推薦九個優秀的 Github 開源項目
大家好,我是Echa。
最近這段時間小編陸續收到粉絲們的私信,提到的最多的問題就是有沒有非常優秀的開源項目推薦,有沒有AI相關的開源項目推薦,有沒有的ChatGPT開源項目推薦等等。說句話實話,優化開源項目不是那么容易能找到,不是百里挑一,那也是幾十挑一。即使找到了還得自身要了解,而且還得抽空搭建部署成功后,才整理出來分享給粉絲們。
小編也是隨著粉絲們的意愿,百忙之中精選了9個優秀的Github 開源項目,希望對大家學習有所幫助。
全文大綱
- transformers 提供了數以千計的預訓練模型
- Open Chat Video Editor 是開源的短視頻生成和編輯工具
- yuzu 是基于 C++ 的 Switch 模擬器
- Ryujinx 是基于 C# 的任天堂 Switch 模擬器
- Chat2DB 一個集成了AIGC的數據庫客戶端工具
- privateGPT 你的私人 GPT
- WebCPM 一個使用中文預訓練模型進行互動網頁搜索的項目
- gpt4free 變相「開源」GPT-4
- ChatGPT-Prompt-Engineering-for-Developers-in-Chinese 面向開發者的 ChatGPT 提示詞工程
transformers 提供了數以千計的預訓練模型
官網:https://huggingface.co
Github:https://github.com/huggingface/transformers

Hugging Face 官網
Hugging Face,作為 AI 開源圈最為知名的「網紅」創業公司,成立僅幾年,便在 GitHub 開源了諸多實用開源項目,受到了不少開發者的贊賞。
其中影響力最大的,也被很多人稱為初代 GPT 的 Transformers,截至今天,GitHub Star 累積將近 10 萬。
這幾年,在 Hugging Face 平臺上面誕生了無數實用的 AI 預訓練模型、數據集。數量之多,品質之高,將其說是 AI 界的 GitHub 也不為過。
今天凌晨,Hugging Face 重磅推出 Transformers Agents,在 AI 技術圈再次掀起波瀾!
所有人都可以基于該功能,輕松使用 OpenAssistant、StarCoder、OpenAI 等大語言模型,快速創建一個 AI 智能代理。
Transformers 提供了數以千計的預訓練模型,支持 100 多種語言的文本分類、信息抽取、問答、摘要、翻譯、文本生成。它的宗旨是讓最先進的 NLP 技術人人易用。
Transformers 提供了便于快速下載和使用的API,讓你可以把預訓練模型用在給定文本、在你的數據集上微調然后通過 model hub 與社區共享。同時,每個定義的 Python 模塊均完全獨立,方便修改和快速研究實驗。
Transformers 支持三個最熱門的深度學習庫: Jax, PyTorch 以及 TensorFlow — 并與之無縫整合。你可以直接使用一個框架訓練你的模型然后用另一個加載和推理。

為什么要用 transformers?
- 便于使用的先進模型:
- NLU 和 NLG 上表現優越
- 對教學和實踐友好且低門檻
- 高級抽象,只需了解三個類
- 對所有模型統一的API
- 更低計算開銷,更少的碳排放:
- 研究人員可以分享已訓練的模型而非每次從頭開始訓練
- 工程師可以減少計算用時和生產環境開銷
- 數十種模型架構、兩千多個預訓練模型、100多種語言支持
- 對于模型生命周期的每一個部分都面面俱到:
- 訓練先進的模型,只需 3 行代碼
- 模型在不同深度學習框架間任意轉移,隨你心意
- 為訓練、評估和生產選擇最適合的框架,銜接無縫
- 為你的需求輕松定制專屬模型和用例:
- 我們為每種模型架構提供了多個用例來復現原論文結果
- 模型內部結構保持透明一致
- 模型文件可單獨使用,方便魔改和快速實驗
什么情況下我不該用 transformers?
- 本庫并不是模塊化的神經網絡工具箱。模型文件中的代碼特意呈若璞玉,未經額外抽象封裝,以便研究人員快速迭代魔改而不致溺于抽象和文件跳轉之中。
- Trainer API 并非兼容任何模型,只為本庫之模型優化。若是在尋找適用于通用機器學習的訓練循環實現,請另覓他庫。
- 盡管我們已盡力而為,examples 目錄中的腳本也僅為用例而已。對于你的特定問題,它們并不一定開箱即用,可能需要改幾行代碼以適之。

Transformers Agents 里面提供了諸多實用的工具,包括目前 AI 技術應用廣泛的文檔問答、文本轉語音、文本生成圖像、網站內容總結、圖像分割等一系列工具。
開發者只需完成工具鏈組裝,即可實現許多強大的功能。
比如,你可以通過它,快速實現這么一個功能:
用腳本根據鏈接,自動抓取某篇文章內容,并生成摘要,再將其翻譯成任意一種語言,讓 AI 朗讀稿件,有需要的話,你還可以讓代理為你生成一張配圖。
一個基于 AI 能力,可快速報道各種新鮮資訊的播客系統,便能橫空出世!
