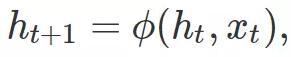淺談CNN和RNN
原創(chuàng)【51CTO.com原創(chuàng)稿件】
1 導(dǎo)讀
在上一篇文稿中主要對深度學(xué)習(xí)的基礎(chǔ)做了一個闡述,對于其中的神經(jīng)網(wǎng)絡(luò)和BP算法進(jìn)行額外的延伸與拓展。但作為日前最為火熱的人工智能技術(shù),掌握這些內(nèi)容遠(yuǎn)遠(yuǎn)還不夠。因?yàn)樯疃葘W(xué)習(xí)面臨的實(shí)際問題往往不是線性可分的問題,有時甚至超出了分類的問題,這就必須對深度學(xué)習(xí)模型加以改進(jìn),對其中的訓(xùn)練模型網(wǎng)絡(luò)進(jìn)行優(yōu)化,從而使得用來預(yù)測結(jié)果數(shù)據(jù)的網(wǎng)絡(luò)更加豐富化、智能化。做到實(shí)際上的智能,就是訓(xùn)練模型真正的能通過輸入的數(shù)據(jù)來預(yù)測結(jié)果并且每預(yù)測一次都可以對自身網(wǎng)絡(luò)模型進(jìn)行加強(qiáng)和優(yōu)化,也就好比一個“不斷學(xué)習(xí)進(jìn)步的人”一樣。隨著時間和訓(xùn)練次數(shù)的推進(jìn),訓(xùn)練的模型自身能力會越來越強(qiáng)。這樣的網(wǎng)絡(luò)模型才是我們真正需要的。當(dāng)然要達(dá)到這一步光是靠之前的線性網(wǎng)絡(luò)模型和淺層、深層神經(jīng)網(wǎng)絡(luò)遠(yuǎn)遠(yuǎn)不夠。所以,在一篇文稿中,將對對神經(jīng)網(wǎng)絡(luò)進(jìn)行延伸補(bǔ)充,是對神經(jīng)網(wǎng)絡(luò)模型的一次優(yōu)化,讓能運(yùn)用的實(shí)際場景更為廣泛和豐富。
2 卷積神經(jīng)網(wǎng)絡(luò)(CNN)
2.1 卷積神經(jīng)網(wǎng)絡(luò)VS傳統(tǒng)神經(jīng)網(wǎng)絡(luò)
CNN稱為卷積神經(jīng)網(wǎng)絡(luò),那么卷積神經(jīng)與之前的神經(jīng)網(wǎng)絡(luò)有什么區(qū)別呢?卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network)可以有效地減少了傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)對輸入數(shù)據(jù)所進(jìn)行的預(yù)處理環(huán)節(jié),降低了過程的復(fù)雜性。但是這種方式會導(dǎo)致網(wǎng)絡(luò)結(jié)構(gòu)的整體復(fù)雜性增加,因?yàn)樗峭ㄟ^輸入層或者隱層進(jìn)行傅里葉卷積操作來進(jìn)行輸出,增加網(wǎng)絡(luò)卷積層。這樣就會使得網(wǎng)絡(luò)更加難以優(yōu)化,很容易產(chǎn)生過擬合現(xiàn)象。所以這種神經(jīng)網(wǎng)絡(luò)主要應(yīng)用在圖像分類和物品識別等場景比較多,因?yàn)閷τ趫D像進(jìn)行預(yù)處理比較復(fù)雜,卷積神經(jīng)網(wǎng)絡(luò)雖然網(wǎng)絡(luò)復(fù)雜,但是減少了對圖像預(yù)處理環(huán)節(jié),直接把輸入的圖像作為輸入數(shù)據(jù)即可,并且通過卷積神經(jīng)網(wǎng)絡(luò)的非線性可以得出目標(biāo)函數(shù)的近似結(jié)構(gòu),從而得到更好的特征表達(dá)。
