













如何利用Transformer有效關聯激光雷達-毫米波雷達-視覺特征?
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
筆者個人理解
自動駕駛的基礎任務之一是三維目標檢測,而現在許多方法都是基于多傳感器融合的方法實現的。那為什么要進行多傳感器融合?無論是激光雷達和相機融合,又或者是毫米波雷達和相機融合,其最主要的目的就是利用點云和圖像之間的互補聯系,從而提高目標檢測的準確度。隨著Transformer架構在計算機視覺領域的不斷應用,基于注意力機制的方法提高了多傳感器之間融合的精度。分享的兩篇論文便是基于此架構,提出了新穎的融合方式,以更大程度地利用各自模態的有用信息,實現更好的融合。
TransFusion:
主要貢獻
激光雷達和相機是自動駕駛中兩種重要的三維目標檢測傳感器,但是在傳感器融合上,主要面臨著圖像條件差導致檢測精度較低的問題。基于點的融合方法是將激光雷達和相機通過硬關聯(hard association)進行融合,會導致一些問題:a)簡單地拼接點云和圖像特征,在低質量的圖像特征下,檢測性能會嚴重下降;b)尋找稀疏點云和圖像的硬關聯會浪費高質量的圖像特征并且難以對齊。
因此,此論文提出一種激光雷達和相機的融合框架TransFusion,來解決兩種傳感器之間的關聯問題,主要貢獻如下:
- 提出一種基于transformer的激光雷達和相機的3D檢測融合模型,對較差的圖像質量和傳感器未對齊表現出優異的魯棒性;
- 為對象查詢引入了幾個簡單而有效的調整,以提高圖像融合的初始邊界框預測的質量,還設計了一個圖像引導查詢初始化模塊來處理在點云中難以檢測到的對象;
- 不僅在nuScenes實現了先進的三維檢測性能,還將模型擴展到三維跟蹤任務,并取得了不錯的成果。
模塊詳解
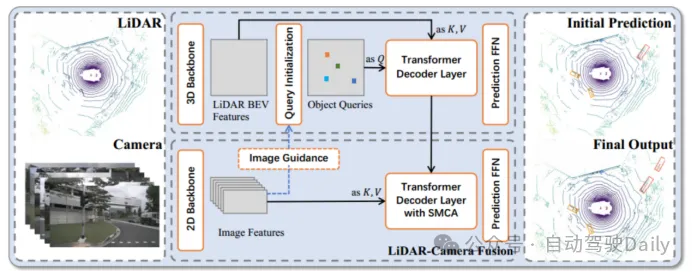
圖1 TransFusion的整體框架
為了解決上述的圖像條件差以及不同傳感器之間的關聯問題,提出了一個基于Transformer的融合框架——TransFusion。該模型依賴標準的3D和2D主干網絡提取LiDAR BEV特征和圖像特征,然后檢測頭上采用兩層transformer解碼器組成:第一層解碼器利用稀疏的點云生成初始邊界框;第二層解碼器將第一層的對象查詢與圖像特征相關聯,以獲得更好的檢測結果。其中還引入了空間調制交叉注意力機制(SMCA)和圖像引導的查詢初始化策略以提高檢測精度。
Query Initialization(查詢初始化)

LiDAR-Camera Fusion
