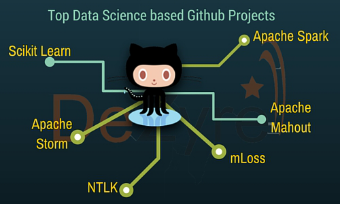
掰一掰GitHub上優(yōu)秀的大數(shù)據(jù)項(xiàng)目
VMware CEO Pat Gelsinger曾說:
| 數(shù)據(jù)科學(xué)是未來,大數(shù)據(jù)分析則是打開未來之門的鑰匙 |
企業(yè)正在迅速用新技術(shù)武裝自己以便從大數(shù)據(jù)項(xiàng)目中獲益。各行業(yè)對(duì)大數(shù)據(jù)分析人才的需求也迫使我們升級(jí)自己的技能以便尋找更好的職業(yè)發(fā)展。
跳槽之前***先搞清楚一個(gè)崗位會(huì)接觸到的項(xiàng)目類型,這樣你才能掌握所有需要的技能,工作的效率也會(huì)更高。
下面我們盡量列出了一些流行的開源大數(shù)據(jù)項(xiàng)目。根據(jù)它們各自的授權(quán)協(xié)議,你或許可以在個(gè)人或者商業(yè)項(xiàng)目中使用這些項(xiàng)目的源代碼。寫作本文的目的也就是為大家介紹一些解決大數(shù)據(jù)相關(guān)問題可能會(huì)用到的工具。
1.Apache Mahout
我 們可以使用Apache Mahout來快速創(chuàng)建高效擴(kuò)展性又好的機(jī)器學(xué)習(xí)應(yīng)用。Mahout結(jié)合了諸如H2O算法、Scala、Spark和Hadoop MapReduce等模塊,為開發(fā)人員提供了一個(gè)構(gòu)建可擴(kuò)展算法的環(huán)境。現(xiàn)在***的版本是去年11月6日發(fā)布的0.11.1版本。
Apache Mahout支持一個(gè)叫做Samsara的數(shù)學(xué)環(huán)境,用戶可以在Samsara中使用它提供的常見算法來開發(fā)自己的數(shù)學(xué)解決方案。Samsara對(duì)于線性 代數(shù)、數(shù)據(jù)結(jié)構(gòu)和統(tǒng)計(jì)操作都有著很好的支持,而且可以通過Scala的Mahout擴(kuò)展或Mahout庫來進(jìn)行定制。Samara對(duì)很多常見算法都進(jìn)行了 重寫因此速度上有一定的提升。這里我們能列出的一些算法包括:樸素貝葉斯分類器、矩陣分解、協(xié)同過濾以及神經(jīng)網(wǎng)絡(luò)。新加入的相似性分析還可以通過分析用戶 的點(diǎn)擊來實(shí)現(xiàn)共現(xiàn)推薦算法。
Apache Mahout GitHub地址:https://github.com/apache/mahout
2.Apache Spark
Apache Spark是一個(gè)為實(shí)時(shí)大數(shù)據(jù)分析所設(shè)計(jì)的開源數(shù)據(jù)處理引擎。目前Spark的大用戶有雅虎、騰訊和百度,使用Spark處理的數(shù)據(jù)在PB級(jí)別,集群節(jié)點(diǎn) 數(shù)目也超過8000。Apache Spark是GitHub上***的數(shù)據(jù)處理項(xiàng)目之一,有超過750名開發(fā)人員都曾對(duì)項(xiàng)目做出過貢獻(xiàn)。
與Hadoop MapReduce相比Apache Spark在內(nèi)存中的運(yùn)行速度快100倍,在硬盤中運(yùn)行速度的差距也在10倍以上。Spark能夠達(dá)到這樣的速度靠的是DAG引擎和內(nèi)存內(nèi)計(jì)算性能的提 升。開發(fā)語言可以使用Java、Python、Scala和R,此外Spark還提供了差不多100種集合操作符以便開發(fā)人員構(gòu)建并行應(yīng)用。

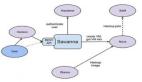
圖:Spark生態(tài)系統(tǒng)
Apache Spark為機(jī)器學(xué)習(xí)、Spark Streaming和GraphX提供了眾多強(qiáng)大的庫,其中也包括為DataFrame和SQL所設(shè)計(jì)的庫。開發(fā)人員可以用這些標(biāo)準(zhǔn)庫來提升應(yīng)用的性能和 開發(fā)效率。Spark可以運(yùn)行于很多環(huán)境中,如獨(dú)立的集群、Hadoop YARN、EC2和Apache Mesos。Apache Spark也能從Hive、HBase、Tachyon、Cassandra和HDFS等數(shù)據(jù)源讀取數(shù)據(jù)。