2.2 卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)層次
卷積神經(jīng)網(wǎng)絡(luò)主要分?jǐn)?shù)據(jù)輸入層(Input Layer)、卷積計(jì)算層(CONV Layer)、ReLU激勵層(ReLU Layer)、池化層(Pooling Layer)、全連接層(FC Layer)五個層次,這五個層次都是依次相連,每一層都接受上一層的輸出特征數(shù)據(jù)來提供給下一層。其中數(shù)據(jù)輸入層是對輸入數(shù)據(jù)的特征進(jìn)行提取;卷積計(jì)算層是對這些特征進(jìn)行卷積映射;激勵層是利用非線性激勵函數(shù)對神經(jīng)元進(jìn)行激勵達(dá)到條件將特征信息傳遞到下一個神經(jīng)元;池化層則是用來壓縮數(shù)據(jù)和參數(shù)的量,從而減小過擬合情況;全連接層就是連接所有輸出層的特征信息,并對這些信息進(jìn)行匯總整理完成輸出。下面分別闡述下這幾個層次的具體內(nèi)容。
2.3 輸入層(Input Layer)
2.3.1 預(yù)處理原因
和神經(jīng)網(wǎng)絡(luò)/機(jī)器學(xué)習(xí)一樣,都需要對輸入的數(shù)據(jù)進(jìn)行預(yù)處理操作,進(jìn)行預(yù)處理的主要原因在于:
1.輸入的數(shù)據(jù)單位可能不一樣,因此可能會導(dǎo)致神經(jīng)網(wǎng)絡(luò)的收斂速度較慢,從而致使訓(xùn)練時間過長;
2.數(shù)據(jù)范圍太大的輸入在模式分類中的作用會導(dǎo)致偏大,而數(shù)據(jù)范圍較小的作用也就有可能偏小;
3.由于神經(jīng)網(wǎng)絡(luò)中的激活函數(shù)是有值域限制的,因此需要將網(wǎng)絡(luò)訓(xùn)練的目標(biāo)數(shù)據(jù)映射到激活函數(shù)的值域;
4.Sigmod激活函數(shù)(0,1)區(qū)間以外區(qū)域很平緩,從而導(dǎo)致區(qū)分度太小,影響最終的輸出效果。
2.3.2預(yù)處理方式
輸入層對數(shù)據(jù)進(jìn)行預(yù)處理主要有3種方式,這3中數(shù)據(jù)預(yù)處理方式各有不同,分別是:
1.去均值:就是將輸入數(shù)據(jù)的各個維度中心化到0;
2.歸一化:將輸入的數(shù)據(jù)的各個維度的幅度歸一化到同一范圍,具體操作在之前的推薦系統(tǒng)文稿里有介紹。
3.PCA/白化:也就是用PCA降維或者是白化,也就是將數(shù)據(jù)的每個特征軸上的幅度歸一化,也是平時用的最多的數(shù)據(jù)預(yù)處理方法。
2.3.3 預(yù)處理效果
三種預(yù)處理方法的效果圖如下所示:

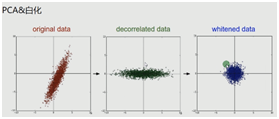
例如,利用白化進(jìn)行預(yù)處理后就會使得輸入的數(shù)據(jù)或者特征之間相關(guān)性較低,并且使得所有特征具有相同的方差。
2.4 卷積層(CONV Layer)
2.4.1 卷積神經(jīng)網(wǎng)絡(luò)
