譯者 | 朱先忠
審校 | 重樓
簡介

GPT等語言模型最近變得非常流行,并被應用于各種文本生成任務,例如在ChatGPT或其他會話人工智能系統中。通常,這些語言模型規模巨大,經常使用超過數百億個參數,并且需要大量的計算資源和資金來運行。
在英語模型的背景下,這些龐大的模型被過度參數化了,因為它們使用模型的參數來記憶和學習我們這個世界的各個方面,而不僅僅是為英語建模。如果我們要開發一個應用程序,要求模型只理解語言及其結構,那么我們可能會使用一個小得多的模型。
注意:您可以在本文提供的Jupyter筆記本https://github.com/dhruvbird/ml-notebooks/blob/main/next_word_probability/inference-next-word-probability.ipynb上找到在訓練好的模型上運行推理的完整源代碼。
問題描述
假設我們正在構建一個滑動鍵盤系統,該系統試圖預測你下一次在手機上鍵入的單詞。基于滑動模式跟蹤的模式,用戶想要的單詞存在很多可能性。然而,這些可能的單詞中有許多并不是英語中的實際單詞,可以被刪除。即使在這個最初的修剪和消除步驟之后,仍有許多候選者,我們需要為用戶選擇其中之一作為建議。
為了進一步修剪這個候選詞列表,我們可以使用基于深度學習的語言模型,該模型能夠查看所提供的上下文,并告訴我們哪一個候選者最有可能完成句子。
例如,如果用戶鍵入句子“I’ve scheduled this(我已經安排好了)”,然后按如下圖所示滑動一個模式:
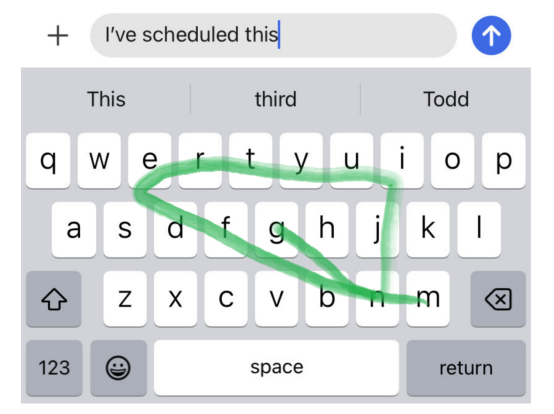
然后,用戶可能想要的一些英語單詞是:
- messing(攪亂)
- meeting(會議)
然而,如果我們仔細想想,很可能用戶的意思是“開會”,而不是“搗亂”,因為句子前半部分有“scheduled(預定)”一詞。
考慮到目前為止我們所知道的一切,我們可以選擇什么方案以便通過編程進行調整呢?讓我們在下面的部分發揮頭腦風暴,想出一些解決方案。
頭腦風暴解決方案
算法和數據結構
使用第一性原理(first principles),從數據語料庫開始,找到組合在一起的成對單詞,并訓練一個馬爾可夫模型(https://en.wikipedia.org/wiki/Markov_model)來預測句子中出現成對單詞的概率,這似乎是合理的。但是,您會注意到這種方法存在兩個重要問題。
- 空間利用率:英語中有25萬到100萬個單詞,其中不包括數量不斷增長的大量專有名詞。因此,任何建模一對單詞出現在一起的概率的傳統軟件解決方案都必須維護一個具有250k*250k=625億個單詞對的查詢表,這顯然有點過分。其實,許多單詞配對似乎不經常出現,可以進行修剪。即使在修剪之后,仍然存在很多對單詞需要考慮。
- 完整性:對一對單詞的概率進行編碼并不能公正地解決手頭的問題。例如,當你只看最近的一對單詞時,前面的句子上下文就完全丟失了。在“你的一天過得怎么樣(How is your day coming)”這句話中,如果你想檢查“來了(coming)”之后的單詞,你會有很多以“來了“開頭的配對。這會漏掉該單詞之前的整個句子上下文。人們可以想象使用單詞三元組等……但這加劇了上述空間利用問題。
接下來,讓我們把重點轉移到利用英語本質的解決方案上,看看這是否能對我們有所幫助。
自然語言處理
從歷史上看,NLP(自然語言處理)領域涉及理解句子的詞性,并使用這些信息來執行這種修剪和預測決策。可以想象這樣的情形:使用與每個單詞相關聯的一個POS標簽來確定句子中的下一個單詞是否有效。
然而,計算一個句子的詞性的過程本身就是一個復雜的過程,需要對語言有專門的理解,正如NLTK的詞性標記頁面所證明的那樣。
接下來,讓我們來看一種基于深度學習的方法,它需要更多的標記數據,但不需要那么多的語言專業知識來構建。
深度學習(神經網絡)
深度學習的出現顛覆了NLP領域。隨著基于LSTM和Transformer的語言模型的發明,解決方案通常包括向模型拋出一些高質量的數據,并對其進行訓練以預測下一個單詞。
從本質上講,這就是GPT模型正在做的事情。GPT模型總是被不斷訓練來預測給定句子前綴的下一個單詞(標記)。
例如,給定句子前綴“It is so would a would”,模型很可能會為句子后面的單詞提供以下高概率預測。
- day(白天)
- experience(經驗)
- world(世界)
- life(生活)
以下單詞完成句子前綴的概率也可能較低。
- red(紅色)
- mouse(老鼠)
- line(線)
Transformer模型體系結構(machine_learning_model)是ChatGPT等系統的核心。然而,對于學習英語語義的更受限制的應用場景,我們可以使用更便宜的運行模型架構,例如LSTM(長短期記憶)模型。
LSTM模型
接下來,讓我們構建一個簡單的LSTM模型,并訓練它來預測給定標記(token)前綴的下一個標記。現在,你可能會問什么是標記。
符號化
通常,對于語言模型,標記可以表示:
- 單個字符(或單個字節)
- 目標語言中的整個單詞
- 介于1和2之間的詞匯,這通常被稱為子詞
