Chinchilla之死:只要訓練足夠長時間,小模型也能超過大模型
2022 年 3 月,DeepMind 一篇論文《Training Compute-Optimal Large Language Models》通過構建的 Chinchilla 模型得出了一個結論:大模型存在訓練不足的缺陷,模型大小和訓練 token 的數量應該以相等的比例擴展。也就是說模型越大,所使用的訓練 token 也應該越多。

但事實可能并非如此,近日,博主 Thaddée Yann TYL 寫了一篇題為《Chinchilla 之死》的文章,其中分析解讀了 OpenAI 與 DeepMind 幾篇論文中的細節,得到了一個出人意料的結論:如果有充足的計算資源和數據,訓練足夠長時間,小模型的表現也可以超越大模型。
多算勝,少算不勝。——《孫子兵法》
為了避免將算力浪費于緩慢的收斂過程中,進行外推是非常重要的。畢竟,如果你不得不步行去珠穆朗瑪峰,你不會只靠眼睛辨別方向,而是會使用 GPS。
但有時候,你又不得不把視線從 GPS 上移開,看看道路。有些東西是無法通過簡單的公式推斷出來的。對十九世紀的物理學家來說,紫外災變( Ultraviolet catastrophe)便是如此;而現在,LLM 亦是如此。我們估計在中心位置附近有效的東西可能在遠處會出現巨大的偏差……

《我的世界》的邊境之地(far lands),這是突然扭曲并與自身重疊的懸崖之地。
Chinchilla 到底是什么?
更小的模型執行的乘法更少,因而訓練得也更快。但是,按照理論,更小的模型最終會觸及自身知識容量的極限,并且學習速度會變慢;而有更大知識容量的大型模型在經過給定的訓練時間后會超過小模型,取得更好的性能表現。