在將卷積層之前,首先大致了解下卷積神經(jīng)網(wǎng)絡(luò)。卷積神經(jīng)網(wǎng)絡(luò)是保存了層級的網(wǎng)絡(luò)結(jié)構(gòu),以至于使得不同的層次有不同的形式或者運(yùn)算與功能。而卷積神經(jīng)網(wǎng)絡(luò)是主要適用于圖片信息處理的場景,而卷積層就是識別圖像中一個最為關(guān)鍵的步驟或者層級。類似人的大腦在識別圖片的過程中,不同的腦皮質(zhì)層會處理來自不同方面的數(shù)據(jù),例如顏色、形狀等,然后通過不同皮質(zhì)層的處理結(jié)果進(jìn)行合并并且映射操作,從而得出最終的結(jié)果。也就是說第一部分實(shí)質(zhì)上是一個局部的觀察結(jié)果,第二部分是一個整體的結(jié)果合并。因此卷積神經(jīng)網(wǎng)絡(luò)就是基于人的大腦識別圖片的過程,每個神經(jīng)元就沒有必要對全局的圖像進(jìn)行感知,只需要對局部的圖像進(jìn)行感知即可,最后在更高層次對局部的信息進(jìn)行綜合操作得出全局的信息。
2.4.2 卷積層參數(shù)
卷積層也叫卷積計(jì)算層,類比人腦識別圖像過程,它主要有以下幾個概念:
1局部關(guān)聯(lián):每個神經(jīng)元看作是一個filter,進(jìn)行,作用就是對局部數(shù)據(jù)進(jìn)行識別;
2.窗口(receptive field)滑動,也就是將filter對局部數(shù)據(jù)進(jìn)行計(jì)算,滑動預(yù)先會設(shè)定步長,移動位置來得到下一個窗口;
3.對于窗口中滑動過程中,有深度(depth)、步長(stride)、填充值(zero-padding)這幾個重要參數(shù),深度即轉(zhuǎn)換的次數(shù)(結(jié)果產(chǎn)生的depth);步長就是設(shè)定每一步移動多少;填充值就是在矩陣周邊添加一些擴(kuò)充值(目的就是解決圖片輸入不規(guī)整)
計(jì)算模型如下圖所示:
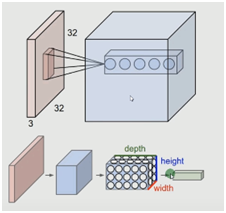
2.4.3 卷積計(jì)算
卷積計(jì)算過程中有一個重要機(jī)制就是參數(shù)共享機(jī)制,假設(shè)每個神經(jīng)元連接數(shù)據(jù)窗的權(quán)重是固定的,也就是固定每個神經(jīng)元的連接權(quán)重,因此就可以將神經(jīng)元看成一個模塊;也就是每個神經(jīng)元只關(guān)注一個特性,從而使得需要計(jì)算的權(quán)重個數(shù)會大大的減少。而卷積計(jì)算就是將一組固定的權(quán)重和不同窗口內(nèi)數(shù)據(jù)做內(nèi)積,就叫卷積。
2.5 激勵層(ReLU Layer)
2.5.1 非線性激勵函數(shù)
激勵層,顧名思義就是加一個激勵函數(shù)對其神經(jīng)元進(jìn)行刺激或者激勵,也就是使用映射函數(shù)來完成非線性的映射。在卷積神經(jīng)網(wǎng)絡(luò)中,激勵函數(shù)是非線性的。激勵層是接在卷積層后面的一層網(wǎng)絡(luò),負(fù)責(zé)將卷積層的輸出結(jié)果做一次非線性的映射,即激勵。在卷積神經(jīng)網(wǎng)絡(luò)中,經(jīng)常用到的非線性映射函數(shù)有S函數(shù)(Sigmoid)、雙曲正切函數(shù)(Tanh)、ReLU、Leaky ReLu、ELU和Maxout等。如下就是某些激勵函數(shù)的函數(shù)圖像:
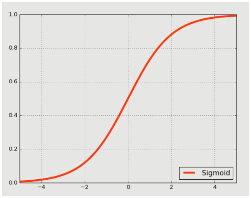
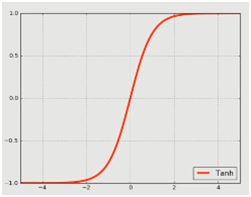
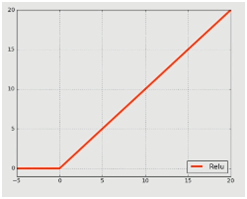