如下圖:

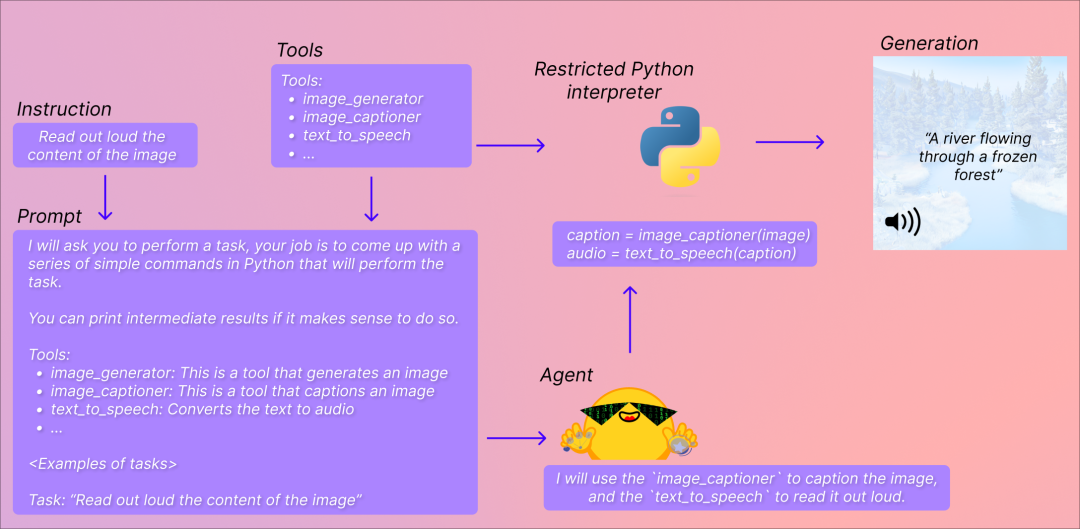
transformers 實現流程圖
Open Chat Video Editor
Github:https://github.com/SCUTlihaoyu/open-chat-video-editor
Open Chat Video Editor 是基于 AI 的短視頻創作工具,解放你的生產力。基于 ChatGPT、Alpaca 等大模型,可以將短文本、網頁鏈接一鍵轉成短視頻。
如下圖是技術框架圖:整體流程是將短文本輸入到模型,來生成文案。通過圖像搜索、圖像 AI 生成技術來尋找配圖,通過視頻搜索、視頻生成等技術來找合適的視頻片段,最終通過語音合成、BGM 匹配、字幕合成打造一個短視頻作品。
Open Chat Video Editor是開源的短視頻生成和編輯工具,整體技術框架如下:
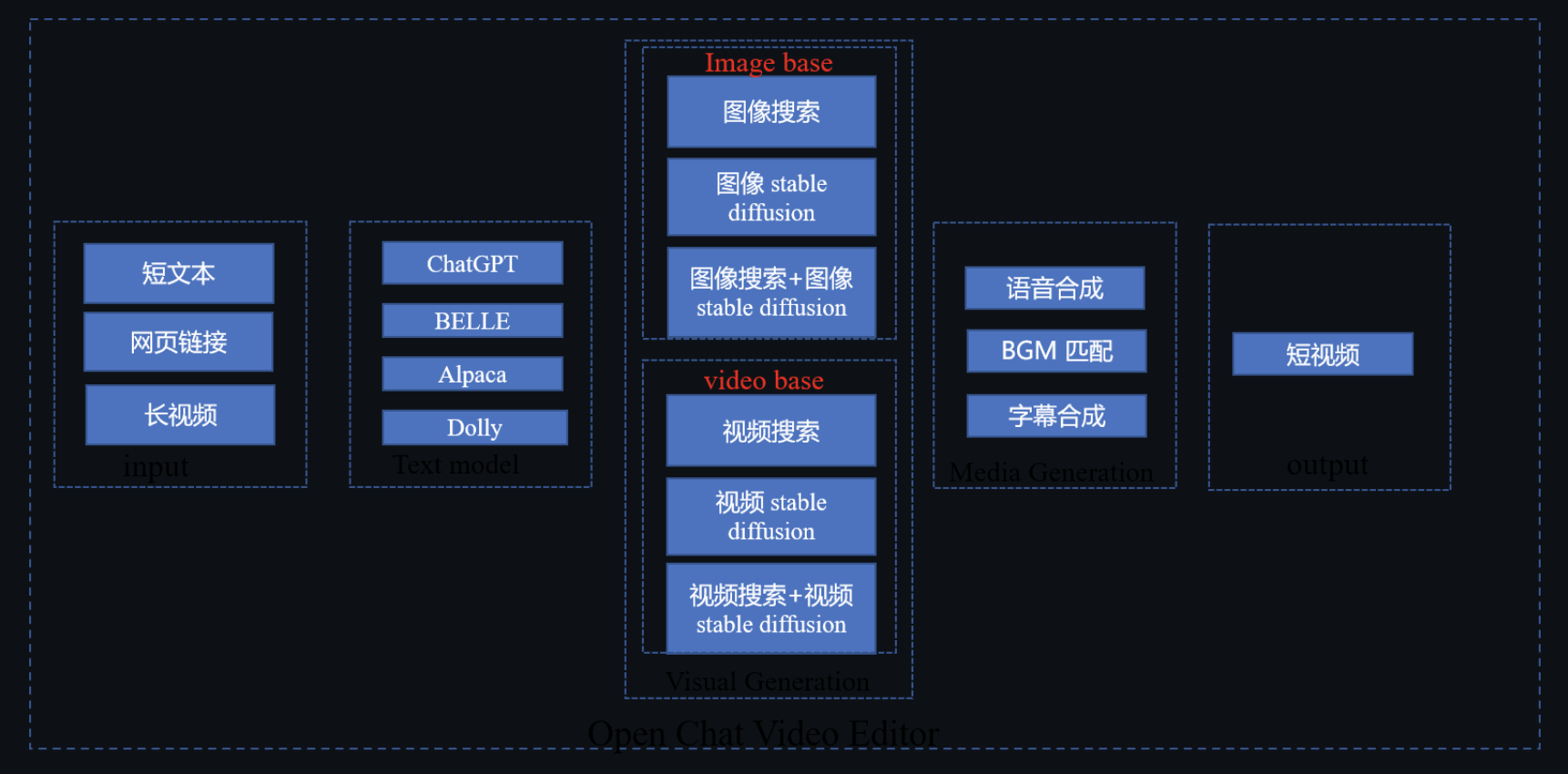
Open Chat Video Editor 技術框架
特性
- windows、linux不同系統更方便的install指引
- 創建docker,方便大家一鍵使用
- 能夠在線直接快速體驗的url
- 在短視頻文案數據上對文本模型finetune,支持更多的文案風格
- finetune SD模型,提升圖像和視頻的生成效果
目前具有以下特點:
- 1)一鍵生成可用的短視頻,包括:配音、背景音樂、字幕等。
- 2)算法和數據均基于開源項目,方便技術交流和學習
- 3)支持多種輸入數據,方便對各種各樣的數據,一鍵轉短視頻,目前支持:
- 短句轉短視頻(Text2Video): 根據輸入的簡短文字,生成短視頻文案,并合成短視頻
- 網頁鏈接轉短視頻(Url2Video): 自動對網頁的內容進行提取,生成視頻文案,并生成短視頻
- 長視頻轉短視頻(Long Video to Short Video): 對輸入的長視頻進行分析和摘要,并生成短視頻
- 4)涵蓋生成模型和多模態檢索模型等多種主流算法和模型,如: Chatgpt,Stable Diffusion,CLIP 等
文本生成上,支持:
- ChatGPT
- BELLE
- Alpaca
- Dolly 等多種模型
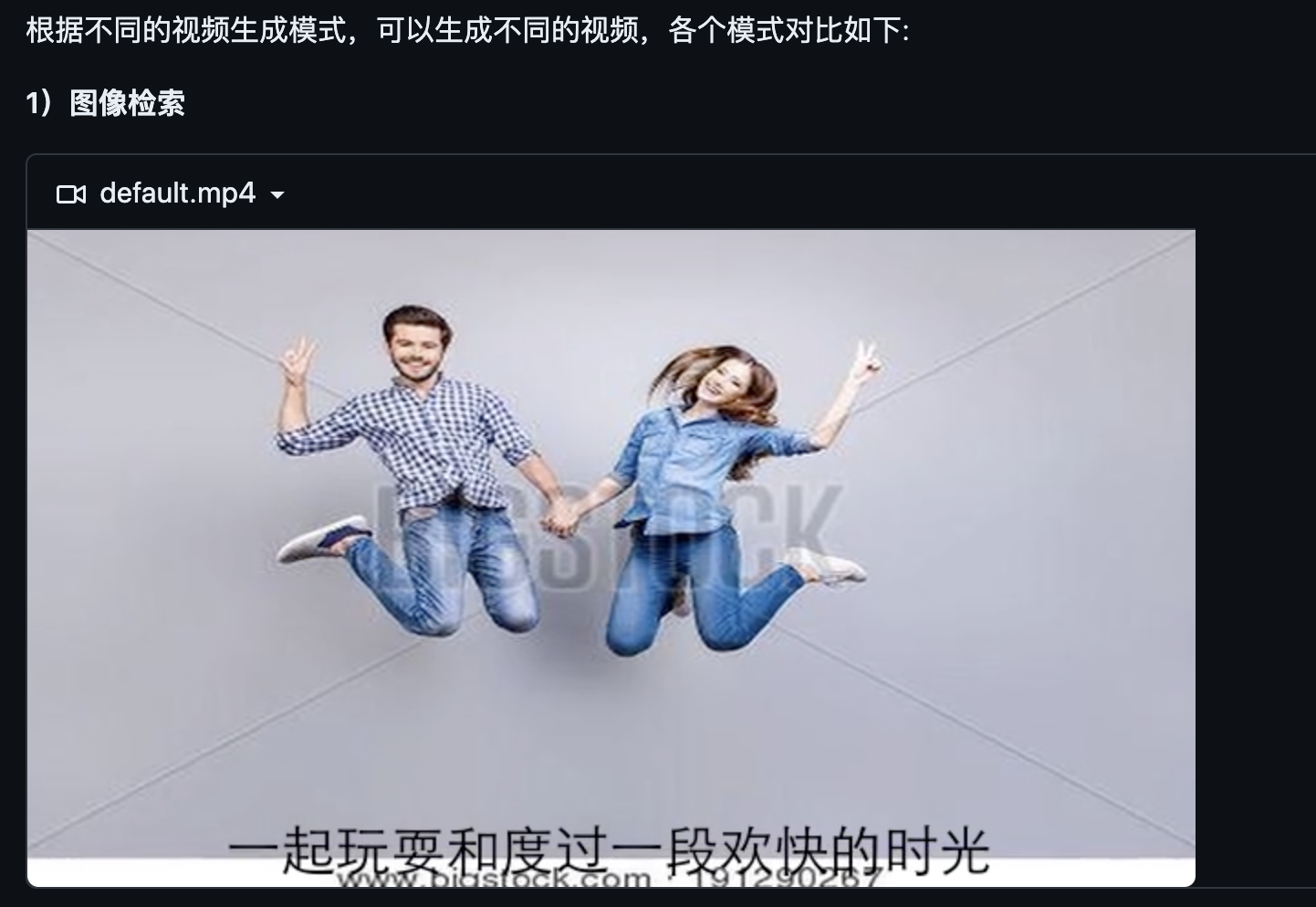
視覺信息生成上,支持圖像和視頻兩種模態,生成方式上,支持檢索和生成兩種模型,目前共有6種模式:
- 圖像檢索