如果一個物體只包含少量的激光雷達點時,那么只能獲得相同數量的圖像特征,浪費了高質量的圖像語義信息。所以該論文保留所有的圖像特征,使用Transformer中交叉注意機制和自適應的方式進行特征融合,使網絡能夠自適應地從圖像中提取位置和信息。為了緩解LiDAR BEV特征和圖像特征來自不同的傳感器的空間不對齊問題,設計了一個空間調制交叉注意模塊(SMCA),該模塊通過圍繞每個查詢投影的二維中心的二維圓形高斯掩模對交叉注意進行加權。
Image-Guided Query Initialization(圖像引導查詢初始化)
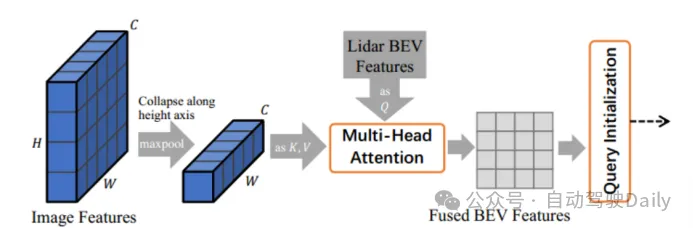
圖2 圖像引導查詢模塊
該模塊同時利用激光雷達和圖像信息作為對象查詢,就是通過將圖像特征和激光雷達BEV特征送入交叉關注機制網絡,投射到BEV平面上,生成融合的BEV特征。具體如圖2所示,首先沿著高度軸折疊多視圖圖像特征作為交叉注意機制網絡的鍵值,而激光雷達BEV特征作為查詢送入注意力網絡,得到融合的BEV特征,使用進行熱圖預測,并與僅激光雷達的熱圖?做平均得到最終的熱圖?來選擇和初始化目標查詢。這樣的操作使得模型能夠檢測到在激光雷達點云中難以檢測到的目標。
實驗
數據集和指標
nuScenes數據集是一個用于3D檢測和跟蹤的大規模自動駕駛數據集,包含700、150和150個場景,分別用于訓練、驗證和測試。每幀包含一個激光雷達點云和六個覆蓋360度水平視場的校準圖像。對于3D檢測,主要指標是平均平均精度(mAP)和nuScenes檢測分數(NDS)。mAP是由BEV中心距離而不是3D IoU定義的,最終mAP是通過對10個類別的0.5m, 1m, 2m, 4m的距離閾值進行平均來計算的。NDS是mAP和其他屬性度量的綜合度量,包括平移、比例、方向、速度和其他方框屬性。。
Waymo數據集包括798個用于訓練的場景和202個用于驗證的場景。官方的指標是mAP和mAPH (mAP按航向精度加權)。mAP和mAPH是基于3D IoU閾值定義的,車輛為0.7,行人和騎自行車者為0.5。這些指標被進一步分解為兩個難度級別:LEVEL1用于超過5個激光雷達點的邊界框,LEVEL2用于至少有一個激光雷達點的邊界框。與nuScenes的360度攝像頭不同,Waymo的攝像頭只能覆蓋水平方向的250度左右。
訓練 在nuScenes數據集上,使用DLA34作為圖像的2D骨干網絡并凍結其權重,將圖像大小設置為448×800;選擇VoxelNet作為激光雷達的3D骨干網絡。訓練過程分成兩個階段:第一階段僅以激光雷達數據作為輸入,以第一層解碼器和FFN前饋網絡訓練3D骨干20次,產生初始的3D邊界框預測;第二階段對LiDAR-Camera融合和圖像引導查詢初始化模塊進行6次訓練。左圖是用于初始邊界框預測的transformer解碼器層架構;右圖是用于LiDAR-Camera融合的transformer解碼器層架構。