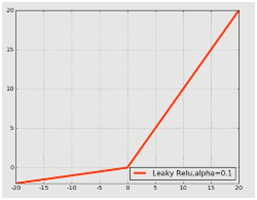
2.5.2 激勵層選取
由于非線性激勵函數(shù)較多,但是各有不同,因此在選擇激勵層的非線性激勵函數(shù)時,有不同的采取建議:
1.卷積神經(jīng)網(wǎng)絡(luò)(CNN)首先盡量不要使用S函數(shù)(sigmoid),如果要使用,建議只在全連接層使用;
2.優(yōu)先建議使用RELU,因?yàn)镽ELU函數(shù)的迭代速度快,但是有可能會導(dǎo)致效果不佳;
3.如果在選取RELU激勵函數(shù)后,達(dá)不到想要的效果(激勵函數(shù)失效)的情況下,則考慮使用Leaky ReLu或者M(jìn)axout;
4.雙曲正切函數(shù)(tanh)在某些情況下會有比較好的效果,但是能應(yīng)用的場景比較少。
因此總結(jié)起來就是:雙曲正切函數(shù)和S函數(shù)用于全連接層,ReLu用于卷積計(jì)算層,普遍使用ELU,而Maxout是使用最大值來設(shè)置值。
2.6 池化層(Pooling Layer)
池化層存在于連續(xù)的卷積層中間,它的主要功能就是通過逐步減小表征的空間尺寸從而減小參數(shù)量和網(wǎng)絡(luò)中的計(jì)算復(fù)雜度;并且池化層都是在每一個特征圖上獨(dú)立進(jìn)行操作。所以使用池化層有一個明顯的優(yōu)勢就是可以壓縮數(shù)據(jù)和參數(shù)的量,來解決過擬合問題。
在池化層中,一般采用兩種策略去進(jìn)行壓縮來減少特征數(shù)量,分別為最大池化(Max Pooling)和平均池化(Average Pooling)。例如給定某一個向量表征圖像,如下所示:
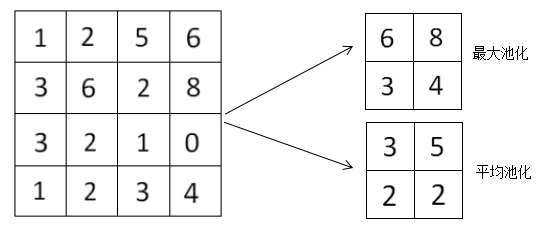
對于上面向量表征圖像池化為四個網(wǎng)格的小表征圖,那么利用最大池化策略就是每四個正方形格子取最大值,就分別得到6、8、3、4,同理可得,平均池化就是計(jì)算每四個正方形格子的平均值,就分別得到3、5、2、2,分別得到如上圖所示的網(wǎng)格。
2.7 全連接層(FC Layer)
類似傳統(tǒng)神經(jīng)網(wǎng)絡(luò)中的結(jié)構(gòu),卷積神經(jīng)網(wǎng)絡(luò)中的池化層(FC)中的神經(jīng)元跟之前層次的所有激活輸出都是連接著的,也就是說兩層之間所有的神經(jīng)元都有權(quán)重連接;作為最終的連接整理輸出,對每層的輸出結(jié)果進(jìn)行匯總計(jì)算,全連接層只會在卷積神經(jīng)網(wǎng)絡(luò)的尾部出現(xiàn)。
3 CNN訓(xùn)練算法與CNN優(yōu)缺點(diǎn)
3.1 CNN訓(xùn)練算法
CNN訓(xùn)練算法和一般的機(jī)器學(xué)習(xí)算法一樣,首先需要定義損失函數(shù)(Loss Function)來計(jì)算損失值,從而衡量出預(yù)測值和實(shí)際值之間的誤差,在這里一般采用平方和誤差公式。對于在網(wǎng)絡(luò)中找到最小損失函數(shù)的W和b的值,卷積神經(jīng)網(wǎng)絡(luò)通暢采用隨機(jī)梯度下降算法(SGD),這個算法在之前的推薦算法文稿中有所闡述。簡而言之,卷積神經(jīng)網(wǎng)絡(luò)的訓(xùn)練算法其實(shí)就是一個機(jī)器學(xué)習(xí)中的反向傳播(BP)算法,SGD需要計(jì)算W和b的偏導(dǎo),根據(jù)偏導(dǎo)來不斷迭代更新W和b。
