20個GitHub優秀開源大數據項目
近年來數字戰略的推動進一步增加了市場對大數據相關項目的需求,而大數據技術的發展也支撐著社會數字化的發展。大數據技術的發展最開始便得益于開源社區的貢獻,出現了許多優秀的大數據相關的開源項目。根據“第九屆開源未來年度調查” ,全世界有72-78%的公司參與了開源項目。其中大數據35%、云計算39%、操作系統33%,物聯網31%,這些技術方向的快速發展多少都離不開開源項目的推動。
下面列舉了20個最受歡迎且有趣的開源大數據項目,供研究、參考。

1.Apache Beam
https://github.com/apache/beam
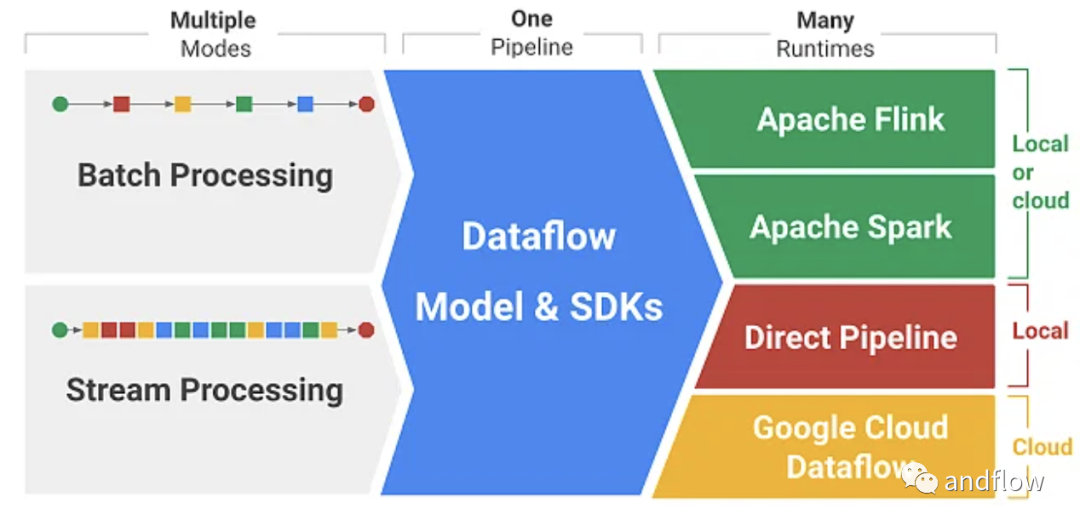
Apache Beam是2016年推出的高級統一編程開源模型。它的名字“Beam”來源于 “Batch” 和 “Stream” ,beam支持眾多分布式處理后端,包括Apache Flink、Apache Spark、Apache Samza、Hazelcast Jet、Google Cloud Dataflow等。它甚至允許您使用任意三種編程語言的開源Beam SDK(軟件開發工具包)構建定義數據管道的程序:Java、Python和Go。
Apache Beam 的優點主要有:統一的批處理和流式API、更高的抽象級別和跨運行時的可移植性。唯一的缺陷是透明度和可定制化較低,與其他Apache API相比,在性能優化上相對不足。
2.Clickhouse
https://github.com/ClickHouse/ClickHouse

Clickhouse是列數據庫管理系統,用于在線分析處理任務(OLAP)。它允許在運行時同時創建庫和表、加載數據、運行查詢,無需重新配置或重新啟動服務器。通過減少磁盤IO、數據本地化和壓縮,clickhouse能夠做到比傳統關系數據庫快100- 1000倍。
它的優勢主要包括:使用編解碼器進行數據壓縮以獲得出色的性能、支持多核并行處理、支持多服務器分布式處理、支持SQL語法、提供向量計算引擎、支持實時數據更新、支持自適應連接算法、支持數據復制和數據完整性、支持基于角色的訪問控制等。
因為Clickhouse優秀的性能、可擴展性、可靠性和安全性。 像Yandex、CloudFare、Uber、eBay、Spotify這樣的公司更傾向于使用Clickhouse。
同時Clickhouse也存在一些缺陷,例如:缺乏事務機制,沒有高效的切換、刪除、插入數據的能力、低延遲和稀疏索引。
3.Apache Flink
https://github.com/apache/flink

