基于Transformer的高效、低延時、流式語音識別模型
從場景上,語音識別可以分為流式語音識別和非流式語音識別。非流式語音識別(離線識別)是指模型在用戶說完一句話或一段話之后再進行識別,而流式語音識別則是指模型在用戶還在說話的時候便同步進行語音識別。流式語音識別因為其延時低的特點,在工業界中有著廣泛的應用,例如聽寫轉錄等。
Transformer流式語音識別挑戰
目前,Transformer 模型雖然在離線場景下可以進行準確的語音識別,但在流式語音識別中卻遭遇了兩個致命的問題:
1)計算復雜度和內存儲存開銷會隨著語音時長的增加而變大。
由于 Transformer 使用自注意力模型時會將所有的歷史信息進行考慮,因此導致了存儲和計算的復雜度會隨著語音時長線性增加。而流式語音識別往往本身就有很長的語音輸入,所以原生的 Transformer 很難應用于流式語音識別之中。
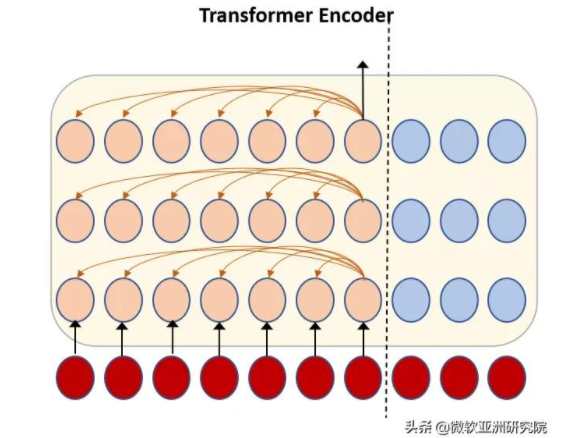
圖1:流式語音識別 Transformer 自注意力示意圖
2)Transformer 模型由于層數過多會導致未來窗口大小(lookahead window)傳遞。
如下圖所示,Transformer 模型如果每層往后看一幀,那么最終的向前看(lookahead)會隨著 Transformer 層數的增加而累積。例如,一個18層的Transformer,最終會積累18幀的延時,這將在實際應用中帶來很大的延時問題,使得語音識別反應速度變慢,用戶體驗不佳。
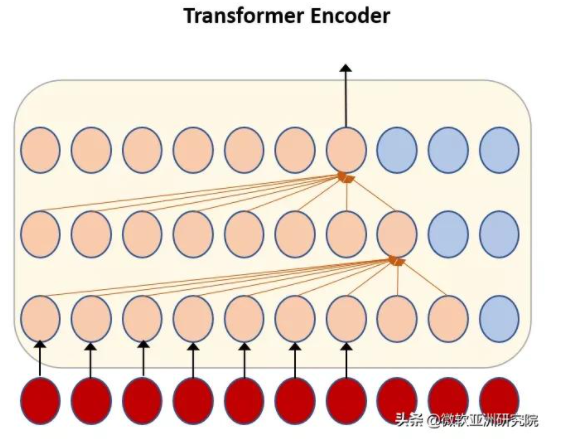
圖2:Transformer 的未來窗口隨層數而增加
基于塊和基于記憶的解決方案
為了解決上述 Transformer 模型在流式語音識別中的問題,科研人員提出了基于塊(chunk)和基于記憶(memory)的兩種解決方案。
1) 基于塊(chunk)的解決方案
第一種方案為基于塊的解決方案,如下圖所示,其中虛線為塊的分隔符。其主體思想是把相鄰幀變成一個塊,之后根據塊進行處理。這種方法的優點是可以快速地進行訓練和解碼,但由于塊之間沒有聯系,所以導致模型準確率不佳。
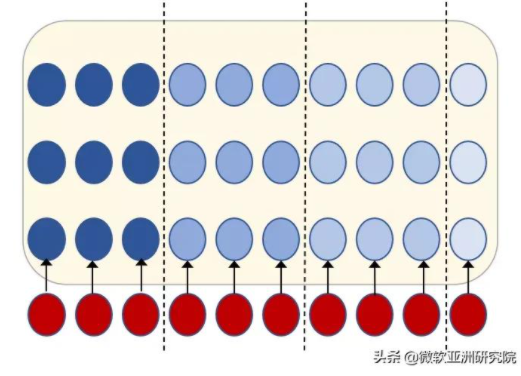
圖3:基于塊的流式語音識別解決方案
2) 基于記憶(memory)的解決方案
基于記憶的解決方案的主體思想則是在塊的基礎上引入記憶,讓不同塊之間可以聯系起來。然而,此方法會破壞訓練中的非自循環機制,使得模型訓練變慢。
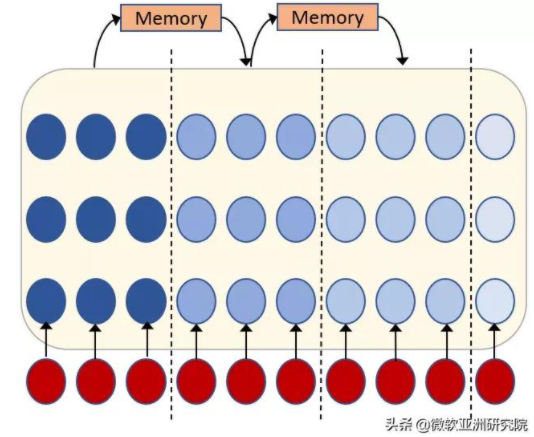
圖4:基于記憶的流式語音識別解決方案
工業界中往往有著大量的訓練數據,基于記憶的解決方案會讓模型訓練開銷增大。這就促使研究人員需要去尋找可以平衡準確率、訓練速度和測試速度的方案。
快速訓練和解碼,Mask is all you need
針對上述問題,微軟的研究員們提出了一種快速進行訓練和解碼的方法。該方法十分簡單,只需要一個掩碼矩陣便可以讓一個非流的 Transformer 變成流的 Transformer。