Apache Spark GitHub地址:https://github.com/apache/spark
3.Apache Storm
Apache Storm的設(shè)計(jì)針對(duì)的是流式數(shù)據(jù),不過對(duì)于大數(shù)據(jù)的實(shí)時(shí)分析它也是很可靠的計(jì)算系統(tǒng)。它同樣是一個(gè)開源項(xiàng)目而且開發(fā)人員可以使用所有的主流高級(jí)語言。 Apache Storm主要用于以下應(yīng)用:在線機(jī)器學(xué)習(xí)、連續(xù)計(jì)算、實(shí)時(shí)分析、ETL、分布式RPC。Apache Storm有配置方便、可用性高、容錯(cuò)性好及擴(kuò)展性好等諸多優(yōu)點(diǎn),處理速度也極快,每個(gè)節(jié)點(diǎn)每秒可以處理數(shù)百萬個(gè)tuple。
目前***的Apache Storm是去年11月5日發(fā)布的0.9.6版。
Storm 集群中有三種節(jié)點(diǎn):Nimbus、Zookeeper和Supervisor。Nimbus與Hadoop的JobTracker類似,主要用于運(yùn)算的上 傳、代碼的分發(fā)和計(jì)算的監(jiān)測(cè)。Zookeeper節(jié)點(diǎn)的作用是Storm集群的協(xié)調(diào),Supervisor節(jié)點(diǎn)則是實(shí)現(xiàn)對(duì)worker的控制。
Apache Storm GitHub地址https://github.com/apache/storm/
4.NTLK(自然語言處理工具箱)
NTLK是用于開發(fā)Python自然語言相關(guān)應(yīng)用的一個(gè)工具包。它自帶用于斷句、分類、標(biāo)記、詞干提取、語義推理和語法分析的庫,此外還有一個(gè)較為活躍的社區(qū)。對(duì)于語言學(xué)的實(shí)證研究、人工智能、認(rèn)知科學(xué)、機(jī)器學(xué)習(xí)和信息提取來說都是強(qiáng)大的工具,當(dāng)然你得用Python。
自動(dòng)補(bǔ)全是NTLK可能的用處之一。輸入部分文字,借助NTLK可以推測(cè)可能的完整句子,現(xiàn)在很多搜索引擎都有這個(gè)功能。其他可能的應(yīng)用還包括文本歸類、地址分析和智能語音命令等。
NTLK GitHub地址:https://github.com/nltk/nltk
5.mLoss
mLoss是機(jī)器學(xué)習(xí)開源軟件的英文縮寫,它將很多開源軟件集合到了同一個(gè)平臺(tái)。mLoss所收集的開源項(xiàng)目都經(jīng)過審閱并附有對(duì)項(xiàng)目的簡(jiǎn)短介紹。mLoss本身并不是一個(gè)軟件而是一個(gè)支持機(jī)器學(xué)習(xí)應(yīng)用開源的網(wǎng)站。
mLoss網(wǎng)站上列出的開源軟件有各自項(xiàng)目不同的48種授權(quán)協(xié)議,作者數(shù)量高達(dá)1100人。mLoss是到目前為止***的機(jī)器學(xué)習(xí)軟件庫,共支持107種數(shù)據(jù)類型,所涉及的操作系統(tǒng)有26個(gè),使用的編程語言也有51種。
mLoss網(wǎng)站上列出的軟件中較為流行的有:
- dlib ml:機(jī)器學(xué)習(xí)算法的C++庫
- R-Cran-Caret:分類和回歸訓(xùn)練庫
- Shogun:為SVM所設(shè)計(jì)的機(jī)器學(xué)習(xí)工具箱,適用于Python、Matlab、Octave和R
- Armadillo:一個(gè)線性代數(shù)C++庫
- MLPY:以NumPy和SciPY為基礎(chǔ)構(gòu)建的Python機(jī)器學(xué)習(xí)庫