- 圖像生成(stable diffusion)
- 先圖像檢索,再基于stable diffusion 進行圖像生成
- 視頻檢索
- 視頻生成(stable diffusion)
- 視頻檢索后,再基于stable diffusion 進行視頻生成
效果圖如下:
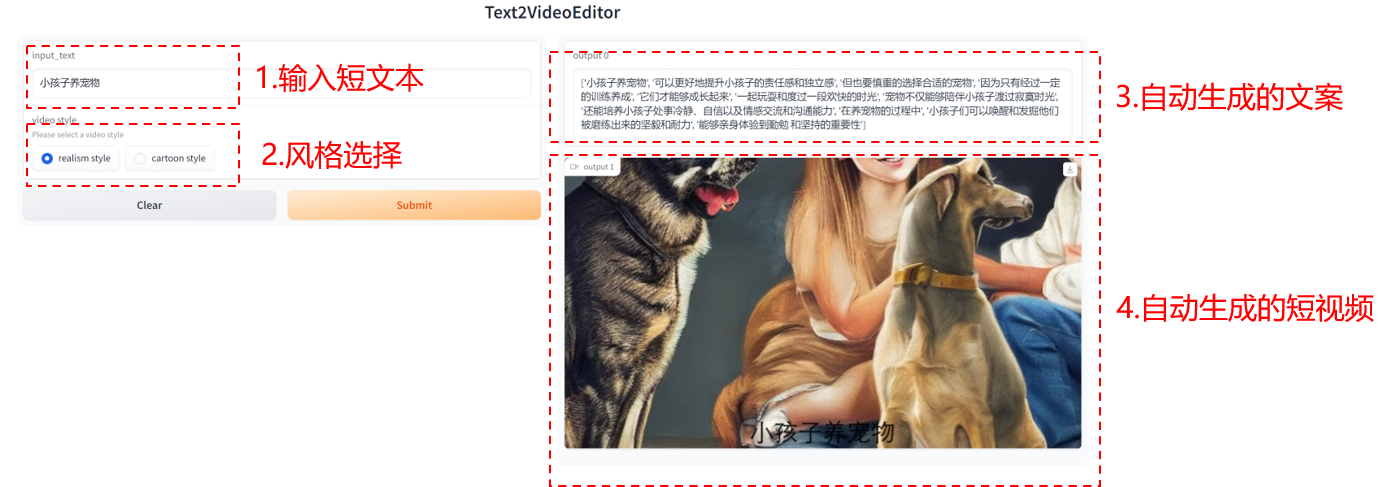
短句轉短視頻

yuzu 是基于 C++ 的 Switch 模擬器
官網:https://yuzu-emu.org/
Github: https://github.com/yuzu-emu/yuzu
yuzu是世界上最受歡迎的開源任天堂Switch模擬器,由Citra的創建者創建。
它是用C++編寫的,考慮到了可移植性,我們積極維護Windows和Linux的構建。
應該是因為 塞爾達·王國之類 游戲的發布, Switch 模擬器相關的開源項目都登上了 GitHub 熱榜。
yuzu 是基于 C++ 的 Switch 模擬器,能夠在 Windows、Linux 上運行模擬 Switch 游戲,目前已經獲得了 26K 的 Star。
Ryujinx 是基于 C# 的任天堂 Switch 模擬器
官網:https://ryujinx.org/
Github: https://github.com/Ryujinx/Ryujinx
應該是因為 塞爾達·王國之類 游戲的發布, Switch 模擬器相關的開源項目都登上了 GitHub 熱榜。
其中,Ryujinx 是基于 C# 的任天堂 Switch 模擬器,通過這個模擬器你能在 Windows 上玩 Switch 上的游戲,目前已經獲得了 21.7K 的 Star。
Chat2DB 一個集成了AIGC的數據庫客戶端工具
官網:http://www.sqlgpt.cn/
Github:https://github.com/alibaba/Chat2DB
Chat2DB 是一款有開源免費的多數據庫客戶端工具,支持windows、mac本地安裝,也支持服務器端部署,web網頁訪問。和傳統的數據庫客戶端軟件Navicat、DBeaver 相比Chat2DB集成了AIGC的能力,能夠將自然語言轉換為SQL,也可以將SQL轉換為自然語言,可以給出研發人員SQL的優化建議,極大的提升人員的效率,是AI時代數據庫研發人員的利器,未來即使不懂SQL的運營業務也可以使用快速查詢業務數據、生成報表能力。
?特性
- AI智能助手,支持自然語言轉SQL、SQL轉自然語言、SQL優化建議