將單個字符(或字節)映射到標記是非常有限制的,因為我們要重載該標記,以保存關于它發生位置的大量上下文。這是因為,例如,“c”這個字符出現在許多不同的單詞中,在我們看到“c”之后預測下一個字符需要我們認真觀察引導上下文。
將一個單詞映射到一個標記也是有問題的,因為英語本身有25萬到100萬個單詞。此外,當一個新詞被添加到語言中時會發生什么呢?我們需要回去重新訓練整個模型來解釋這個新詞嗎?
子詞標記化(Sub-word tokenization)被認為是2023年的行業標準。它將頻繁出現在一起的字節的子字符串分配給唯一的標記。通常,語言模型有幾千(比如4000)到數萬(比如60000)個獨特的標記。確定什么構成標記的算法由BPE(字節對編碼:Byte pair encoding)算法確定。
要選擇詞匯表中唯一標記的數量(稱為詞匯表大小),我們需要注意以下幾點:
- 如果我們選擇的標記太少,我們就會回到每個角色一個標記的模式,模型很難學到任何有用的內容。
- 如果我們選擇了太多的標記,我們最終會出現這樣的情況:模型的嵌入表覆蓋了模型的其余權重,并且很難在受約束的環境中部署模型。嵌入表的大小將取決于我們為每個標記使用的維度的數量。使用256、512、786等大小并不罕見。如果我們使用512的標記嵌入維度,并且我們有100k個標記,那么我們最終會得到一個在內存中使用200MiB的嵌入表。
因此,我們需要在選擇詞匯量時進行平衡。在本例中,我們選取6600個標記,并用6600的詞匯大小訓練我們的標記生成器。接下來,讓我們來看看模型定義本身。
PyTorch模型
模型本身非常簡單。我們創建了以下幾個層:
- 標記嵌入(詞匯大小=6600,嵌入維數=512),總大小約為15MiB(假設嵌入表的數據類型為4字節的float32類型)
- LSTM(層數=1,隱藏尺寸=786),總尺寸約為16MiB
- 多層感知器(786至3144至6600維度),總尺寸約93MiB
整個模型具有約31M個可訓練參數,總大小約為120MiB。
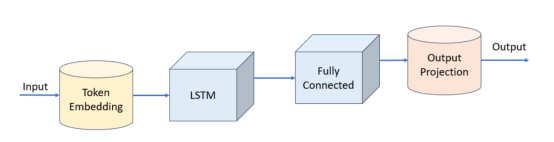
下面給出的是模型的PyTorch代碼。
class WordPredictionLSTMModel(nn.Module):
def __init__(self, num_embed, embed_dim, pad_idx, lstm_hidden_dim, lstm_num_layers, output_dim, dropout):
super().__init__()
self.vocab_size = num_embed
self.embed = nn.Embedding(num_embed, embed_dim, pad_idx)
self.lstm = nn.LSTM(embed_dim, lstm_hidden_dim, lstm_num_layers, batch_first=True, dropout=dropout)
self.fc = nn.Sequential(
nn.Linear(lstm_hidden_dim, lstm_hidden_dim * 4),
nn.LayerNorm(lstm_hidden_dim * 4),
nn.LeakyReLU(),
nn.Dropout(p=dropout),
nn.Linear(lstm_hidden_dim * 4, output_dim),
)
#
def forward(self, x):
x = self.embed(x)
x, _ = self.lstm(x)
x = self.fc(x)
x = x.permute(0, 2, 1)
return x
#
#以下是使用torchinfo庫輸出的模型摘要信息。
LSTM模型摘要
=================================================================
Layer (type:depth-idx) Param #
=================================================================
WordPredictionLSTMModel -
├─Embedding: 1–1 3,379,200
├─LSTM: 1–2 4,087,200
├─Sequential: 1–3 -
│ └─Linear: 2–1 2,474,328
│ └─LayerNorm: 2–2 6,288
│ └─LeakyReLU: 2–3 -
│ └─Dropout: 2–4 -
│ └─Linear: 2–5 20,757,000
=================================================================
Total params: 30,704,016
Trainable params: 30,704,016
Non-trainable params: 0
=================================================================解釋準確性:在P100 GPU上對該模型進行了約8小時的12M英語句子訓練后,我們獲得了4.03的損失值、29%的前1名準確率和49%的前5名準確率。這意味著,29%的時間中該模型能夠正確預測下一個標記,而49%的時間中訓練集中的下一個標記是該模型的前5個預測之一。