- MyMediaLite:一個(gè)推薦器算法庫
- mLoss網(wǎng)站:http://mloss.org/
6.Julia
Julia是為技術(shù)計(jì)算所設(shè)計(jì)的一門動(dòng)態(tài)高級(jí)語言。雖然它的語法和其他技術(shù)計(jì)算環(huán)境的語法差不多,但Julia現(xiàn)在的使用范圍還比較窄。Julia支持分布式并行計(jì)算還有著完備的高精度數(shù)學(xué)函數(shù)庫。
JuliaStats是一個(gè)機(jī)器學(xué)習(xí)和統(tǒng)計(jì)工具的合集,目的是幫助Julia用戶創(chuàng)建可擴(kuò)展且高效的應(yīng)用。下面列出了JuliaStats中包括的一些程序:
- StatsBase:從名字我們就能看出StatsBase提供的是統(tǒng)計(jì)學(xué)相關(guān)的基本功能,比如描述統(tǒng)計(jì)、統(tǒng)計(jì)動(dòng)差、樣本函數(shù)、計(jì)數(shù)、排序、互相關(guān)、自相關(guān)以及加權(quán)統(tǒng)計(jì)等。
- DataArrays: 一個(gè)允許數(shù)據(jù)為空的數(shù)組類型,對(duì)重復(fù)數(shù)據(jù)的計(jì)算進(jìn)行了優(yōu)化。
- DataFrames: 表數(shù)據(jù)類型,提供包括索引、合并以及公式等操作。
- Distribution:用于計(jì)算分布的庫,功能包括一元分布、多元分布、概率密度函數(shù)、累積分布函數(shù)以及***似然估計(jì)。
- Multivariate Stats:為多元統(tǒng)計(jì)分析所設(shè)計(jì),功能包括降維、線性回歸、線性判別分析以及多維標(biāo)度。
- MLBase:包括數(shù)據(jù)預(yù)處理、模型選擇以及交叉驗(yàn)證等機(jī)器學(xué)習(xí)算法。
- Clustering:包括聚類分析所用到的算法如k-means、k-medoids以及多種評(píng)估方法。
這里我們只列出了一部分?jǐn)?shù)據(jù)分析和機(jī)器學(xué)習(xí)相關(guān)的庫,其他庫包括假設(shè)檢驗(yàn)、核密度估計(jì)、非負(fù)矩陣分解NMF、廣義線性模型GLM、馬爾科夫鏈蒙特卡洛方法MCMC以及時(shí)序分析等。所有庫的源碼都可以在GitHub上找到。
Julia GitHub地址:https://github.com/JuliaStats
7.Scikit-Learn
Scikit-Learn是為機(jī)器學(xué)習(xí)所設(shè)計(jì)的開源Python庫。它基于SciPy、NumPy和Matplotlib開發(fā),稱得上是一款數(shù)據(jù)分析和數(shù)據(jù)挖掘的利器。Scikit-Learn的授權(quán)協(xié)議允許個(gè)人和商業(yè)用戶使用。
Scikit-Learn主要用于:
- 聚類:識(shí)別數(shù)據(jù)中的不同類別。算法包括最鄰近搜索、支持向量機(jī)和隨機(jī)森林,可以用于圖像識(shí)別和垃圾郵件識(shí)別等應(yīng)用。
- 回歸:用于連續(xù)變量的預(yù)測(cè)。算法包括嶺回歸、支持向量回歸、套索回歸等。應(yīng)用包括股票價(jià)格、天氣以及電力負(fù)載的預(yù)測(cè)。
- 降維:用于減少隨機(jī)變量的個(gè)數(shù)。算法包括主成分分析、特征選擇、喬里斯基分解和矩陣分解。
- 數(shù)據(jù)處理:特征提取與數(shù)據(jù)預(yù)處理功能可以將原始數(shù)據(jù)轉(zhuǎn)換成有利于機(jī)器學(xué)習(xí)應(yīng)用處理的格式。
Scikit-Learn GitHub地址:https://github.com/scikit-learn/scikit-learn
本文中我們列出的這些GitHub項(xiàng)目應(yīng)用頗為流行,而且這些工具和軟件已經(jīng)被用于解決實(shí)際中的大數(shù)據(jù)問題,希望本文能夠?qū)Υ蠹业拇髷?shù)據(jù)分析之路有所啟發(fā)。