- 支持團隊協作,研發無需知道線上數據庫密碼,解決企業數據庫賬號安全問題
- ?? 強大的數據管理能力,支持數據表、視圖、存儲過程、函數、觸發器、索引、序列、用戶、角色、授權等管理
- 強大的擴展能力,目前已經支持MySQL、PostgreSQL、Oracle、SQLServer、ClickHouse、OceanBase、H2、SQLite等等,未來會支持更多的數據庫
- 前端使用 Electron 開發,提供 Windows、Mac、Linux 客戶端、網頁版本一體化的解決方案
- 支持環境隔離、線上、日常數據權限分離

privateGPT 你的私人 GPT
Github:https://github.com/imartinez/privateGPT
privateGPT 開源兩周,便斬獲了 10K 的 Star。可以在離線的情況下,使用 GPT 來處理你的私人文檔,完全不需要網絡,本地化運行。
讓 privateGPT 處理你的文檔,然后就能通過對話的方式讓 GPT 分析文檔給出答案。

WebCPM 一個使用中文預訓練模型進行互動網頁搜索的項目
Github:https://github.com/thunlp/WebCPM
2021 年 12 月,OpenAI 正式推出 WebGPT,該項目的橫空出世,標志著基于網頁搜索的問答新范式的誕生。
在此之后,New Bing 首先將網頁搜索功能整合發布,隨后 OpenAI 也發布了支持聯網的插件 ChatGPT Plugins。
大模型在聯網功能的加持下,回答問題的實時性和準確性都得到了飛躍式增強。
近期,面壁智能聯合來自清華、人大、騰訊的研究人員共同發布了 中文領域首個基于交互式網頁搜索的問答開源模型框架 WebCPM,相關工作錄用于自然語言處理頂級會議 ACL 2023。
WebCPM 是面壁智能自研大模型工具學習引擎 BMTools 的首個成功實踐,其特點在于其信息檢索基于交互式網頁搜索,能夠像人類一樣與搜索引擎交互從而收集回答問題所需要的事實性知識并生成答案。
WebCPM 背后的基礎模型 CPM 是由面壁智能與 OpenBMB 開源社區開發的百億參數中文語言模型,占據多個中文領域語言模型排行榜前列。

WebCPM 研究背景
在當今信息化時代,人們在日常生活和工作中,需要不斷地獲取各種知識和信息,而這些信息往往分散在互聯網上的海量數據中。
如何快速、準確地獲取這些信息,并且對這些信息進行合理的整合,從而回答復雜、開放式問題,是一個極具挑戰性的問題。長文本開放問答(Long-form Question Answering, LFQA)模型就是為了回答這種復雜的問題而設計的。