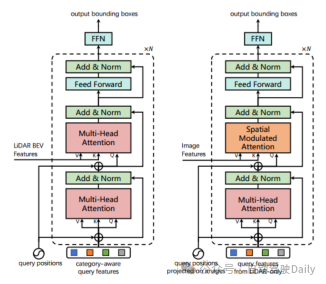
圖3 解碼器層設計
與最先進方法比較
首先比較TransFusion和其他SOTA方法在3D目標檢測任務的性能,如下表1所示的是在nuScenes測試集中的結果,可以看到該方法已經達到了當時的最佳性能(mAP為68.9%,NDS為71.7%)。而TransFusion-L是僅使用激光雷達進行檢測的,其檢測的性能明顯優于先前的單模態檢測方法,甚于超過了一些多模態的方法,這主要是由于新的關聯機制和查詢初始化策略。而在表2中則是展示了在Waymo驗證集上LEVEL 2 mAPH的結果。
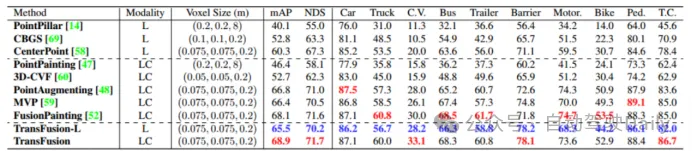
表1 與SOTA方法在nuScenes測試中的比較
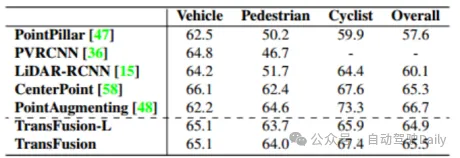
表2 Waymo驗證集上的LEVEL 2 mAPH
對惡劣圖像條件的魯棒性
以TransFusion-L為基準,設計不同的融合框架來驗證魯棒性。其中三種融合框架分別是逐點拼接融合激光雷達和圖像特征(CC)、點增強融合策略(PA)和TransFusion。如表3中顯示,將nuScenes數據集劃分成白天和黑夜,TransFusion的方法在夜間將會帶來更大的性能提升。在推理過程中將圖像的特征設置為零,以達到在每一幀隨機丟棄若干圖像的效果,那么在表4中可以看到,在推理過程中某些圖像不可用時,檢測的性能會顯著下降,其中CC和PA的mAP分別下降23.8%和17.2%,而TransFusion仍保持在61.7%。傳感器未校準的情況也會大大影響3D目標檢測的性能,實驗設置從相機到激光雷達的變換矩陣中隨機添加平移偏移量,如圖4所示,當兩個傳感器偏離1m時,TransFusion的mAP僅下降0.49%,而PA和CC的mAP分別下降2.33%和2.85%。
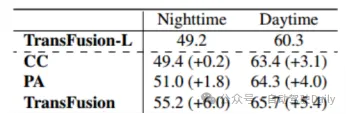
表3 白天和夜間的mAP

表4 在不同數量的圖像下的mAP
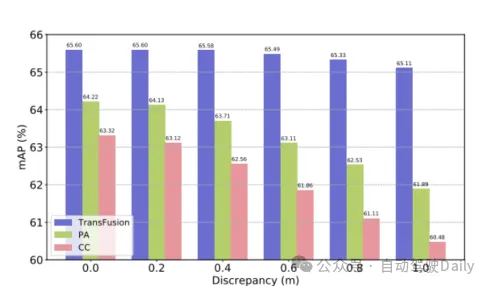
圖4 在傳感器未對齊情況下的mAP
消融實驗
由表5 d)-f)的結果可看出,在沒有進行查詢初始化的情況下,檢測的性能下降很多,雖然增加訓練輪數和解碼器層數可以提高性能,但是仍舊達不到理想效果,這也從側面證明了所提出來的初始化查詢策略能夠減小網絡層數。而如表6所示,圖像特征融合和圖像引導查詢初始化分別帶來4.8%和1.6%的mAP增益。在表7中,通過在不同范圍內精度的比較,TransFusion與僅激光雷達的檢測相比,在難以檢測的物體或者遙遠區域的檢測的性能都得到了提升。