在評估如何在訓練期間獲得最佳性價比時,OpenAI 和 DeepMind 都會試圖繪制帕累托邊界(Pareto frontier)。雖然他們沒有明確說明他們使用了該理論來繪制,但 OpenAI 曾說過的一句話暗示存在這個隱藏假設:
我們預計更大模型的表現應當總是優于更小的模型…… 大小固定的模型的能力是有限的。
這一假設是他們計算帕累托邊界的基石。在 Chinchilla 研究中,圖 2 展示了不同大小的模型經過大量訓練時的訓練損失變化情況。初看之下,這些曲線與理論相符:更小的模型一開始的損失更低(表現更好),但損失降低的速度最終變慢并被更大模型的曲線超越。
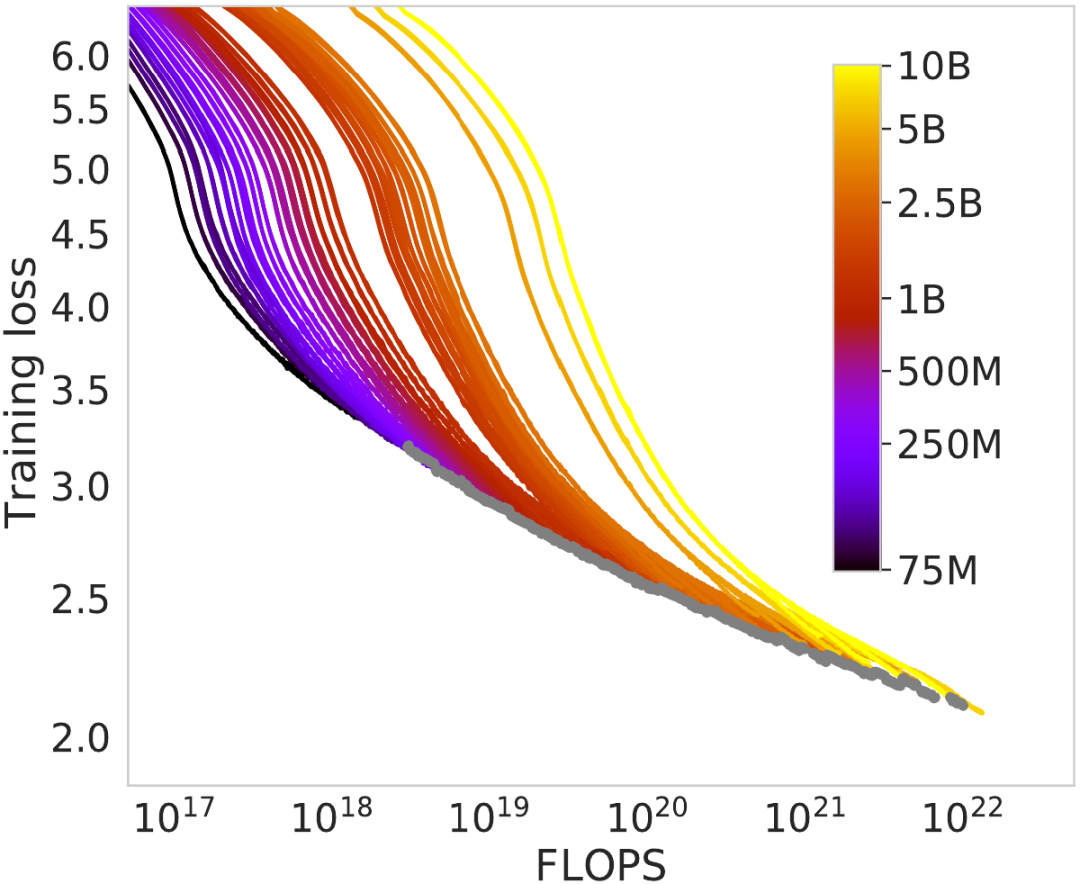
比較許多不同模型大小的損失曲線的 Chinchilla 圖
在這幅圖中,每當更小的模型輸給一個更大的模型時,他們就會標記一個灰點。這些點連成的灰線便是帕累托邊界,這是他們計算縮放定律(scaling laws)的方式。
這一假設有個問題:我們不知道如果讓更小的模型訓練更長時間會發生什么,因為他們在小模型被超越時就不再繼續訓練它們了。
接下來在看看 Llama 論文。
Chinchilla 會有 Llama 的視野嗎?
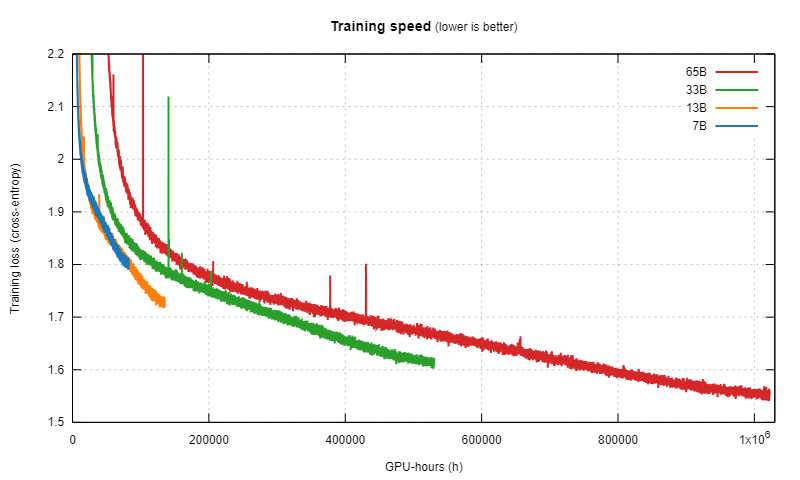
今年初,Meta 訓練了四個不同大小的模型。不同于其它研究,其中每個模型都被訓練了非常長時間,較小的模型也一樣。
他們公布了所得到的訓練曲線:
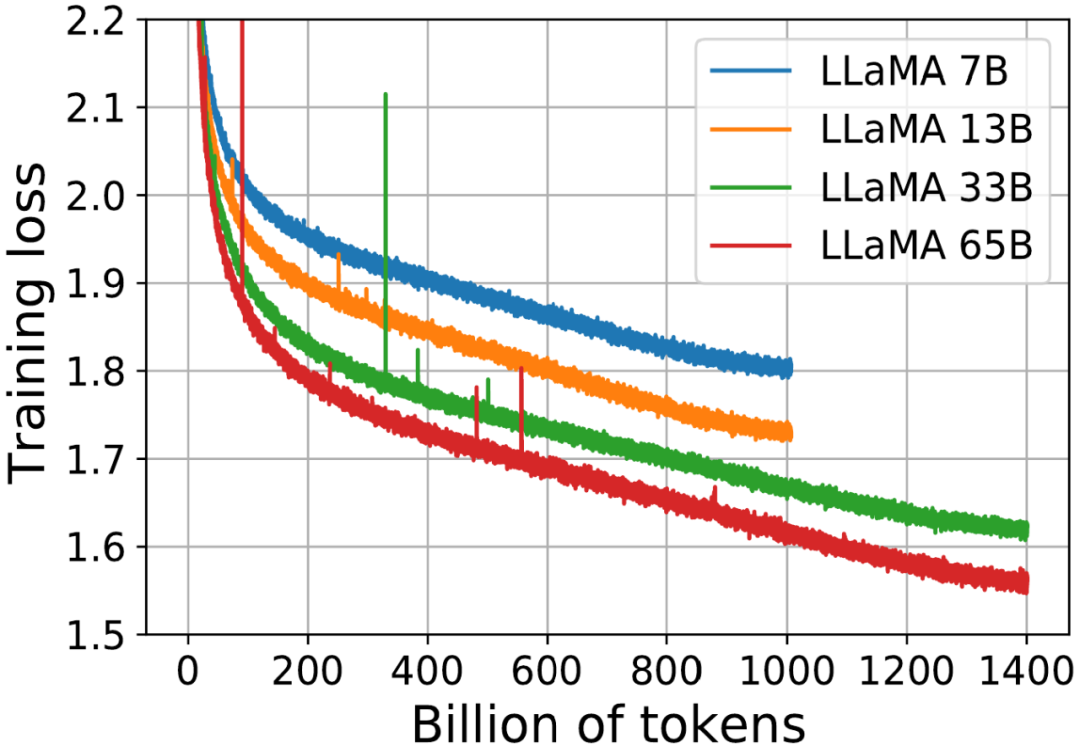
四個不同大小的 Llama 模型的訓練損失曲線
- 每條曲線首先按照冪律大幅下降。