目前的 LFQA 解決方案通常采用 檢索-綜合 范式,包括信息檢索和信息綜合兩個核心環節。信息檢索環節從外部知識源(如搜索引擎)中搜索多樣化的相關支持事實,信息綜合環節則將搜集到的事實整合成一個連貫的答案。
然而,傳統的 LFQA 范式存在一個缺陷:它通常依賴于非交互式的檢索方法,即 僅使用原始問題作為查詢語句來檢索信息。
相反,人類能夠通過與搜索引擎 實時交互 來進行網頁搜索而篩選高質量信息。對于復雜問題,人類往往將其分解成多個子問題并依次提問。通過識別和瀏覽相關信息,人類逐漸完善對原問題的理解,并不斷查詢新問題來搜索更多樣的信息。
這種迭代的搜索過程有助于擴大搜索范圍,提高搜索結果質量。總體而言,交互式網頁搜索不僅為我們提供了獲取多樣化信息來源的途徑,同時也反映了人類解決問題的認知過程,從而提高了可解釋性。
2021 年 12 月 OpenAI 發布 WebGPT,這是支持 LFQA 的交互式網頁搜索的一項先驅性工作。
作者首先構建了一個由微軟必應搜索(Bing)支持的網頁搜索界面,然后招募標注員使用該界面收集信息來回答問題。
之后,他們微調 GPT-3 模型,讓其模仿人類的搜索行為,并將收集到的信息整理成答案。實驗結果顯示,WebGPT 在 LFQA 任務具備出色的能力,甚至超過了人類專家。
同時,WebGPT 也是微軟近期推出的 New Bing 背后的新一代搜索技術。
盡管效果十分驚人,但 WebGPT 、New Bing 對學術圈和工業界來說仍然充滿神秘感。這是因為 WebGPT 的相關細節并未完全公開,其核心設計元素的工作原理也不透明。
鑒于當前交互式網頁搜索的重要價值,我們迫切需要一個標準數據集與相關的開源模型以支持后續研究。
WebCPM 搜索交互界面和數據集
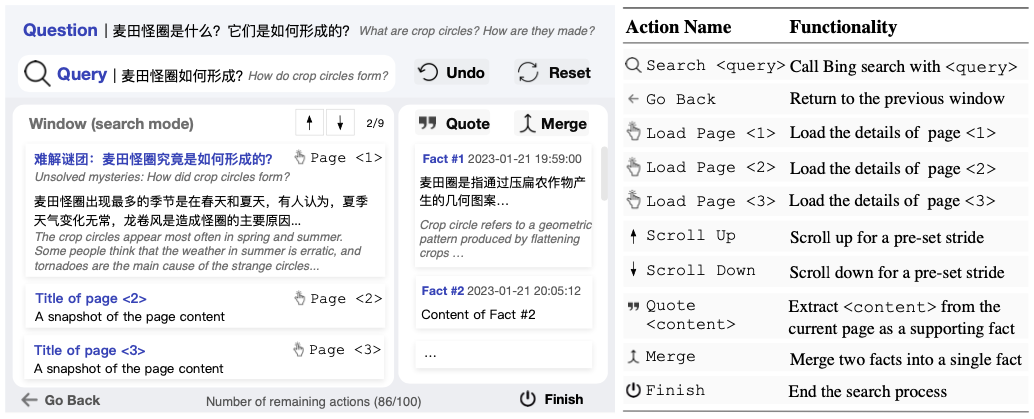
WebCPM 搜索交互界面和數據集
為推動相關領域發展,這篇 ACL 論文的研究團隊首先構建了一個 開源的交互式網頁搜索界面,用于記錄人類為開放式問題收集相關信息時的網頁搜索行為。
該界面底層調用必應搜索 API 支持網頁搜索功能,囊括 10 種主流網頁搜索操作(如點擊頁面、返回等等)。
在這個界面中,用戶可以執行預定義的操作來進行多輪搜索和瀏覽。在找到網頁上的相關信息時,他們可以將其作為支持事實記錄下來。