那么,我們的成功指標應該是什么?雖然我們模型的前1名和前5名精度數字并不令人印象深刻,但它們對我們的問題并不那么重要。我們的候選單詞是一小組符合滑動模式的可能單詞。我們希望我們的模型能夠選擇一個理想的候選者來完成句子,使其在語法和語義上連貫一致。由于我們的模型通過訓練數據學習語言的性質,我們希望它能為連貫句子分配更高的概率。例如,如果我們有一個句子“The baseball player(棒球運動員)”和可能的補全詞(“ran”、“swim”、“hid”),那么“ran”這個詞比其他兩個詞更適合后續使用。因此,如果我們的模型預測單詞ran的概率比其他單詞高,那么它對我們來說是有效的。
解釋損失值:損失值4.03意味著,預測的負對數可能性為4.03;這意味著,正確預測下一個標記的概率為e^-4.03=0.0178或1/56。隨機初始化的模型通常具有大約8.8的損失值,即-log_e(1/6600),因為該模型隨機預測1/6600個標記(6600是詞匯表大小)。雖然4.03的損失值似乎不大,但重要的是要記住,經過訓練的模型比未經訓練(或隨機初始化)的模型好大約120倍。
接下來,讓我們看看如何使用此模型來改進滑動鍵盤的建議。
使用模型修剪無效建議
讓我們來看一個真實的例子。假設我們有一個部分完成的句子“I think”,用戶做出下面藍色所示的滑動模式,從“o”開始,在字母“c”和“v”之間,并在字母“e”和“v”之間結束。
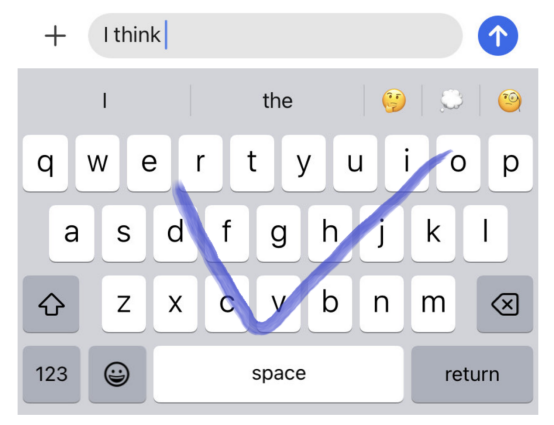
可以用這種滑動模式表示的一些可能的單詞是:
- Over(結束)
- Oct(十月的縮寫)
- Ice(冰)
- I’ve(我已經)
在這些建議中,最有可能的可能是“I’ve”。讓我們將這些建議輸入到我們的模型中,看看它會產生什么結果。
[I think] [I've] = 0.00087
[I think] [over] = 0.00051
[I think] [ice] = 0.00001
[I think] [Oct] = 0.00000=符號后的值是單詞有效完成句子前綴的概率。在這種情況下,我們看到“我已經”這個詞被賦予了最高的概率。因此,它是最有可能跟在句子前綴“I think”后面的詞。
下一個問題是:我們如何計算下一個單詞的概率。
計算下一個單詞的概率
為了計算一個單詞是句子前綴的有效完成的概率,我們在eval(推理)模式下運行模型,并輸入標記化的句子前綴。在為單詞添加空白前綴后,我們還將該單詞標記化。這樣做是因為HuggingFace預標記化器在單詞開頭用空格分隔單詞,所以我們希望確保我們的輸入與HuggingFace標記化器使用的標記化策略一致。
讓我們假設候選單詞由3個標記T0、T1和T2組成。
- 我們首先使用原始標記化的句子前綴來運行該模型。對于最后一個標記,我們檢查預測標記T0的概率。我們將其添加到“probs”列表中。
- 接下來,我們對前綴+T0進行預測,并檢查標記T1的概率。我們將此概率添加到“probs”列表中。
- 接下來,我們對前綴+T0+T1進行預測,并檢查標記T2的概率。我們將此概率添加到“probs”列表中。
“probs”列表包含按順序生成標記T0、T1和T2的各個概率。由于這些標記對應于候選詞的標記化,我們可以將這些概率相乘,得到候選詞完成句子前綴的組合概率。
用于計算完成概率的代碼如下所示。
def get_completion_probability(self, input, completion, tok):
self.model.eval()
ids = tok.encode(input).ids
ids = torch.tensor(ids, device=self.device).unsqueeze(0)
completion_ids = torch.tensor(tok.encode(completion).ids, device=self.device).unsqueeze(0)
probs = []
for i in range(completion_ids.size(1)):
y = self.model(ids)
y = y[0,:,-1].softmax(dim=0)
#prob是完成的概率。
prob = y[completion_ids[0,i]]
probs.append(prob)
ids = torch.cat([ids, completion_ids[:,i:i+1]], dim=1)
#
return torch.tensor(probs)
#我們可以在下面看到更多的例子。
[That ice-cream looks] [really] = 0.00709
[That ice-cream looks] [delicious] = 0.00264
[That ice-cream looks] [absolutely] = 0.00122
[That ice-cream looks] [real] = 0.00031
[That ice-cream looks] [fish] = 0.00004