下圖為非流和0延時的掩碼矩陣,其為一個全1矩陣,或者一個下三角陣。
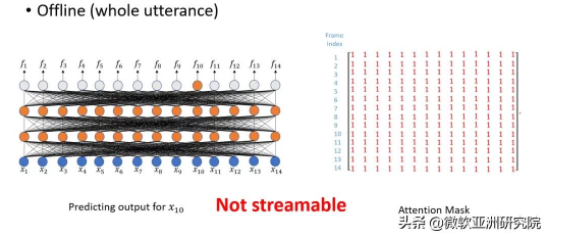
圖5:離線語音識別編碼器掩碼矩陣
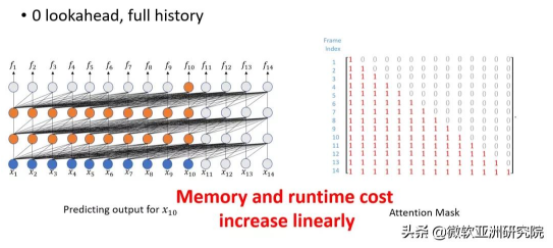
圖6:0延時的流式語音識別編碼器掩碼矩陣
研究員們希望將基于塊的方法中的不同塊連接起來,并保持 Transformer 并行訓練的特點。為了達到這個目的,研究員們提出了一種基于塊的流式 Transformer,具體算法如下:
首先,在當前幀左側,讓每一層的每一幀分別向前看 n 幀,這樣隨著層數的疊加,Transformer 對歷史的視野可以積累。如果有 m 層,則可以看到歷史的 n*m 幀。雖然看到了額外的 n*m 幀,但這些幀并不會拖慢解碼的時間,因為它們的表示會在歷史計算時計算好,并不會在當前塊進行重復計算。與解碼時間相關的,只有每一層可以看到幀的數目。
因為希望未來的信息延時較小,所以要避免層數對視野的累積效應。為了達到這個目的,可以讓每一個塊最右邊的幀沒有任何對未來的視野,而塊內的幀可以互相看到,這樣便可以阻止延時隨著層數而增加。
最后,在每個塊之間讓不同幀都可以相互看到,這樣平均延時即塊長度的二分之一。
此方法可以讓 Transformer 保持并行訓練的優勢,快速進行訓練,其得到的掩碼矩陣如下。
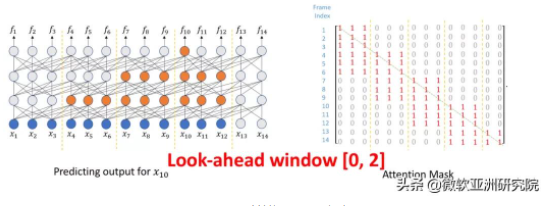
圖7:所提出方法的編碼器掩碼矩陣
在解碼過程中,解碼時間主要由塊的大小而決定。將之前的 key 和 value 進行緩存,這樣可以避免重復計算,以加速解碼。該方法的公式如下,歷史的 key 和 value(標紅)在進行注意力權重(attention weight)計算中被緩存。
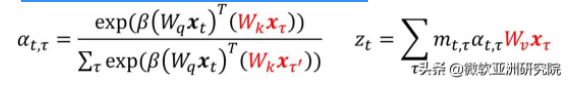
實驗
數據集與模型設置
研究員們的實驗在微軟內部進行了6.5萬小時以上的訓練,并在微軟內部約180萬詞的測試集上進行了測試。實驗使用了32個 GPU,以混合精度的方式訓練了約兩天可以使模型收斂,并且使用 torchjit 進行測速。研究員們使用 Transducer 框架實現語音識別流式識別,實驗對比了 Transformer Transducer (T-T)、Conformer Transducer (C-T)以及 RNN Transducer(RNN-T),其中 Transformer 和 Conformer 的編碼部分使用了18層,每層 hidden state(隱藏狀態)= 512的參數量。而 Transducer 中的預測網絡(predictor network)則使用了 LSTM 網絡結構,并包含兩層,每層 hidden state = 1024。RNN-T 也與其大小相似。
低延時解碼效果
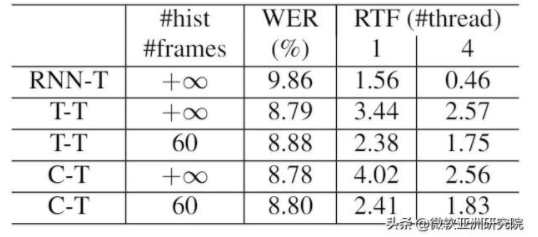
表1:低延時解碼效果