- 然后損失開始近乎線性地下降(對應于一個相當恒定的知識獲取率)。
- 在這條曲線的最右端,直線趨勢被稍微打破,因為它們稍微變更平緩了一些。
首先,對于曲線末端的變平情況,這里解釋一下人們可能有的一個微妙的誤解。這些模型都是通過梯度下降訓練的并且使用了可變的學習率(大致來說,這個超參數定義了每次朝梯度方向前進的程度)。為了獲得優良的訓練效果,學習率必須不斷降低,這樣模型才能檢測到源材料中更細微的模式。他們用于降低學習率的公式是最常用的余弦調度(cosine schedule)。
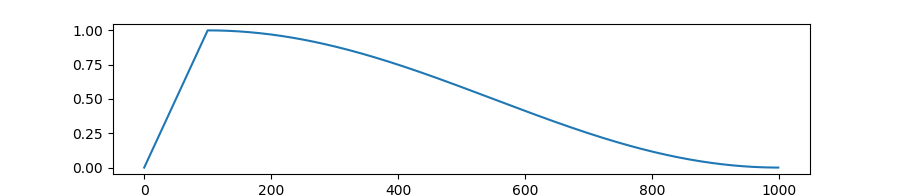
在余弦調度下,學習率與訓練步數的函數關系:學習率首先線性增長,然后下降且下降速度變快,之后到達中途一個轉折點,下降速度再減慢。
從這張圖中可以看到,在訓練結束時,余弦調度會停止降低學習率,此時已經得到一個很好的近乎線性的訓練損失曲線。學習速度減慢就是這種做法造成的。模型并不一定不再具有以同樣近乎線性的速率學習的能力!事實上,如果我們能為其提供更多文本,我們就能延長其余弦調度,這樣其學習率就會繼續以同樣速率下降。
模型的適應度圖景并不取決于我們供給它訓練的數據量;所以學習率下降趨勢的改變是沒有道理的。
不過這并非本文的重點。
訓練損失曲線可能在另一方向上也存在誤導性。當然,它們訓練使用的數據是一樣的,但它們處理這些數據的速度不同。我們想知道的并不是模型的樣本效率如何(在這方面,更大的模型顯然可以從其所見數據中學到更多)。讓我們想象一場比賽:所有這些模型同時開始起步,我們想知道哪個模型首先沖過終點線。換句話說,當在訓練時間投入固定量的算力時,哪個模型能在那段時間內學到更多?