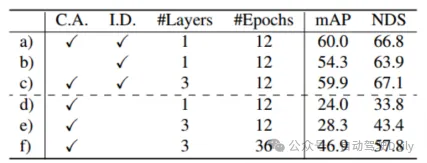
表5 查詢初始化模塊的消融實驗
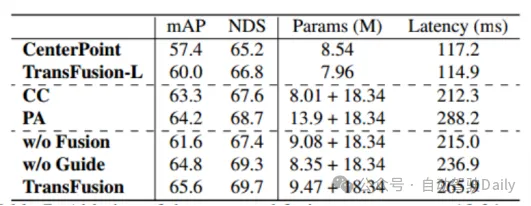
表6 融合部分的消融實驗

表7 物體中心到自我車輛之間的距離(以米為單位)
結論
設計了一個有效且穩健的基于Transformer的激光雷達相機3D檢測框架,該框架具有軟關聯機制,可以自適應地確定應該從圖像中獲取的位置和信息。TransFusion在nuScenes檢測和跟蹤排行榜上達到最新的最先進的結果,并在Waymo檢測基準上顯示了具有競爭力的結果。大量的消融實驗證明了該方法對較差圖像條件的魯棒性。
DeepInteraction:
主要貢獻:
主要解決的問題是現有的多模態融合策略忽略了特定于模態的有用信息,最終阻礙了模型的性能。點云在低分辨率下提供必要的定位和幾何信息,圖像在高分辨率下提供豐富的外觀信息,因此跨模態的信息融合對于增強3D目標目標檢測性能尤為重要。現有的融合模塊如圖1(a)所示,將兩個模態的信息整合到一個統一的網絡空間中,但是這樣做會使得部分信息無法融合到統一的表示里,降低了一部分特定于模態的表示優勢。為了克服上述限制,文章提出了一種新的模態交互模塊(圖1(b)),其關鍵思想是學習并維護兩種特定于模態的表示,從而實現模態間的交互。主要貢獻如下:
- 提出了一種新的多模態三維目標檢測的模態交互策略,旨在解決以前模態融合策略在每個模態中丟失有用信息的基本限制;
- 設計了一個帶有多模態特征交互編碼器和多模態特征預測交互解碼器的DeepInteraction架構。
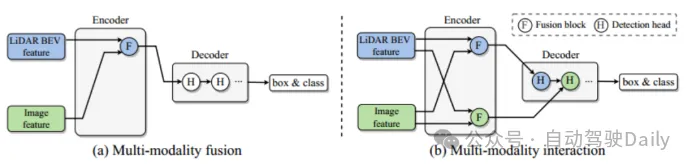
圖1 不同的融合策略
模塊詳解
多模態表征交互編碼器 將編碼器定制為多輸入多輸出(MIMO)結構:將激光雷達和相機主干獨立提取的兩個模態特定場景信息作為輸入,并生成兩個增強后的特征信息。每一層編碼器都包括:i)多模態特征交互(MMRI);ii)模態內特征學習;iii)表征集成。
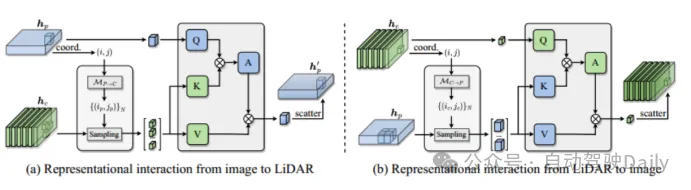
圖2 多模態表征交互模塊

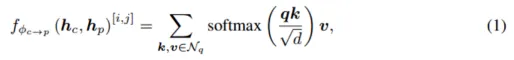
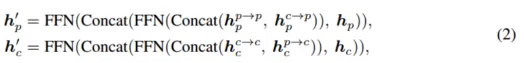

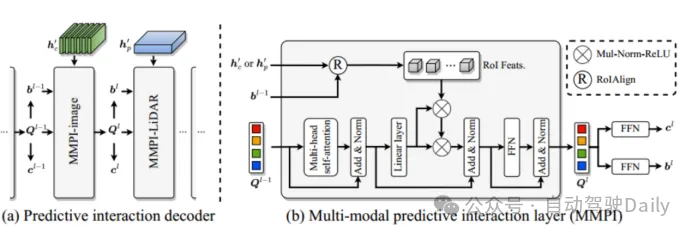