3.2 CNN優(yōu)缺點(diǎn)
對于卷積神經(jīng)網(wǎng)絡(luò),有以下幾個優(yōu)點(diǎn):
1.可以共享卷積核(共享參數(shù)),使得卷積神經(jīng)網(wǎng)絡(luò)對高維的數(shù)據(jù)處理沒有壓力;
2.不需要選擇特征屬性,只需要訓(xùn)練好每一個權(quán)重,也就可以得到特征值;
3.在深層次的神經(jīng)網(wǎng)絡(luò)中,使得對圖像信息的抽取更為豐富,從而使得最終表達(dá)效果好;
但是卷積神經(jīng)網(wǎng)絡(luò)同樣也有一些缺點(diǎn),比如在卷積神經(jīng)網(wǎng)絡(luò)中需要調(diào)參,這就會導(dǎo)致需要大量的樣本,使得訓(xùn)練迭代次數(shù)比較多,最好使用GPU來訓(xùn)練;另外對于卷積神經(jīng)網(wǎng)絡(luò)每一層的輸出結(jié)果的物理含義并不明確,也就是很難從每一層輸出看出含義,即可解釋性較差。
4 正則化和Dropout延伸
神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)能力受神經(jīng)元數(shù)目和神經(jīng)網(wǎng)絡(luò)的層級影響,一般來說,神經(jīng)元數(shù)目越多,神經(jīng)網(wǎng)絡(luò)的層級就越高,那么這個神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)能力就越強(qiáng),但是有可能就會出現(xiàn)過擬合(overfitting)的問題。解決過擬合的方法主要還是正則化(Regularization)和Dropout,這兩個方法在之前的神經(jīng)網(wǎng)絡(luò)文稿中有所闡述,在這里進(jìn)一步說明下:
1.正則化是通過降低模型的復(fù)雜度,通過在cost函數(shù)上添加一個正則項(xiàng)的方式來降低overfitting;Dropout是通過隨機(jī)刪除神經(jīng)網(wǎng)絡(luò)中的部分神經(jīng)元來解決過擬合問題,使得在每次僅限迭代時,只是用部分神經(jīng)元訓(xùn)練模型來獲取W和d的值,從而使得CNN沒有太多的泛化能力,通過合并多次迭代的結(jié)果可以增加模型的準(zhǔn)確率。
2.一般情況下,對于同一組訓(xùn)練數(shù)據(jù),利用不同的神經(jīng)網(wǎng)絡(luò)之后,求它輸出的平均值就可以減少過擬合。因此Dropout就是利用這個原理,每次都丟掉一半左右的隱藏層神經(jīng)元,也就相當(dāng)于在不同的神經(jīng)網(wǎng)絡(luò)上進(jìn)行訓(xùn)練,這樣就減少了神經(jīng)元之間的依賴性,即每個神經(jīng)元不能依賴于某幾個其他神經(jīng)元(在這里指層與層之間想連接的神經(jīng)元),使得神經(jīng)網(wǎng)絡(luò)更具健壯性的特征,還能更好的提高準(zhǔn)確率。
對于一些典型的卷積神經(jīng)網(wǎng)絡(luò)模型介紹,網(wǎng)上都有資料,讀者感興趣的話可以自己搜索瀏覽下,在這里就不贅述了。
5 循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)
5.1 應(yīng)用場景