幸好我們可以把這些損失曲線與 Meta 提供的另一些數據組合起來看:每個模型訓練所用的時間。
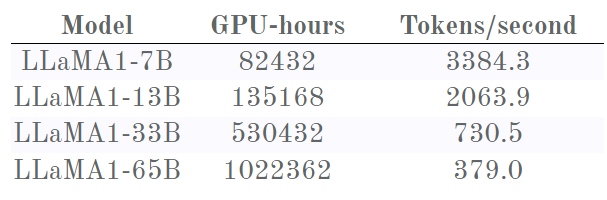
先來談談上面我們看過的那張 Chinchilla 圖,其僅占這張圖左側的一小部分。在這一小部分,可以看到 Chinchilla 記錄的相同行為。以 7B 版本為例:其損失的下降速度一開始比更大的模型快得多,然后減慢;之后 13B 版本模型超過了它,率先到達 1.9。
然后,抵達邊境之地,意外的轉折出現了:7B 版本進入了近乎線性的疆域,損失穩步下降,看起來似乎走上了反超 13B 版本之路?如果能訓練 7B 版本更長時間,說不好會發生什么。
但是,13B 和 33B 版本之間似乎也有類似的現象,其中 13B 版本起初的 Chinchilla 減慢也使其呈現出近乎線性的趨勢,這時候 13B 版本的損失下降速度似乎很快!33B 其實勝之不武,因為它超越 13B 版本時已經用去了超過兩倍的計算時間。