圖3 多模態預測交互模塊
實驗
數據集和指標同TransFusion的nuScenes數據集部分。
實驗細節 圖像的主干網絡是ResNet50,為了節省計算成本,在輸入網絡之前將輸入圖像重新調整為原始大小的1/2,并在訓練時凍結圖像分支的權重。體素大小設置為(0.075m,0.075m,0.2m),檢測范圍設為X軸和Y軸是[-54m,54m],Z軸是[-5m,3m],設計2層編碼器層和5層級聯的解碼器層。另外還設置了兩種在線提交測試模型:測試時間增加(TTA)和模型集成,將兩個設置分別稱為DeepInteraction-large和DeepInteraction-e。其中DeepInteraction-large使用Swin-Tiny作為圖像骨干網絡,并且將激光雷達骨干網絡中卷積塊的通道數量增加一倍,體素大小設置為[0.5m,0.5m,0.2m],使用雙向翻轉和旋轉偏航角度[0°,±6.25°,±12.5°]以增加測試時間。DeepInteraction-e集成了多個DeepInteraction-large模型,輸入的激光雷達BEV網格尺寸為[0.5m,0.5m]和[1.5m,1.5m]。
根據TransFusion的配置進行數據增強:使用范圍為[-π/4,π/4]的隨機旋轉,隨機縮放系數為[0.9,1.1],標準差為0.5的三軸隨機平移和隨機水平翻轉,還在CBGS中使用類平衡重采樣來平衡nuScenes的類分布。和TransFusion一樣采用兩階段訓練的方法,以TransFusion-L作為僅激光雷達訓練的基線。使用單周期學習率策略的Adam優化器,最大學習率1×10?3,權衰減0.01,動量0.85 ~ 0.95,遵循CBGS。激光雷達基線訓練為20輪,激光雷達圖像融合為6輪,批量大小為16個,使用8個NVIDIA V100 GPU進行訓練。
與最先進方法比較
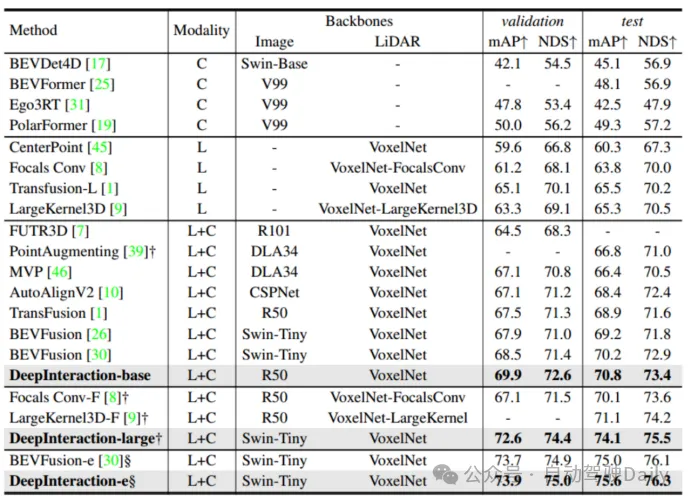
表1 在nuScenes測試集上與最先進方法的比較
如表1所示,DeepInteraction在所有設置下都實現了最先進的性能。而在表2中分別比較了在NVIDIA V100、A6000和A100上測試的推理速度。可以看到,在取得高性能的前提下,仍舊保持著較高的推理速度,驗證了該方法在檢測性能和推理速度之間實現了優越權衡。
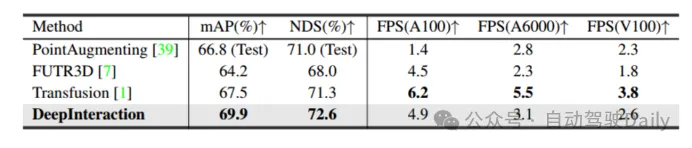
表2 推理速度比較
消融實驗
解碼器的消融實驗