ApacheFlink是一個有狀態的計算框架。它可以作為兩類數據流的分布式處理引擎:無界數據流和有界數據流。Flink可以在所有典型的集群環境中運行,并在任何規模的內存中進行速度計算,支持流和批處理,具備全面的狀態管理,擁有事件時(event-time)處理語義和狀態的一致性保證等功能。
Flink具有動態消息、狀態一致性、多語言支持、云原生、無數據庫要求和“無狀態”操作等優勢。
Flink的常見缺點包括:社區和論壇較少、缺乏出色的API支持,以及難以對數據可視化進行編程等。
4.Nvidia RAPIDS
https://github.com/rapidsai

RAPIDS項目主要用于在GPU上運行端到端的數據科學和分析管道。基于CUDA-X AI構建,它使用NVIDIA CUDA原生語言進行基本算法優化,提供友好的Python用戶界面展示GPU并行性能和高帶寬內存的速度。除了分析和數據科學之外,RAPIDS還可用于日常數據預處理任務。通過提供DataFrame API,與各種機器學習算法連接,以加速端到端管道,而不會產生通常的序列化開銷。RAPIDS還支持多個節點、多GPU部署,從而在更大的數據集上實現更快的處理和訓練。另外,RAPIDS還具備輕松集成、頂級模型準確性、支持開源和減少學習成本等優勢。
5.TDengine
https://github.com/taosdata/TDengine
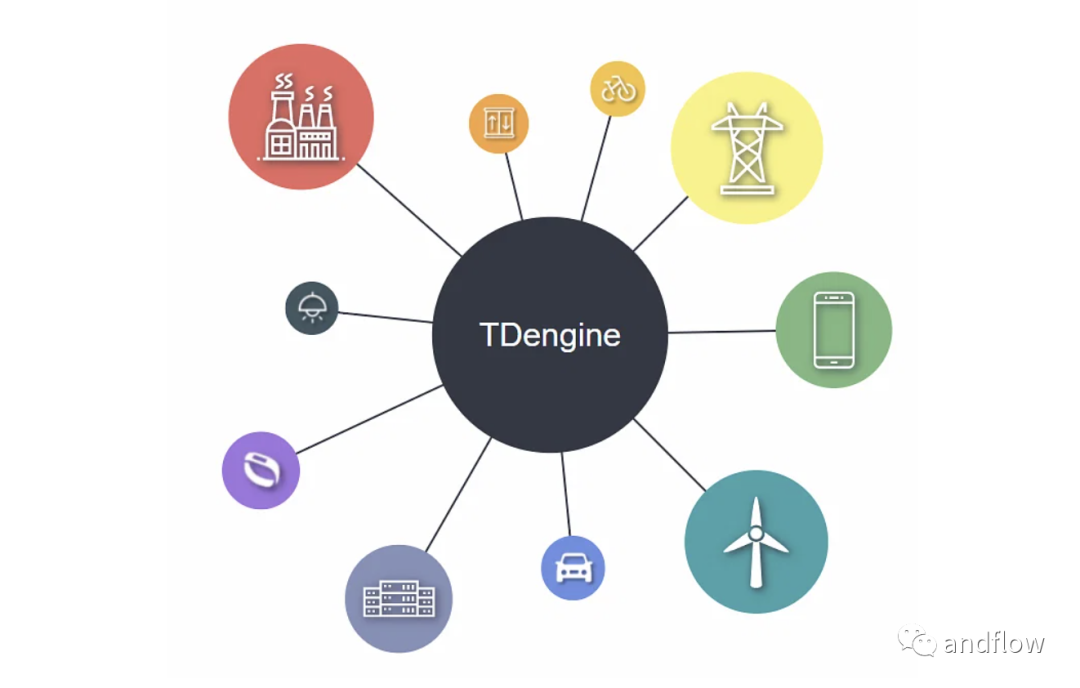
TDengine是一個用于物聯網、聯網汽車和工業物聯網的開源大數據平臺。它的應用場景可以包括:機器人、電梯、 石油/天然氣開采、智能家居、汽車互聯網、電網、互聯網接入記錄、電話、金融交易以及水、空氣之類的環境監測等。它集成了緩存、流計算、消息隊列等功能,以降低開發的復雜性和成本,此外還附帶了時間序列數據庫。低云服務成本、全棧時序數據、強大的數據分析、與其他工具的無縫集成、零管理、無學習曲線是TDengine的突出亮點。
6.Apache Spark
https://github.com/apache/spark
Apache Spark是一個開源的分布式計算框架。它帶有集群的編程接口,包括SQL、機器學習、實時數據流、圖形處理等功能,這使其擁有快速大數據處理能力。Apache Spark的核心是Spark Core,它建立在RDD抽象之上。
Spark SQL使用DataFrames來容納結構化和半結構化數據。Spark可以在集群模式或Hadoop YARN,EC2,Mesos,Kubernetes等環境上運行,因此可以說非常通用。
可以通過非關系型數據庫訪問數據,例如:Apache Cassandra、Apache HBase、Apache Hive或者Hadoop分布式文件系統等。
Apache Spark還可以根據歷史或實時數據來執行實時判斷,因此非常適合預測分析,欺詐檢測,情感分析等應用程序。
7.Presto
https://github.com/prestodb/presto