當收集到足夠的信息后,用戶可以完成網頁搜索,并根據收集到的事實來回答問題。同時,界面會自動記錄用戶的網頁瀏覽行為,用于構建 WebCPM 數據集。
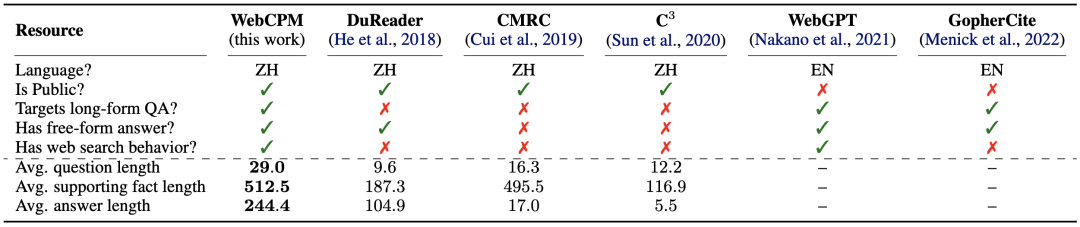
WebCPM 數據集與相關問答數據集的比較
基于這個界面,作者構建了中文領域首個基于交互式網頁搜索的 LFQA 數據集。
它包含 5,500 對高質量的問題-答案對以及十萬多條真實用戶網頁搜索行為。與現有的中文問答數據集相比,WebCPM 的問題、支持事實和答案都更長,體現了其問題的復雜性和答案內容的豐富性。
WebCPM 模型框架
作者提出了的 WebCPM 框架包括:(1)搜索模型與(2)答案綜合模型。
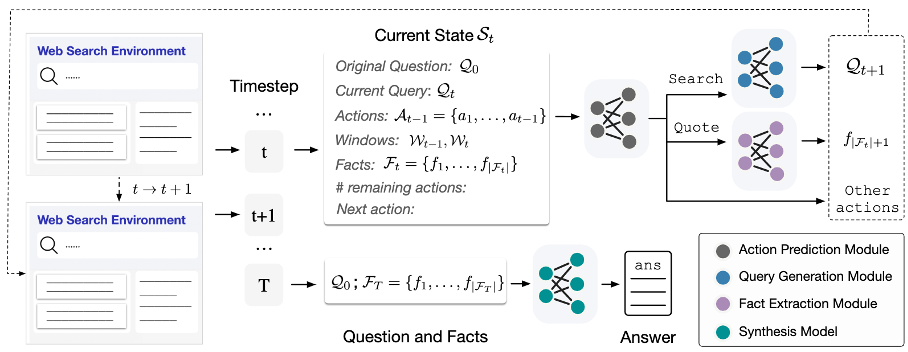
WebCPM 模型框架
搜索模型
該模型模仿人類網頁搜索行為、與搜索引擎交互并進行信息檢索。作者將網頁搜索任務劃分為 3 個子任務:
- 搜索行為預測(action prediction);
- 查詢語句生成(search query generation);
- 支持事實摘要(supporting fact extraction)。
答案綜合模型
該模型根據原問題與收集到的事實生成連貫的答案。然而與人類不同,經過訓練的搜索模型偶爾會收集到不相關的噪聲,這將影響生成答案的質量。
為了解決這一問題,作者在答案綜合模型的訓練數據中引入噪聲,使其具備一定的去噪的能力,從而忽略不相關的事實,只關注重要的事實以生成答案。
WebCPM 實驗評測
作者首先對每個子模塊分別評估,然后,將所有模塊組合起來形成整體的 pipeline,并測試其效果。最后,作者對每個模塊的性能進行深入分析。
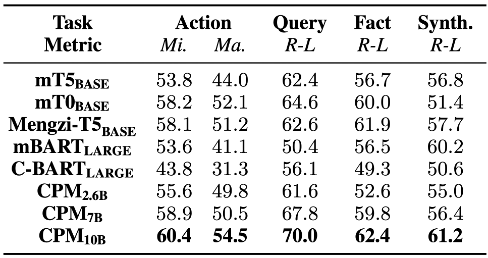
單個子任務的性能評估結果,作者測試了包括 CPM 模型在內的多個有代表性的中文大模型
- 單個子任務評估
作者測試了多個有代表性的中文大模型,并得出以下結論(結果如上圖所示):不同模型在四個子任務上的性能各有優劣。
例如在搜索行為預測、查詢語句生成和支持事實摘要中,mT0 的表現優于 mT5,但在綜合信息方面表現較差。
此外,CPM 系列模型的性能隨著模型參數量的增加也不斷提高。得益于 scaling law ,更大的模型通常擁有更強的理解和生成能力,能表現出更好的下游任務性能。
- 整體 pipeline 評測
對于每個測試問題,作者比較了模型(CPM 10B 模型)和人類用戶使用搜索引擎回答問題和做相同任務的表現,并進行人工評測。