33B 和 65B 版本之間也有同樣的先減速再加速的現象,以至于 33B 實際上從未被 65B 超越。這幅圖的內容擊破了 OpenAI 和 Chinchilla 的假設:更大的模型并未取得勝利(至少說還沒有)。他們檢測到的這種減速實際上并不是由于達到了某個能力極限!
盡管如此,7B 模型的線還是有點不盡如人意。如果 Meta 能訓練更長時間就好了……
不賣關子了:他們訓練了!他們發布了 Llama 2!
是時候證實我們的懷疑了
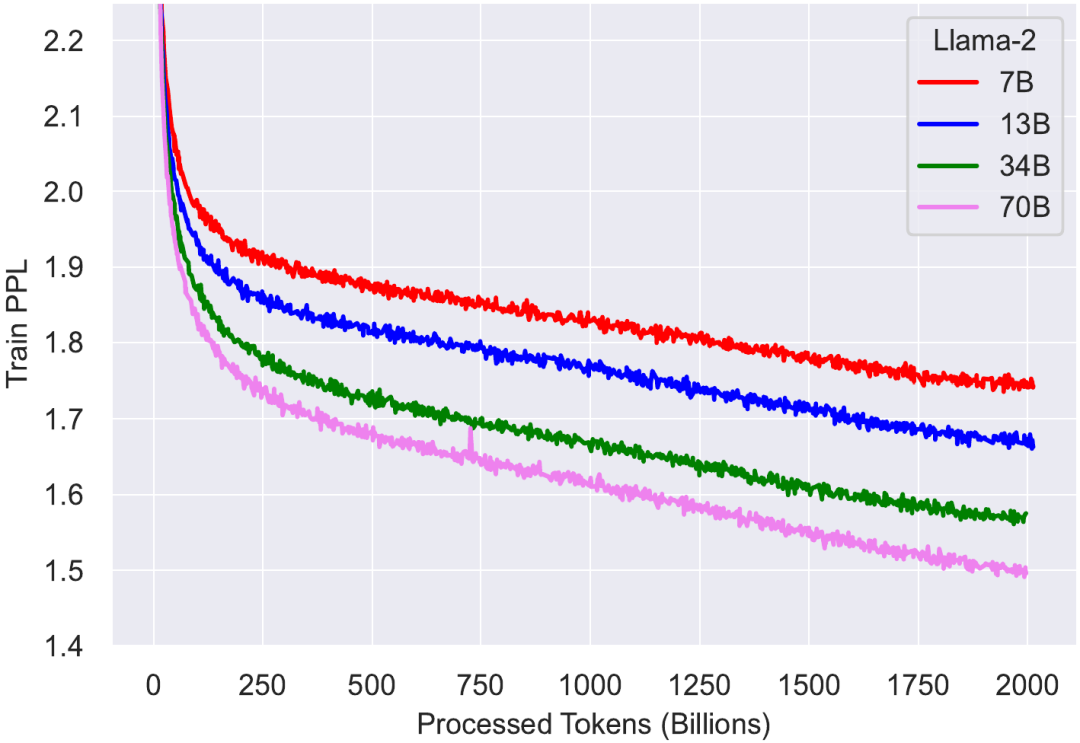
四個不同大小的 Llama 2 模型的訓練損失曲線
同樣,可以得到訓練時間:
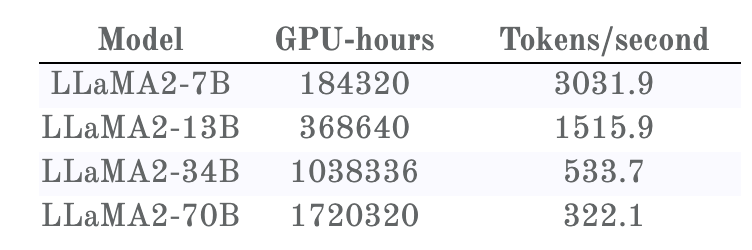
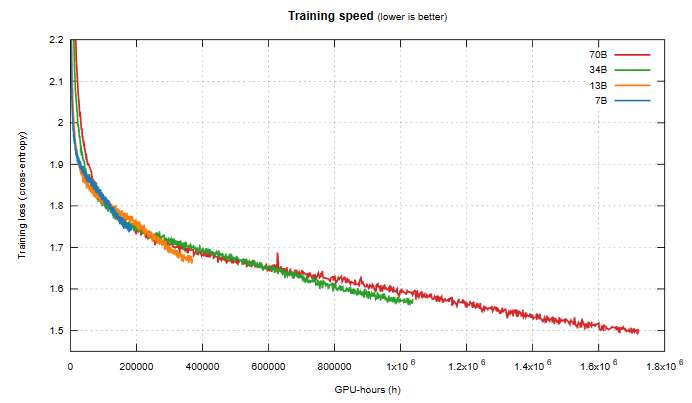
Llama 2 訓練損失與所耗費的 GPU 時間