Presto是一個開源的分布式SQL查詢引擎。它使用戶能夠對從GB到PB的各種大小的數據源運行交互式分析查詢。為交互式分析而構建是它的設計初衷,使得它可以擴展到類似Facebook的規模,同時又能夠保證具備接近商業數據倉庫的速度。Presto允許查詢的數據庫包括:Hive、Cassandra、關系數據庫甚至定制數據存儲等。Presto可以在一個查詢中聚合來自多個數據源,支持對整個企業的數據進行分析。
但Presto在使用時也存在一些缺點,例如:它不支持大的實體連接、缺乏UDF(用戶定義的函數)支持等。
8.Apache Zeppelin
https://github.com/apache/zeppelin

Apache Zeppelin是一款多用途筆記本,支持數據提取、數據發現、數據分析、數據可視化和數據協作。可以作為Apache Spark的前端Web產品,允許無縫與Spark應用程序對接。Zeppelin 解釋器允許任何數據處理后端對接到Zeppelin,支持Spark、Markdown、Python、Shell和JDBC等。它提供了單用戶和多用戶兩種部署類型。Zeppelin的最新創新包括:Zeppelin SDK,改進的Spark Interpreter,Flink Interpreter,Yarn Interpreter Mode,Inline Configuration,Interpreter Lifecycle Management。
Zeppelin也存在一些缺點,例如:UI BUG、缺乏對個別庫的支持、有限的可視化配置等。
9.CMAK
https://github.com/yahoo/CMAK
CMAK是Cluster Manager for Apache Kafka的縮寫,以前稱為Kafka Manager,是Apache Kafka集群的管理工具。該項目目前由Verizon Media和社區共同管理。CMAK的主要功能包括:多集群管理、集群狀態檢查、運行首選副本選舉、生成具有選擇代理的選項的分區分配、運行分區重新分配(基于生成的分配)、刪除主題、批量生成分區分配、批量運行多個主題的分區重新分配、添加分區或更新現有主題的配置等等。
CMAK最顯著的優點是它的分區重新分配功能,但它在Ops任務的限制方面相對就是個缺點。
10.Cython
https://github.com/cython/cython