[That ice-cream looks] [paper] = 0.00001
[That ice-cream looks] [atrocious] = 0.00000
[Since we're heading] [toward] = 0.01052
[Since we're heading] [away] = 0.00344
[Since we're heading] [against] = 0.00035
[Since we're heading] [both] = 0.00009
[Since we're heading] [death] = 0.00000
[Since we're heading] [bubble] = 0.00000
[Since we're heading] [birth] = 0.00000
[Did I make] [a] = 0.22704
[Did I make] [the] = 0.06622
[Did I make] [good] = 0.00190
[Did I make] [food] = 0.00020
[Did I make] [color] = 0.00007
[Did I make] [house] = 0.00006
[Did I make] [colour] = 0.00002
[Did I make] [pencil] = 0.00001
[Did I make] [flower] = 0.00000
[We want a candidate] [with] = 0.03209
[We want a candidate] [that] = 0.02145
[We want a candidate] [experience] = 0.00097
[We want a candidate] [which] = 0.00094
[We want a candidate] [more] = 0.00010
[We want a candidate] [less] = 0.00007
[We want a candidate] [school] = 0.00003
[This is the definitive guide to the] [the] = 0.00089
[This is the definitive guide to the] [complete] = 0.00047
[This is the definitive guide to the] [sentence] = 0.00006
[This is the definitive guide to the] [rapper] = 0.00001
[This is the definitive guide to the] [illustrated] = 0.00001
[This is the definitive guide to the] [extravagant] = 0.00000
[This is the definitive guide to the] [wrapper] = 0.00000
[This is the definitive guide to the] [miniscule] = 0.00000
[Please can you] [check] = 0.00502
[Please can you] [confirm] = 0.00488
[Please can you] [cease] = 0.00002
[Please can you] [cradle] = 0.00000
[Please can you] [laptop] = 0.00000
[Please can you] [envelope] = 0.00000
[Please can you] [options] = 0.00000
[Please can you] [cordon] = 0.00000
[Please can you] [corolla] = 0.00000
[I think] [I've] = 0.00087
[I think] [over] = 0.00051
[I think] [ice] = 0.00001
[I think] [Oct] = 0.00000
[Please] [can] = 0.00428
[Please] [cab] = 0.00000
[I've scheduled this] [meeting] = 0.00077
[I've scheduled this] [messing] = 0.00000這些例子顯示了單詞在它之前完成句子的概率。候選詞按概率遞減的順序排列。
由于Transformer正在慢慢取代基于序列的任務的LSTM和RNN模型,讓我們來看看針對相同目標的Transformer模型會是什么樣子。
一種Transformer(轉換器)模型
基于轉換器的模型是一種非常流行的架構,用于訓練語言模型來預測句子中的下一個單詞。我們將使用的具體技術是因果注意(causal attention)機制。我們將使用因果注意來訓練PyTorch中的轉換器編碼器層。因果注意意味著:我們將允許序列中的每個標記只查看其之前的標記。這類似于單向LSTM層在僅向前訓練時使用的信息。