在表3(a)中比較了多模態交互預測解碼器和DETR解碼器層的設計,并且使用了混合設計:使用普通的DETR解碼器層來聚合激光雷達表示中的特征,使用多模態交互預測解碼器(MMPI)來聚合圖像表示中的特征(第二行)。MMPI明顯優于DETR,提高了1.3% mAP和1.0% NDS,具有設計上的組合靈活性。表3(c)進一步探究了不同的解碼器層數對于檢測性能的影響,可以發現增加到5層解碼器時性能是不斷提升的。最后還比較了訓練和測試時采用的查詢數的不同組合,在不同的選擇下,性能上穩定的,但以200/300作為訓練/測試的最佳設置。
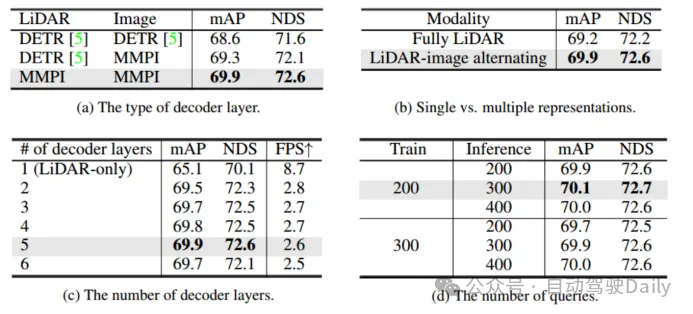
表3 解碼器的消融實驗
編碼器的消融實驗
從表4(a)中可以觀察到:(1)與IML相比,多模態表征交互編碼器(MMRI)可以顯著提高性能;(2) MMRI和IML可以很好地協同工作以進一步提高性能。從表4(b)中可以看出,堆疊編碼器層用于迭代MMRI是有益的。
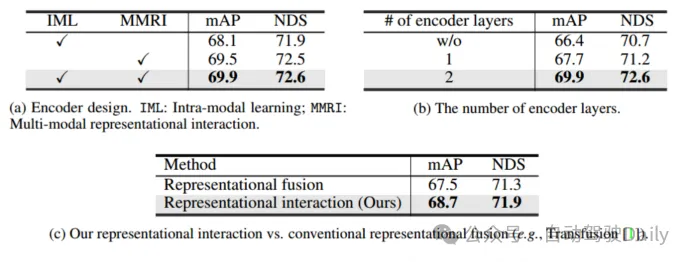
表4 編碼器的消融實驗
激光雷達骨干網絡的消融實驗
使用兩種不同的激光雷達骨干網絡:PointPillar和VoxelNet來檢查框架的一般性。對于PointPillars,將體素大小設置為(0.2m, 0.2m),同時保持與DeepInteraction-base相同的其余設置。由于提出的多模態交互策略,DeepInteraction在使用任何一種骨干網時都比僅使用lidar基線表現出一致的改進(基于體素的骨干網提高5.5% mAP,基于支柱的骨干網提高4.4% mAP)。這體現了DeepInteraction在不同點云編碼器中的通用性。
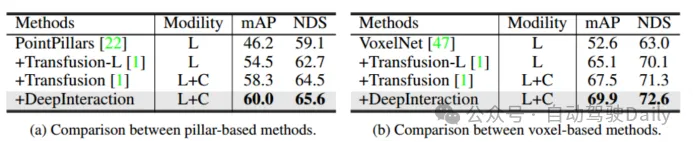
表5不同激光雷達主干網的評估
結論
在這項工作中,提出了一種新的3D目標檢測方法DeepInteraction,用于探索固有的多模態互補性質。這一關鍵思想是維持兩種特定于模態的表征,并在它們之間建立表征學習和預測解碼的相互作用。該策略是專門為解決現有單側融合方法的基本限制而設計的,即由于其輔助源角色處理,圖像表示未得到充分利用。
兩篇論文的總結:
以上的兩篇論文均是基于激光雷達和相機融合的三維目標檢測,從DeepInteraction中也可以看到它是借鑒了TransFusion的進一步工作。從這兩篇論文中可以總結出多傳感器融合的一個方向,就是探究更高效的動態融合方式,以關注到更多不同模態的有效信息。當然了,這一切建立在兩種模態均有著高質量的信息。多模態融合在未來的自動駕駛、智能機器人等領域都會有很重要的應用,隨著不同模態提取的信息逐漸豐富起來,我們能夠利用到的信息將會越來越多,那么如何將這些數據更高效的運用起來也是一個值得思考的問題。

