循環(huán)神經(jīng)網(wǎng)絡(luò)的運(yùn)用場景較多,在目前的互聯(lián)網(wǎng)或者信息科技公司運(yùn)用循環(huán)神經(jīng)網(wǎng)絡(luò)最多的幾個場景有自然語言處理(NLP)、機(jī)器翻譯、語音識別、圖像描述生成,自然語言處理也包括了語言模型與文本的生成,在互聯(lián)網(wǎng)行業(yè)主要劃分為語音/語義識別部門。對推向進(jìn)行識別描述,與卷積神經(jīng)網(wǎng)絡(luò)(CNN)不同點(diǎn)在于:CNN是去做一個圖片的識別,例如圖片的的東西是什么,而RNN雖然也可以識別圖片里的東西是什么,但是運(yùn)用RNN更多的是度圖片上的東西進(jìn)行描述,提供出圖片上的內(nèi)容信息。
那么有人就會問,既然有BP神經(jīng)網(wǎng)絡(luò)和CNN,為什么還要RNN呢?這個就跟RNN的循環(huán)有關(guān)了,之前的BP神經(jīng)網(wǎng)絡(luò)和CNN的每一個神經(jīng)元輸入輸出都是相互獨(dú)立的,互相并沒有產(chǎn)生干擾或者聯(lián)系,而在實(shí)際應(yīng)用場景中呢?有些場景的輸出內(nèi)容和之前的內(nèi)容是有關(guān)聯(lián)的,也就是一種“記憶”的概念,因此RNN引入這個概念,循環(huán)就是指每一個神經(jīng)元都執(zhí)行相同的任務(wù),但是輸出不僅依賴于輸入,還依賴于神經(jīng)元自身之前的“記憶”。
5.2 RNN結(jié)構(gòu)
因?yàn)?ldquo;記憶”的概念與時間的先后有關(guān),所以講神經(jīng)元序列按照時間先后展開就可以得到RNN的結(jié)構(gòu)如下圖所示:
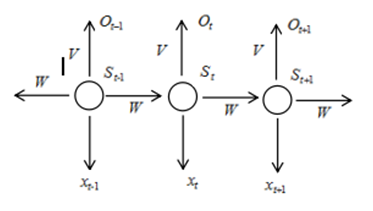
在上述結(jié)構(gòu)中, 是時間t的輸入, 是時間t出的“記憶”, 是時間t的輸出。
還有一種循環(huán)神經(jīng)網(wǎng)絡(luò)是雙向RNN(Bidirectional RNN),也就是在之前的結(jié)構(gòu)中當(dāng)前t的輸出不僅僅和之前的序列有關(guān),而且還與之后的序列有關(guān)。例如:預(yù)測一個語句中缺失的詞語,那么就需要根據(jù)上下文進(jìn)行預(yù)測。雙向RNN其實(shí)是一個相對簡單的RNN結(jié)構(gòu),是有兩個RNN上下疊加在一起組成。輸出就是有這兩個RNN的隱藏層的狀態(tài)決定。
5.3 訓(xùn)練算法
5.3.1 BPTT算法
循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)的訓(xùn)練其實(shí)也很CNN訓(xùn)練一樣,同樣可以用BP反向傳播誤差算法。唯一的區(qū)別就在于:RNN中的參數(shù)W是共享的,并且在隨機(jī)梯度下降算法中,每一步的輸出不僅僅依賴當(dāng)前步的網(wǎng)絡(luò),并且還需要前若干步網(wǎng)絡(luò)的狀態(tài),也就是對之前的BP短發(fā)進(jìn)行改版,這個改版的BP算法叫做BPTT(Backpropagation Through Time),BPTT算法和BP算法一樣,在多層訓(xùn)練時,都有可能產(chǎn)生梯度消失和爆炸的問題。BPTT算法的思路和BP算法一樣,都是求偏導(dǎo),但是需要同時考慮到時間對step的影響。
5.3.2 LSTM
對于BPTT算法中可能產(chǎn)生梯度消失和梯度爆炸的問題,這是由于在BPTT計(jì)算中,對于長期依賴“記憶”問題導(dǎo)致的,而LSTM就特別適合解決這類長時間依賴的問題。LSTM是RNN的一種,大致結(jié)構(gòu)一致,區(qū)別在于LSTM的“記憶神經(jīng)元”是改造過后的,并且記錄的信息就會一致傳遞下去,不該記錄的信息就會被截?cái)嗟簟? 如下圖所示