具體而言,給定一個問題和模型與人類分別給出的答案,標注員將根據多個因素(包括答案整體實用性、連貫性和與問題的相關性)決定哪個答案更好。
從下圖(a)的結果可以得出以下結論:模型生成的答案在 30%+ 的情況下與人寫的答案相當或更優。
這個結果表明整個問答系統的性能在未來仍有巨大的提升空間(例如訓練性能更加強大的基底模型);當將人工收集的事實應用于信息綜合模型時,性能提高到了45%,這可以歸因于收集的事實質量的提高。
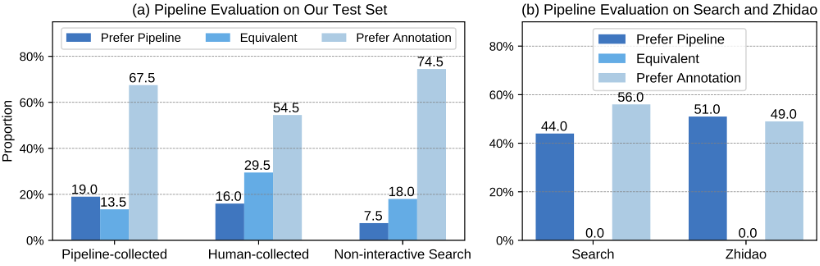
整體 pipeline 評測效果,作者測試了 WebCPM 數據集和 DuReader 數據集
此外,作者也將整體 pipeline 應用于 DuReader 中文 QA 數據集(包含 Zhidao 和 Search 兩個子數據集),并比較了模型生成的答案和人工標注的答案,從上圖(b)可以觀察到模型生成的答案比 DuReader 標注答案更好的情況接近 50%,這反映了該模型強大的泛化能力,體現了WebCPM 數據標注的高質量。
WebCPM 案例分析
為了探究查詢模塊所學習到的人類行為,作者抽樣不同測試問題生成的查詢語句來進行案例分析。下圖展示了部分結果,以研究查詢模塊的性能。
可以看出,該模塊已經學會了復制原始問題,將問題分解為多個子問題,用相關術語改寫問題等多種人類搜索策略。這些策略使查詢語句更加多樣化,有助于從更多的來源收集更豐富的信息。

WebCPM 成功實踐 BMTools
近年來,大模型在諸多領域展現出驚人的應用價值,持續刷新各類下游任務的效果上限。盡管大模型在很多方面取得了顯著的成果,但在特定領域的任務上,仍然存在一定的局限性。
這些任務往往需要專業化的工具或領域知識才能有效解決。因此,大模型需要具備調用各種專業化工具的能力,這樣才能為現實世界任務提供更為全面的支持。
gpt4free 變相「開源」GPT-4
官網:
https://discord.gg/gpt4free
Github:https://github.com/xtekky/gpt4free

圖片來自網絡
眾所周知,ChatGPT 是免費的,但想嘗試最新最強的 GPT-4,基本上就只有「氪金」這一條路可以走——
要么訂閱 ChatGPT Plus,要么付費調用 API。
雖然也有一些集成了 GPT 的網站,比如微軟的必應、You.com 等,但他們多少都會夾帶點私貨。
那么,如果想體驗更加原生的 GPT-4,但又不想花錢怎么辦?