Cython是Python編程語言的靜態優化器。使得為Python構建C擴展與編寫Python本身一樣簡單。Cython結合了Python和C的強大功能,支持編寫隨時在原生C和C++代碼之間來回切換的Python代碼。
通過在Python語法中引入靜態類型聲明,可以快速將可理解的Python代碼優化為純C語言以提高性能。使用集成的源代碼級調試,可以識別Python、Cython和C代碼中存在的問題。開發人員可以在廣泛且成熟的CPython生態系統中快速構建應用程序。
Cython編程語言也可以稱為Python的超集,它允許在python上運行C函數并在變量和類屬性上聲明C類型,使編譯器能夠通過Cython代碼構建C代碼。
Cython的主要缺點包括:Cython代碼不能獨立重用。除此之外,通過Cython編譯輸出的C語言在大多數情況下都無法達到手動調優的C語言的速度。
11.CatBoost
https://github.com/catboost/catboost

CatBoost是一種機器學習決策樹梯度算法。是一個開源庫。它由Yandex的研究人員和工程師開發,并被Yandex和其他組織(如CERN,Cloudflare和Careem出租車)用于搜索引擎、推薦系統、個人助理、自動駕駛汽車、天氣預測等應用場景。
CatBoost的功能包括:支持無需參數調整的高質量模型訓練,支持分類、實現有序增強、支持GPU版本、支持缺失值、出色的可視化、高度準確性和快速預測能力。
CatBoost是解決異構數據問題的優秀解決方案,但對于處理同構數據的情況,它可能不是最好的學習器。預處理、預測時間和模型分析是Catboost的強項,而訓練和優化時間則是其弱點。
12.Apache CouchDB
https://github.com/apache/couchdb

Apache CouchDB數據庫于2005年由Apache Software Foundation發布。CouchDB使用Erlang開發。支持將數據存儲在JSON中,使用MapReduce在JavaScript中執行查詢,并通過HTTP提供API。因此,CouchDB非常適合當前的移動的應用程序。使用CouchDB的增量復制,可以高效地傳輸數據,CouchDB允許主——主配置與自動沖突檢測。CouchDB的動態文檔轉換和實時更改通知等功能可以使Web開發更加簡單。
CouchDB的主要缺點包括:資源消耗較大、動態查詢耗時、大型數據集臨時視圖長耗時、缺乏事務支持、大型數據庫復制的偶爾會失敗。
13.Apache Airflow
https://github.com/apache/airflow

Apache Airflow是一個編程的框架,用于自動編寫、調度和監控Beam數據管道。Beam數據管道是動態的,因為它們是通過編程構建的,所以我們可以使用Airflow的可視化圖形或有向無環圖(DAG)創建工作流任務。Airflow還提供了一個用戶界面,可以輕松地實現生產中管道的可視化,便于調試問題,跟蹤管道進度。它另一個優勢是它的可擴展性,支持構建自己的操作符,并將庫擴展到您的環境所需的抽象級別。
但是Airflow沒有數據管道的版本控制,對新用戶來說不太直觀,開始很容易就配置過載,難以在本地使用。
14.Trino
https://github.com/trinodb/trino

Trino是一個分布式SQL查詢引擎。支持從異構數據源查詢大型數據集。Trino旨在解決數據倉庫的聯機分析處理(OLAP)問題,包括:數據分析、聚合和報告生成等。可以有效地查詢分析大量數據。在Hadoop和HDFS運行環境下,Trino可以作為MapReduce功能查詢HDFS,有點像Hive或Pig。Trino并不限于支持對HDFS的訪問,也支持其他數據源,包括傳統的關系數據庫和Cassandra等。
特里諾的一個重大缺陷是,如果查詢所占用的內存超過集群可用的內存,查詢將失敗。不過,得益于其容錯能力,查詢引擎將重試查詢而不是直接報告失敗。
15.Delta Lake
https://github.com/delta-io/delta