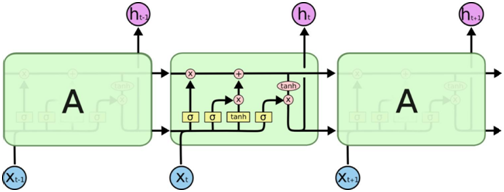
LSTM結(jié)構(gòu)圖
在LSTM中,有一個關(guān)鍵點(diǎn)在于“細(xì)胞狀態(tài)”,也就是記憶神經(jīng)元的狀態(tài)。細(xì)胞狀態(tài)類似于傳送帶,都是直接在整個鏈上運(yùn)行,只有一些少量的線性交互過程,這樣就使得信息在上面流傳是保持不變較為容易。那么怎么去控制“細(xì)胞狀態(tài)”呢?控制“細(xì)胞狀態(tài)”的過程有以下幾個步驟:
1.LSTM可以通過“門”(gates)這種結(jié)構(gòu)來去除或者增加“細(xì)胞狀態(tài)”的信息;
2.用包含一個sigmoid神經(jīng)網(wǎng)絡(luò)層次和一個pointwist乘法操作;
3.Sigmoid層輸出一個0到1之間的概率值,描述每個部分有多少量可以通過,0表示“不允許任務(wù)變量通過”,1表示“運(yùn)行所有變量通過”;
4.LSTM中主要有是三個“門”結(jié)構(gòu)來控制“細(xì)胞狀態(tài)”。
5.3.3 三個“門”?
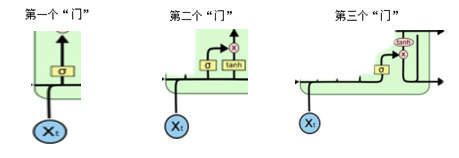
下面對LSTM的三個“門”進(jìn)行延伸:
1.第一個“門”也叫“忘記門”,它決定了從“細(xì)胞狀態(tài)”中丟棄什么信息;比如在語言模型中,細(xì)胞狀態(tài)可能包含了性別信息,當(dāng)我們看到新的名詞后,就可以考慮忘記掉舊的數(shù)據(jù)信息;
2.第二個門也叫“信息增加門”,它決定了放什么新的信息到“細(xì)胞狀態(tài)”中去,其中Sigmoid層決定什么值需要更新;Tanh層創(chuàng)建一個新的候選向量,主要都是為了進(jìn)行狀態(tài)更新做準(zhǔn)備。
3.第三個“門”就是基于“細(xì)胞狀態(tài)”得到輸出,經(jīng)過第一個“門”和第二個“門”后,可以缺東傳遞信息的刪除和增加,也就可以進(jìn)行“細(xì)胞狀態(tài)”的更新,第三個“門”首先運(yùn)行一個Sigmoid層來確定細(xì)胞狀態(tài)的哪個部分被輸出,然后再使用tanh處理細(xì)胞狀態(tài)得到-1到1之間的值,再將它與sigmoid門的輸出相乘,輸出過程確定了輸出的部分。
三個“門”的部分圖分別如下所示:
5.3.4 LSTM結(jié)構(gòu)改造
對于上述的LSTM結(jié)構(gòu),也有針對其中的某些部分進(jìn)行改造,其中例如有在第二個“門”之前增加“配額phone connections”層,從而使得“門”層也接受細(xì)胞狀態(tài)的輸入;還有通過耦合忘記門和更新輸入門,不在單獨(dú)考慮忘記什么信息、增加什么信息,而是放在一起進(jìn)行考慮。
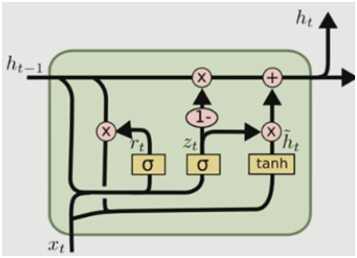
在對LSTM結(jié)構(gòu)進(jìn)行設(shè)計(jì)改造中,相對比較出眾的就是2014年提出的一個結(jié)構(gòu),如下圖所示,主要區(qū)別在于以下幾點(diǎn):
1.該結(jié)構(gòu)將忘記門和輸入門合并成為一個單一的更新門,也就是將忘記的信息和輸入的信息一并進(jìn)行考慮;
2.合并了數(shù)據(jù)單元狀態(tài)與隱藏狀態(tài);