最近,一個名為 GPT 4 Free 項目橫空出世。不僅在 GitHub 上斬獲 18.5 k 星,而且登上了 Trending 周榜。
然而,制作這個項目的 CS 學生 Xtekky 卻表示,OpenAI 現在要求他在五天內關閉整個項目,否則將面臨訴訟。

這其中的矛盾在于,GPT 4 Free 所使用的這些網站本身,都是給 OpenAI 支付了大量費用,才用上的 GPT 模型。
因此,通過腳本進來的查詢,網站不僅要掏腰包買單,而且自己還沒得到任何流量。
如果這個網站是依靠廣告收入來抵消 API 使用成本的話,那么這一通操作下來,就有可能會賠錢。
變相「開源」GPT-4
現在,想要用上 GPT-4,除了直接充會員外,就只能排隊等 API,然后繼續氪金……
而 GPT 4 Free,則可以讓我們通過 You.com、Quora 和 CoCalc 等網站,免費使(bai)用(piao)GPT-4 和 GPT-3.5 模型。
同時,GPT 4 Free 配置起來也非常簡單。
首先,在電腦上的 WSL 2(Windows Subsystem for Linux)安裝 GPT 4 Free。這只需要幾分鐘,包括克隆 GitHub 倉庫,使用 pip 安裝一些必需的庫,以及運行一個 Python 腳本。
啟動腳本后,使用瀏覽器訪問 http://localhost:8501,就可以獲得一個聊天機器人了。
ChatGPT-Prompt-Engineering-for-Developers-in-Chinese 面向開發者的 ChatGPT 提示詞工程
Github:https://github.com/GitHubDaily/ChatGPT-Prompt-Engineering-for-Developers-in-Chinese

ChatGPT 上線至今,已經快 5 個月了,但是不少人還沒真正掌握它的使用技巧。
其實,ChatGPT 的難點,在于 Prompt(提示詞)的編寫,OpenAI 創始人在今年 2 月時,在 Twitter 上說:「能夠出色編寫 Prompt 跟聊天機器人對話,是一項能令人驚艷的高杠桿技能」。
因為從 ChatGPT 發布之后,如何寫好 Prompt 已經成為了一個分水嶺。熟練掌握 Prompt 編寫的人,能夠很快讓 ChatGPT 理解需求,并很好的執行任務。
目前你在網上看到的所有 AI 助理、智能翻譯、角色扮演,本質上還是通過編寫 Prompt 來實現。
只要你的 Prompt 寫的足夠好,ChatGPT 可以幫你快速完成很多工作,包括寫爬蟲腳本、金融數據分析、文案潤色與翻譯等等,并且這些工作還做的比一般人出色。
之前我經常聽到有同學抱怨,說 ChatGPT 也就那樣,我說一句他回一句,并沒有網上說的那么厲害,其實,你確定真正掌握 Prompt 應用了嗎?
打個比方,至今還有不少人,不知道在給 ChatGPT 提供代碼或者翻譯文本時,需要使用引號分隔符來傳給 ChatGPT,讓它輸出更準確的結果。
為了幫助大家能更好的掌握 Prompt 工程,DeepLearning.ai 創始人吳恩達與 OpenAI 開發者 Iza Fulford 聯手推出了一門面向開發者的技術教程:《ChatGPT 提示工程》。
吳恩達老師相信大家都有所耳聞,作為人工智能界的重量級大佬,我們經常能在 AI 技術界看到他活躍的身影。
另一位講師 Iza Fulford,大家可能不太熟悉,這里重點介紹下。
她是斯坦福本碩高材生,ChatGPT 之前在 GitHub 開源的那個文檔搜索插件:Retrieval,就是出自她之手。
另外,她還是 OpenAI Cookbook(官方手冊)的編撰者,如果你最近有深入了解過 GPT 相關的技術,那這本手冊于你而言應該不會陌生。
該手冊里面提供了大量 GPT 相關的使用案例,能幫助你快速上手并掌握 GPT 模型的開發與應用。
可以說,這兩位大佬聯手,推出的教程絕對不會差。更令人振奮的是,這個教程完全對外開放,所有人均可免費學習!
那么,這個教程里面主要講了什么內容呢?
該教程總共分為 9 個章節,總一個多小時,里面主要涵蓋:提示詞最佳實踐、評論情感分類、文本總結、郵件撰寫、文本翻譯、快速搭建一個聊天機器人等等。
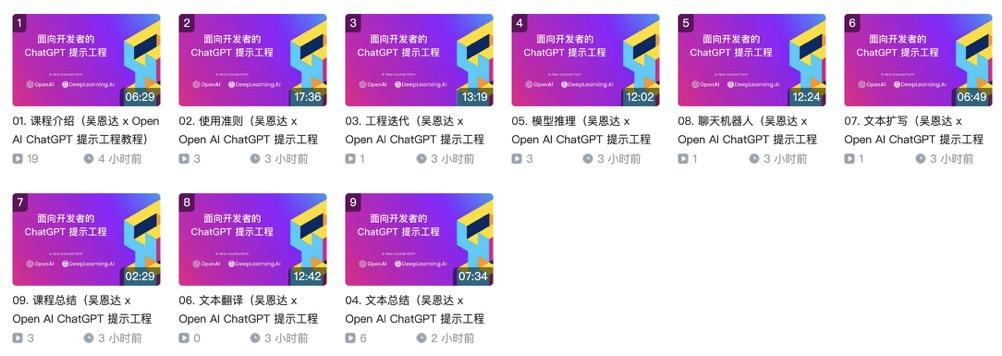
所以當下 ChatGPT 的流行案例,你都能在這個教程里面找到,十分全面!
除了能在這個教程里面學到如何使用 Prompt,你還能學到 GPT 接口調用開發知識。有需要的話,你甚至能在這個教程之上去延伸擴展,搭建出一款令人驚艷的應用。
目前該教程已經在 DeepLearning.ai 正式上線,官網上線提供了可交互式的 Notebook,讓你可以一邊學習,一邊跟著編寫代碼實踐。
不過當下這個教程只有英文版,為了讓看不懂英文的同學也能第一時間學習并掌握這項技術。