一眼便能看出,這里的訓練損失曲線與 Llama 1 的不一樣,即便這些基礎模型是一樣的。事實證明, Llama 2 的訓練使用了雙倍上下文大小和更長的余弦調度 —— 不幸的是,這會對所有模型大小產生負面影響。但是,更小的模型受到的影響比更大的模型更嚴重。由此造成的結果是:在 Llama 1 的訓練時間,33B 模型總是優于 65B 模型;而在 Llama 2 的訓練時間,34B 模型則在重新超過 70B 模型之前要略遜一籌。
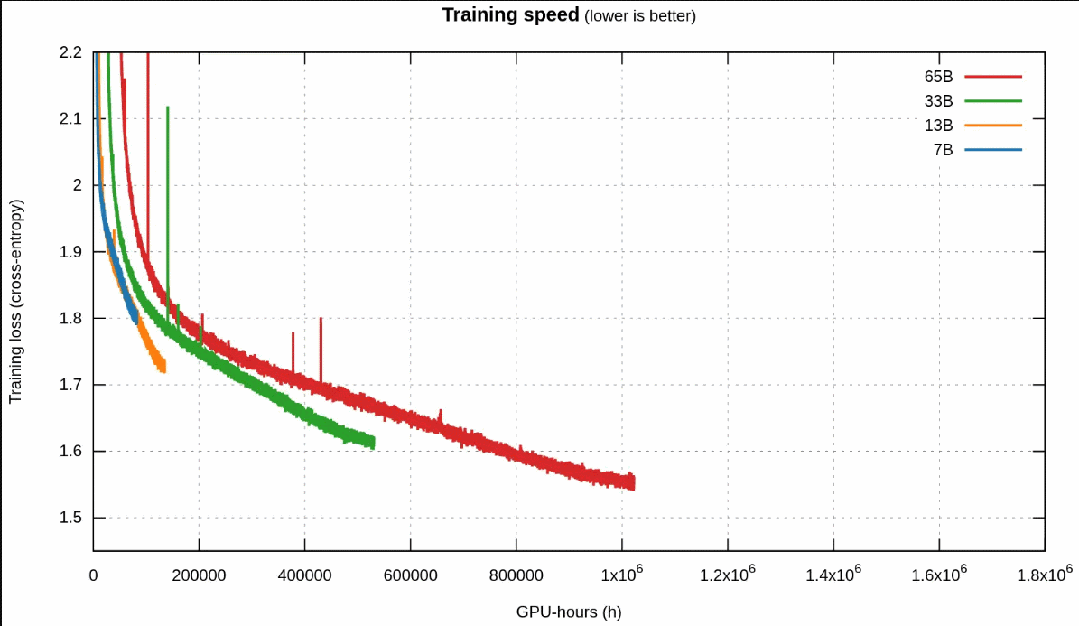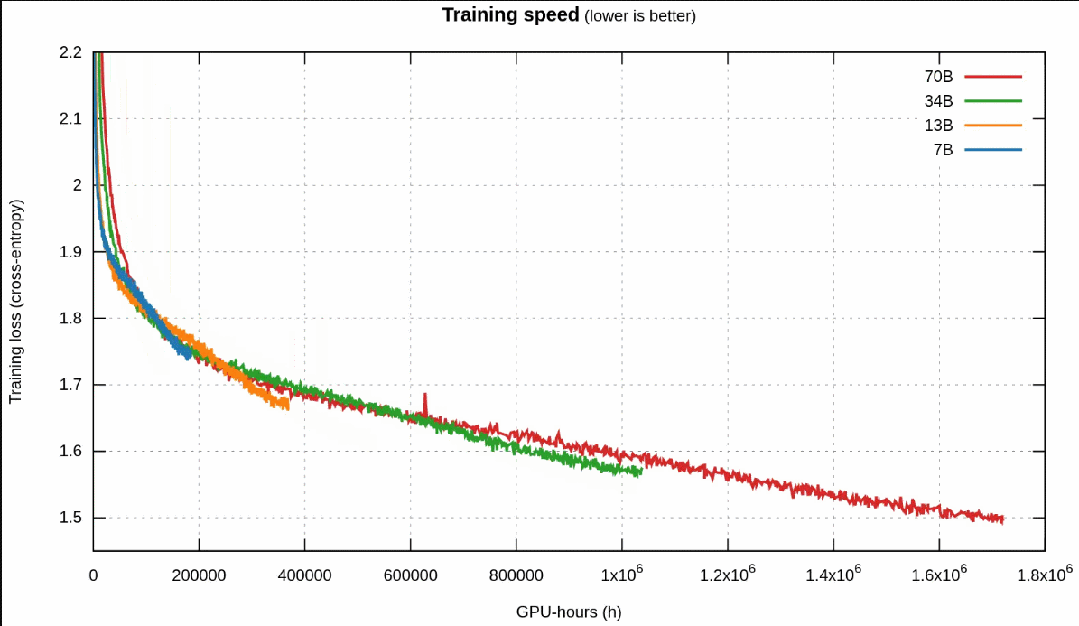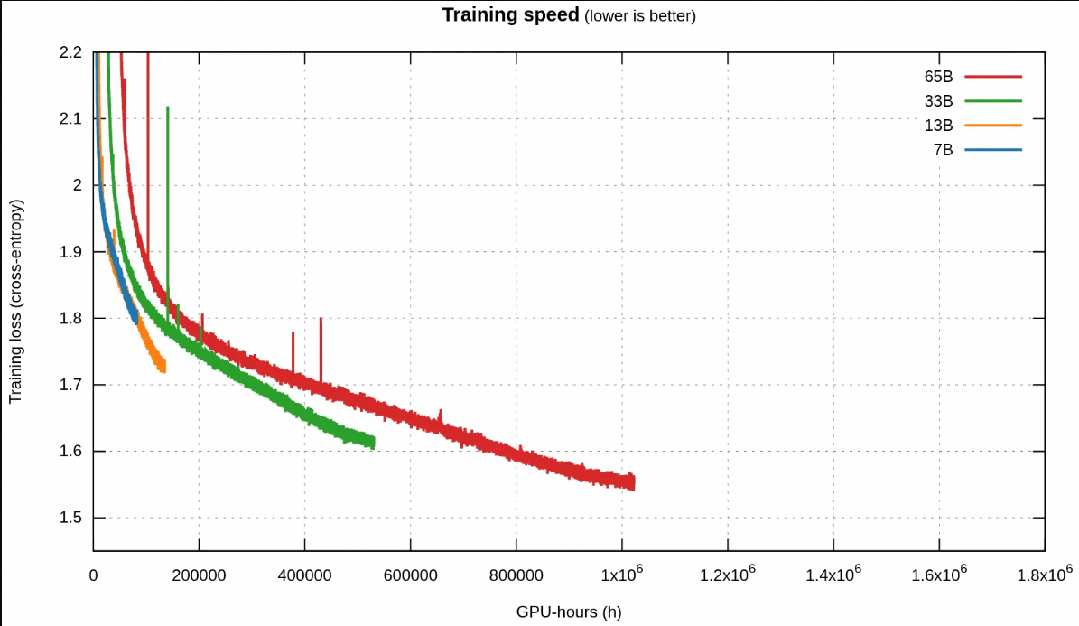
更重要的是,對訓練速度的比較強烈地佐證了之前對 Llama 1 的猜想:
- 一開始時,更小的模型快于更大的模型。
- 然后,更小的模型速度變慢,并被更大的模型超越(按照 Chinchilla)。
- 但再然后,模型進入近乎線性的區域,這時候更小的模型能更快地下降,獲取更優的知識,它們再次超越更大的模型。
這就帶來了一個有關訓練方法的結論:與普遍的看法相反,更大的模型會產生更差的結果。如果你必須選擇一個參數大小和數據集,你可能最好選擇 7B 模型,然后在數萬億 token 上訓練 7 epoch。
請看看 7B 模型近乎線性的區域,然后將其模式外推給 70B 模型,看看 70B 模型訓練停止時的情況:如果將 70B 模型的訓練資源花在 7B 模型上,可能會達到更低的困惑度!
從 Llama 2 的曲線還能看到另一點:Llama 1 曲線末端的學習減速實際上是余弦調度造成的。在 Llama 2 的訓練中,在對應于 1 萬億 token 讀取數的位置,就完全沒有這種減速。
事實上,原因可能是這樣的:在同一位置, Llama 2 7B 模型的質量低于 Llama 1 7B 模型,可能是因為其余弦調度被拉長了!