Delta Lake 開源項目主要用于數據湖的數據倉庫設計。Delta Lake可以在現有的數據湖(如S3,ADLS,GCS和HDFS)之上,運行ACID事務、擴展的元數據處理,并且可以統一流和批處理數據。Delta Lake的主要功能包括ACID事務、可擴展的元數據處理、數據版本控制、開放的格式、統一的批處理、數據源和接收器流程化、強制執行模式、演進模式、歷史審計、更新和刪除、與Apache Spark API的100%兼容性和delta Sharing。
目前已經有許多公司在使用Delta Lake處理EB數據,例如:Databricks、維亞康姆、阿里巴巴集團、McAfee、Upwork、eBay、Informatica等等。
16.Apache Cassandra
https://github.com/apache/cassandra

Apache Cassandra是一個高可擴展性的數據庫,可以在商業基礎設施上運行,并且具有較高容錯性,可以在多個節點上自動復制數據,支持在不關閉系統的情況下替換損壞的節點。Cassandra是一個NoSQL數據庫,其中所有節點都是對等節點,而不是主從架構。這使得它具有高度的可擴展性和容錯性,并且允許您添加更多的新機器而不中斷現有應用程序。可以選擇同步復制和異步復制以完成每次更新。目前像蘋果、Netflix、Instagram、Spotify和Uber這些大公司都在使用Cassandra。
但Cassandra不支持ACID屬性,不支持聚合、延遲、連接、數據復制、緩慢讀取、VM內存管理,這些都是Apache Cassandra的缺點。
17.Vespa
https://github.com/vespa-engine/vespa

Vespa是一個用于海量數據集的低延遲計算引擎。它通過索引支持在服務時可以對其進行查詢、選擇和處理。通過Vespa內的應用組件,使應用程序開發人員能夠構建后端以及中間件系統,這些系統可擴展以快速并可靠地處理大量數據。Vespa實例由幾個無狀態Java容器集群和一個或多個數據存儲節點集群組成。Vespa在文本搜索、推薦、個性化、問答、半結構化導航等許多應用場合中被廣泛應用。
18.Apache Calcite
https://github.com/apache/calcite

Apache Calcite是一個用于管理動態數據的全棧工具。它是一個開源的數據庫和數據管理框架。它附帶了一個SQL解析器、一個用于創建關系代數表達式的API和一個查詢計劃引擎。
盡管它包含許多標準數據庫管理系統的組件,但還是缺幾個關鍵特性,如:數據存儲、數據處理方法和元數據存儲庫。Calcite的優點包括:查詢解析器、驗證器、優化器、用于閱讀JSON格式模型的輔助工具、眾多標準函數、聚合函數、Linq 4j的JDBC查詢、JDBC后端、Linq 4j前端和SQL特性等。
19.DataHub
https://github.com/linkedin/datahub

DataHub是第三代現代數據棧的開源元數據平臺,這個可擴展的元數據平臺旨在幫助開發人員駕馭其快速發展的數據生態系統的復雜性,并幫助數據從業者在其組織內利用數據的最大價值。 它每天可以處理超過1000萬個實體關系更改事件,并索引總計超過500萬個實體和關系。與毫秒級SLA服務運營元數據查詢一起完成,從而實現元數據管理具備高效率、合規性和流程化的特點。DataHub是一個現代化的數據平臺,支持端到端的數據發現、數據可觀察性和數據治理。
LinkedIn目前使用了DataHub來部署數據集、模式、流、合規性注釋、GraphQL端點、指標、儀表板、功能和AI模型。使DataHub在實戰方面經得起考驗。
20.Koalas
https://github.com/databricks/koalas

Koalas項目在Apache Spark的基礎上實現了pandas DataFrame API功能,使數據科學家在處理海量數據時更有效率。Spark是大數據處理的事實標準,而pandas是Python中事實標準(單節點)DataFrame實現。如果你已經熟悉了pandas,你可以立即使用Spark與Koalas,沒有多少學習曲線。使用Koalas可以讓用戶直接與pandas一起測試較小的數據集,也可以與Spark一起測試較大的分布式數據集。
由于開源社區在幾個頻繁的版本中不斷貢獻,Koalas中pandas API的覆蓋率迅速增加,并且增加了spark訪問器、提升了類型提示支持、更廣泛的繪圖支持、更全面的就地更新支持、更好的缺失值支持等。