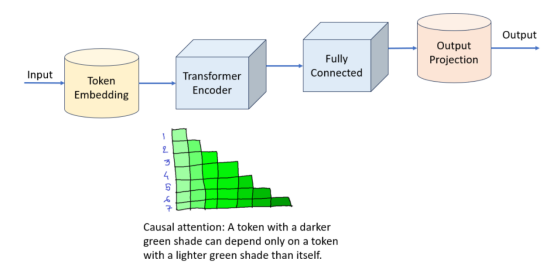
我們將在這里看到的Transformer模型直接基于nn.TransformerEncoder和PyTorch中的nn.TransformerEncoderLayer。
import math
def generate_src_mask(sz, device):
return torch.triu(torch.full((sz, sz), True, device=device), diagnotallow=1)
#
class PositionalEmbedding(nn.Module):
def __init__(self, sequence_length, embed_dim):
super().__init__()
self.sqrt_embed_dim = math.sqrt(embed_dim)
self.pos_embed = nn.Parameter(torch.empty((1, sequence_length, embed_dim)))
nn.init.uniform_(self.pos_embed, -1.0, 1.0)
#
def forward(self, x):
return x * self.sqrt_embed_dim + self.pos_embed[:,:x.size(1)]
#
#
class WordPredictionTransformerModel(nn.Module):
def __init__(self, sequence_length, num_embed, embed_dim, pad_idx, num_heads, num_layers, output_dim, dropout, norm_first, activation):
super().__init__()
self.vocab_size = num_embed
self.sequence_length = sequence_length
self.embed_dim = embed_dim
self.sqrt_embed_dim = math.sqrt(embed_dim)
self.embed = nn.Sequential(
nn.Embedding(num_embed, embed_dim, pad_idx),
PositionalEmbedding(sequence_length, embed_dim),
nn.LayerNorm(embed_dim),
nn.Dropout(p=0.1),
)
encoder_layer = nn.TransformerEncoderLayer(
d_model=embed_dim, nhead=num_heads, dropout=dropout, batch_first=True, norm_first=norm_first, activatinotallow=activation,
)
self.encoder = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)
self.fc = nn.Sequential(
nn.Linear(embed_dim, embed_dim * 4),
nn.LayerNorm(embed_dim * 4),
nn.LeakyReLU(),
nn.Dropout(p=dropout),
nn.Linear(embed_dim * 4, output_dim),
)
#
def forward(self, x):
src_attention_mask = generate_src_mask(x.size(1), x.device)
x = self.embed(x)
x = self.encoder(x, is_causal=True, mask=src_attention_mask)
x = self.fc(x)
x = x.permute(0, 2, 1)
return x
#
#我們可以用這個模型代替我們之前使用的LSTM模型,因為它是API兼容的。對于相同數量的訓練數據,該模型需要更長的時間來訓練,并且具有可比較的性能。
Transformer模型更適合長序列。在我們的例子中,我們有長度為256的序列。執行下一個單詞補全所需的大多數上下文往往是本地的,所以我們在這里并不真正需要借助轉換器的力量。
結論
在本文中,我們學習了如何使用基于LSTM(RNN)和Transformer模型的深度學習技術來解決非常實際的NLP問題。并不是每個語言任務都需要使用具有數十億參數的模型。需要建模語言本身而不需要記憶大量信息的專業應用程序可以使用更小的模型來處理,這些模型可以比我們現在看到的大規模語言模型更容易、更高效地部署。
注:本文中所有圖片均由作者本人創作。
譯者介紹
朱先忠,51CTO社區編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。
原文標題:Language Models for Sentence Completion,作者:Dhruv Matani