從表1可以看到:1)在低延時的情況下,T-T 和 C-T 會比 RNN-T 消除10% 的詞錯率( Word Error Rate,WER);2)如果每層向左看60幀(1.8s),它和看全部歷史的結果相比,性能損失不大,約1%左右;3)然而 T-T 的速度卻比 RNN-T 慢了一些,在四線程的情況下 Transformer 速度比 RNN 慢了3倍左右。這個問題可以嘗試利用批(batch)的方法來解決,即把相鄰的幾幀一起進行解碼,再利用 Transformer 的并行能力,加速解碼。
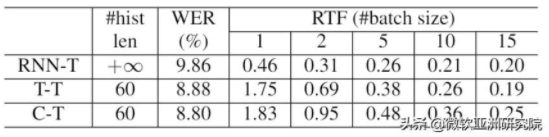
表2:Transformer 的實時率
表2是根據批(batch)中幀的數目的不同,所對應的不同的 Transformer 的實時率。可以看到在兩幀一起解碼時,Transformer 就已經達到了 RTF<1,而在5幀一起時,RTF<5。據此可以得出結論,在犧牲很少的延時的情況下(2幀約為 40ms),T-T 可以不做量化便可在實際場景中應用。
低延時解碼效果
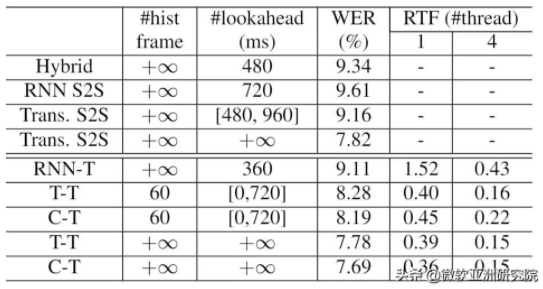
表3:低延時解碼效果
而在低延時的情況下,Transformer Transducer 家族的優勢更是得以突顯。對比傳統混合(hybrid)模型,T-T有著13%的 WER改 善,對比流式的 S2S 模型(參數量一致),Transducer 模型往往會達到更好的效果(對比 RNN S2S 和 Trans S2S)。而在同樣的 Transducer 框架下,Transformer 模型會比 RNN 模型達到更好的效果,并且速度上也有顯著的優勢。令人驚訝的是,通過上述方法,目前 T-T 的離線和流式的距離不足10%,這就證明了研究員們提出的流式方法的有效性,可以最大程度避免精度的損失。
8比特量化
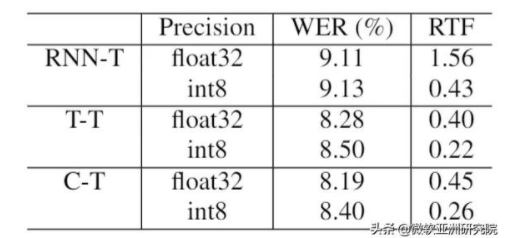
表4:8比特量化結果
經過8比特量化,可以得到更快的 Transducer 模型。在單線程的情況下,Transformer 可以提升一倍的速度,不過,RNN-T 可以提升約4倍的速度。其中,Transformer 速度提升有限的原因是,SoftMax 和 Layer Norm 等操作,難以通過8比特進行加速。
結語
在本文中,微軟 Azure 語音團隊與微軟亞洲研究院的研究員們一起提出了一套結合 Transformer 家族的編碼器和流式 Transducer 框架的流式語音識別方案解決方案。該方案利用 Mask is all you need 的機制,可以對流式語音識別模型進行快速訓練以及解碼。在六萬五千小時的大規模訓練數據的實驗中,可以看到 Transformer 模型比 RNN 模型在識別準確率上有著顯著地提高,并在低延時的場景下,解碼速度更快。
未來,研究員們將繼續研究基于 Transformer 的語音識別模型,力爭進一步降低解碼的運算消耗,在0延時的場景下,讓 Transformer 模型可以與 RNN 模型達到相同的解碼速度。