3.它的結(jié)構(gòu)比LSTM的結(jié)構(gòu)更為簡單。
6 總結(jié)與補(bǔ)充
6.1 總結(jié)
深度學(xué)習(xí)的神經(jīng)網(wǎng)絡(luò)在目前主要運(yùn)用場景為圖片識別、文本識別、游戲、語言識別等。其中的一些主要算法在上面也已經(jīng)進(jìn)行了闡述。除此之外還有一些輔助算法如極大極小值算法。對于這一塊內(nèi)容我將在下文提到。因此在學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)這一塊的時候,一定要分類去理解、分情況去討論,結(jié)合實(shí)際的運(yùn)用場景功能來完成神經(jīng)網(wǎng)絡(luò)模型的選擇與訓(xùn)練,從而達(dá)到最好的輸出效果。關(guān)于CNN和RNN的一些擴(kuò)展,其中包括Fast R-CNN(快速卷積)和R-FCN(基于區(qū)域的全卷積)這些內(nèi)容和結(jié)構(gòu),有興趣的讀者可以自行了解下,實(shí)際運(yùn)用的場景并不多。
6.2 補(bǔ)充
對于運(yùn)用神經(jīng)網(wǎng)絡(luò)知識這一塊的深度學(xué)習(xí)領(lǐng)域,還有額外的一些需要了解的知識內(nèi)容,例如遷移學(xué)習(xí)和極大極小值算法等。在這里我將對這些進(jìn)行一個補(bǔ)充,僅僅作為一個引子,來激發(fā)讀者更多的探討興趣。
6.2.1 遷移學(xué)習(xí)
遷移學(xué)習(xí)就是一個算法思想、一個算法訓(xùn)練方式,一般的深度學(xué)習(xí)算法都會要求我們的訓(xùn)練數(shù)據(jù)集中數(shù)據(jù)標(biāo)注數(shù)據(jù)比較多,但是在實(shí)際應(yīng)用中,有很多場景標(biāo)注的數(shù)據(jù)是比較少的。因此使用比較少的數(shù)據(jù)來進(jìn)行訓(xùn)練而達(dá)到跟之前一樣很好的效果是非常困難的。而遷移學(xué)習(xí)就是一個解決這一類問題的算法思想,它是指用基于很少標(biāo)注的數(shù)據(jù)集進(jìn)行高質(zhì)量的模型訓(xùn)練。在目前運(yùn)用場景中,使用遷移學(xué)習(xí)的主要是在圖片檢測或者標(biāo)注這一塊。
6.2.2 極大極小值算法
極大極小值算法(MiniMax)是一種找出失敗的最大可能性中的最小值的算法,也就是盡量是對手的最大收益最小化。這個算法通常是通過遞歸的形式實(shí)現(xiàn),常用語棋類或者競技較量類的游戲程序中。
該算法同時也就是一個零和博弈,也就是使得雙方的輸贏總和為0,即一方要在可選的條件下選擇出對其優(yōu)勢最大化的方法,而另外一方也需要選擇出令對手優(yōu)勢最小化的一個方法。簡而言之,博弈中有人贏錢,就得有人輸錢,輸?shù)腻X數(shù)是與贏的錢數(shù)相等。但是在這算法過程中,因?yàn)橛玫降氖沁f歸操作,所以算法的層級深度會非常深,學(xué)過數(shù)據(jù)結(jié)構(gòu)的都知道,遞歸算法雖然書寫代碼簡便,但是其時間復(fù)雜度較高,甚至?xí)萑胨姥h(huán)而宕機(jī),因此在使用極大極小值算法中就有可能對神經(jīng)網(wǎng)絡(luò)進(jìn)行優(yōu)化,盡量降低神經(jīng)網(wǎng)絡(luò)訓(xùn)練時的時間復(fù)雜度。
【51CTO原創(chuàng)稿件,合作站點(diǎn)轉(zhuǎn)載請注明原文作者和出處為51CTO.com】