現在我們回到那篇 Chinchilla 論文來論證這一點。在該論文的附錄 A 的圖 A1 中,他們給出了一個不同余弦調度參數的消融實驗,換句話說就是對學習率曲線使用不同的延展方式。
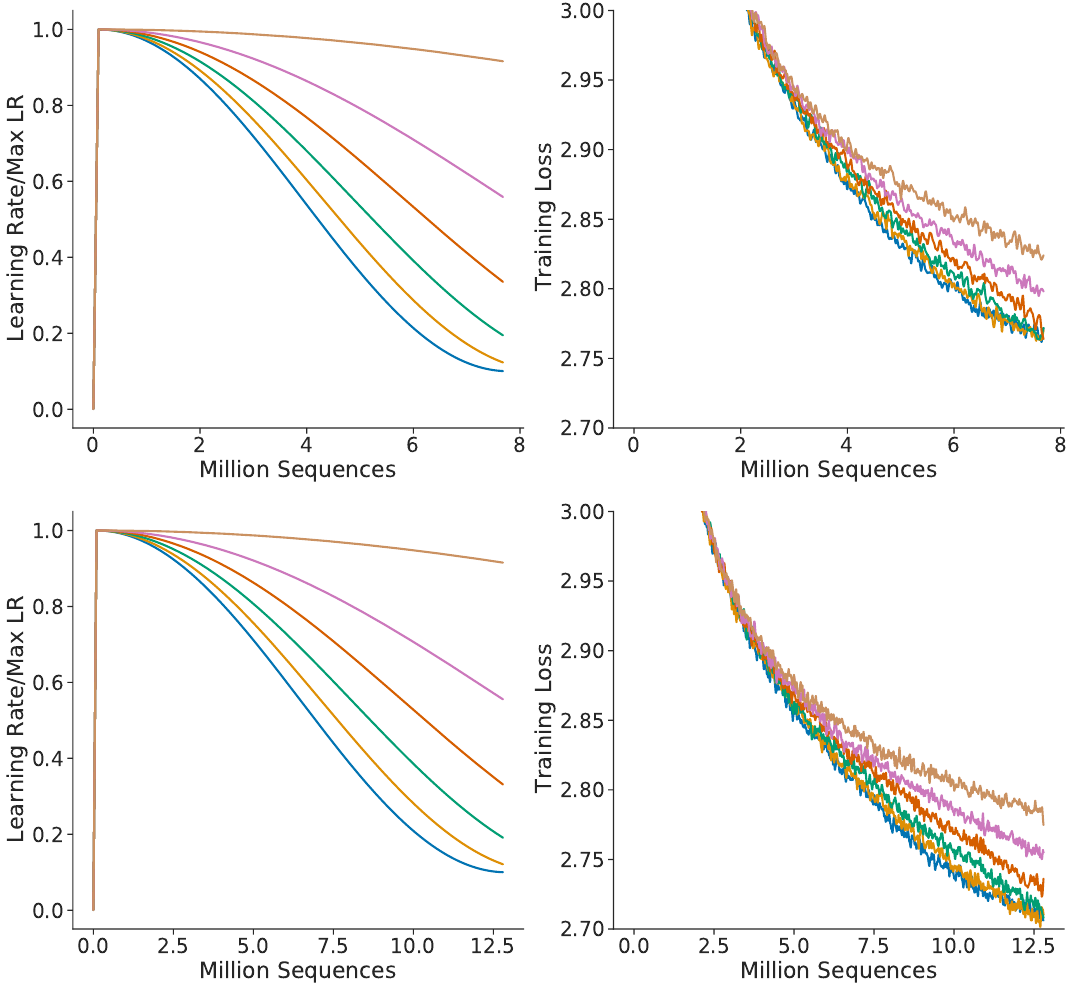
Chinchilla 余弦調度消融研究
他們指出,當學習率曲線沒有延展時,能實現最低的損失。這得到了圖表的支持,但其中也有不對勁的地方。在讀取了 600 萬 token 后,上圖模型的訓練損失低于 2.8;與此同時,在相同的位置,下圖模型的訓練損失還更好。然而這兩個模型的差異僅僅是余弦調度!由于下圖模型注定會處理更多訓練數據,所以就計算了「未拉伸的」余弦調度更多步驟,這實際上產生了拉伸效果。如果學習率遵循分配給更少訓練步驟的余弦調度,其在同等訓練時間下的損失會更低。
更廣泛地說,這會引出一個有待解答的問題:如果余弦調度不是最優的,那么曲線的尾部形狀應該是什么樣子?