的數據的個數的比列。
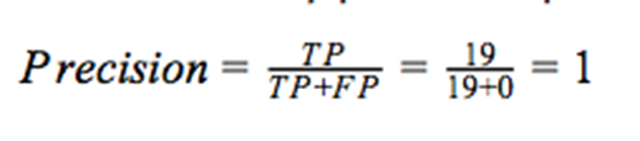
F1分數用于衡量測試的準確率。查準率和查全率都被用于該分數的計算中。
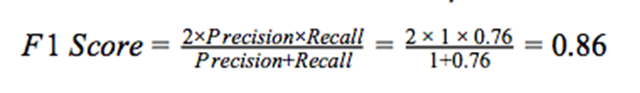
關于準確率、查全率、查準率和F1分數,***是值接近1,訓練的模型才有很好的性能。
用WSO2 CEP運行模型
在處理存儲在磁盤上的數據時,我們用批處理的形式來構建模型。然而,為了運用模型,我們需要在運行時向模型輸入可用的數據。數據的處理被稱為“流處理”。我們用流處理引擎WSO2 CEP來運用模型。
我們用H2O來構建模型。H2O能將模型導出為兩種格式中的一種:POJO(簡單Java對象)或MOJO(優化的模型對象)。前者需要被編譯而后者可以直接使用。我們用了CEP中的MOJO模型。
為了評估模型,我們用到了WSO2 CEP中的一個擴展。WSO2使用一種類似于SQL的查詢語言來處理數據流中的數據。
如圖10所示,一個復雜的事件處理系統接收事件流數據,并用一種類SQL查詢來評估它們。比如,一個給定的查詢可以計算一個一分鐘滑動窗口的stockQuotes流,將其與一分鐘窗口的Tweets流連接,并發送一個事件到PredictedStockQuotes流。
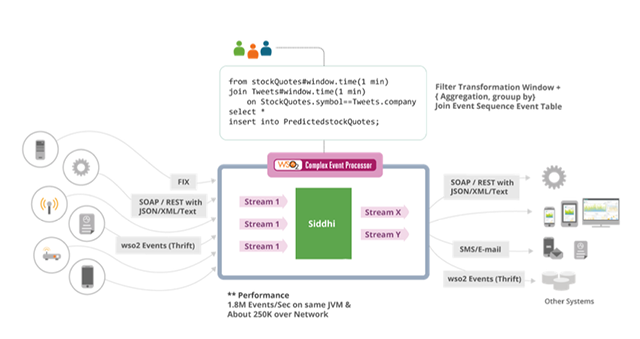
圖10:用于模型選擇的預測性維護管道
用CEP評估模型的查詢例子如下面所示。
- from data_input#h2opojo:predict('ccpp/DRF_model_python_1479702792496_1')
- select T, V, AP, RH, prediction
- insert into data_output
下面的圖11顯示了整個管道,包括訓練步驟和評估步驟。
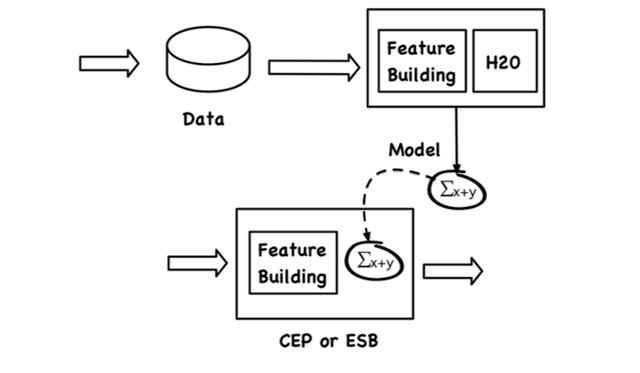
圖11:用于模型選擇的預測性維護管道
該查詢取走送到“數據輸入”流的事件,并運用機器學習模型。運用機器學習模型包括下面幾個步驟:
- 用“第3階段:特征工程”章節中所描述的預處理步驟對事件數據進行預處理,并生成特征集
- 用生成的特征集來評估機器學習模型。
- 返回結果
結論
預測性維護的主要目的是預測設備可能發生故障的時間。然后采取相關行動來預防這些故障。預測性維護系統(PMS)監控未來的故障并提前安排維護時間。
這些能降低一些成本。
- 減少維護頻率。
- 最小化花在某個被維護的設備上的時間,更充分地利用時間。
- 最小化維護費用。
本文探討了預測性維護的不同方法,使用了不同的回歸和分類算法。而且,本文一步步地展示了調整這些模型的技術。我們的最終解決方案在預測剩余使用壽命上的RMSE值是18.77,在預測后N(30)步內可能出現故障上的準確率是94%。