比9種SOTA GNN更強!谷歌大腦提出全新圖神經網絡GKATs
從社交網絡到生物信息學,再到機器人學中的導航和規劃問題,圖在各種現實世界的數據集中普遍存在。
于是乎,人們對專門用于處理圖結構數據的圖神經網絡(GNN)產生了極大的興趣。
盡管現代GNN在理解圖形數據方面取得了巨大的成功,但在有效處理圖形數據方面仍然存在一些挑戰。
例如,當所考慮的圖較大時,計算復雜性就成為一個問題。
相反,在空間域工作的算法避免了昂貴的頻譜計算,但為了模擬較長距離的依賴關系,不得不依靠深度GNN架構來實現信號從遠處節點的傳播,因為單個層只模擬局部的相互作用。
為解決這些問題,谷歌大腦、哥倫比亞大學和牛津大學的研究團隊提出了一類新的圖神經網絡:Graph Kernel Attention Transformers(GKATs)。
其結合了圖核、基于注意力的網絡和結構先驗,以及最近的通過低秩分解技術應用小內存占用隱式注意方法的Transformer架構。

該團隊證明GKAT比SOTA GNN具有更強的表達能力,同時還減少了計算負擔。
全新GNN,降低計算復雜度
「是否有可能設計具有密集單個層的 GNN,顯式建模圖中更長范圍的節點到節點關系,從而實現更淺的架構,同時擴展更大的(不一定是稀疏的)圖?」
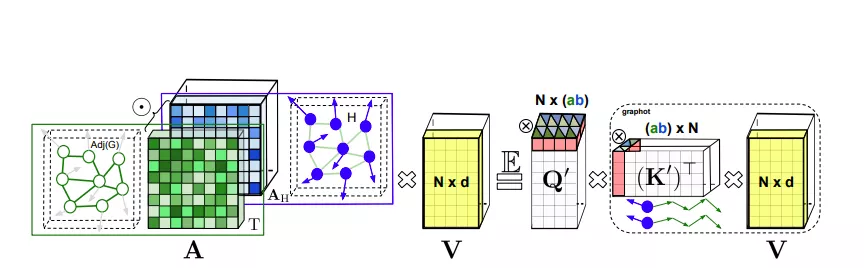
GKATs中可分解的長注意力
GKAT將每一層內的圖注意力建模為節點特征向量的核矩陣和圖核矩陣的Hadamard乘積。
這使GKAT能夠利用計算效率高的隱式注意機制,并在單層內對更遠距離的依賴項進行建模,從而將其表達能力提升到超越傳統GNN的水平。
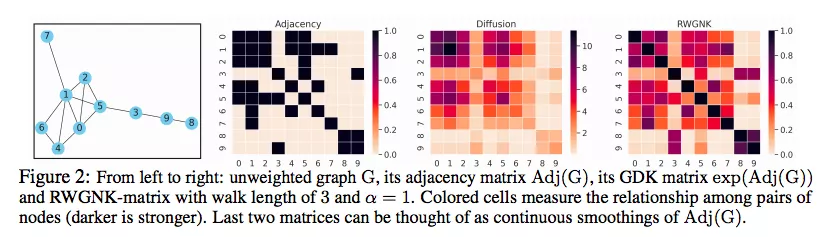
為了在圖節點上定義可實現高效映射的表達內核,研究人員采用了一種新穎的隨機游走圖節點內核 (RWGNKs) 方法,其中兩個節點的值作為兩個頻率向量的點積給出,這些向量記錄了圖節點中的隨機游走。
完整的 GKAT 架構由幾個塊組成,每個塊由注意力層和標準 MLP 層構建而成。
值得注意的是,注意層與輸入圖的節點數成線性關系而不是二次方,因此與其常規的圖注意力對應物相比降低了計算復雜度。
優于9種SOTA GNN
Erdős-Rényi隨機圖
作者使用了五個二元分類數據集,包括與主題相連的隨機ER圖(正例)或與模體具有相同平均度的其他較小ER圖(負面例子)。
對于每個數據集,構建S個正例和S個負例,其中S=2048。
作者對GKAT、圖卷積網絡(GCNs)、譜圖卷積網絡(SGCs)和圖注意網絡(GATs)進行了測試。
每個頂點的特征向量長度為l=5,并包含其相鄰的頂序度數l(如果少于l,則填充0)。
每個模體的數據集被隨機分成75%的訓練集和25%的驗證集。
同時,采用學習率為η=0.001的Adam優化器,如果驗證損失和驗證準確率在c=80個連續的epoch中都沒有改善,則提前停止訓練。
對于模型來說,作者選擇使用雙層架構,并通過調整使所有模型的規模相當。
在GCN和SGC中,隱層中有h=32個節點。
在SGC中,將每個隱層與2個多項式局部過濾器結合。
在GAT和GKAT中,使用2個注意頭,隱層中有h=9個節點。
在GKAT中,使用長度為τ=3的隨機游走。

可以看出,GKAT在所有的模體上都優于其他方法。
檢測長誘導循環和深度與密度注意力測試
算法需要決定在給定的常數T下,圖形是否包含一個長度大于T的誘導循環。
因此,模體本身成為一個全局屬性,不能只通過探索一個節點的近鄰來檢測。
在這個實驗中,還要關注「深度與密度」的權衡。
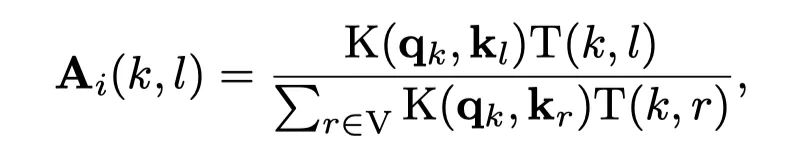
具有密集注意力的淺層神經網絡能夠對依靠稀疏層的深層網絡進行建模,然而代價是每層的額外計算成本。
在實驗中需要控制GCN、GAT和SGC的隱層的節點數,以及GAT的每個注意頭的數量,使它們的可訓練參數總量與雙層GKAT相當。
對于GKAT,在第一層應用8個頭,在第二層應用1個頭,每個頭的尺寸為d=4。
最后一層是全連接層,輸出維數為o=2,用于二進制分類,并采用τ=6的隨機游走長度。
GKAT不同長度的隨機游走結果
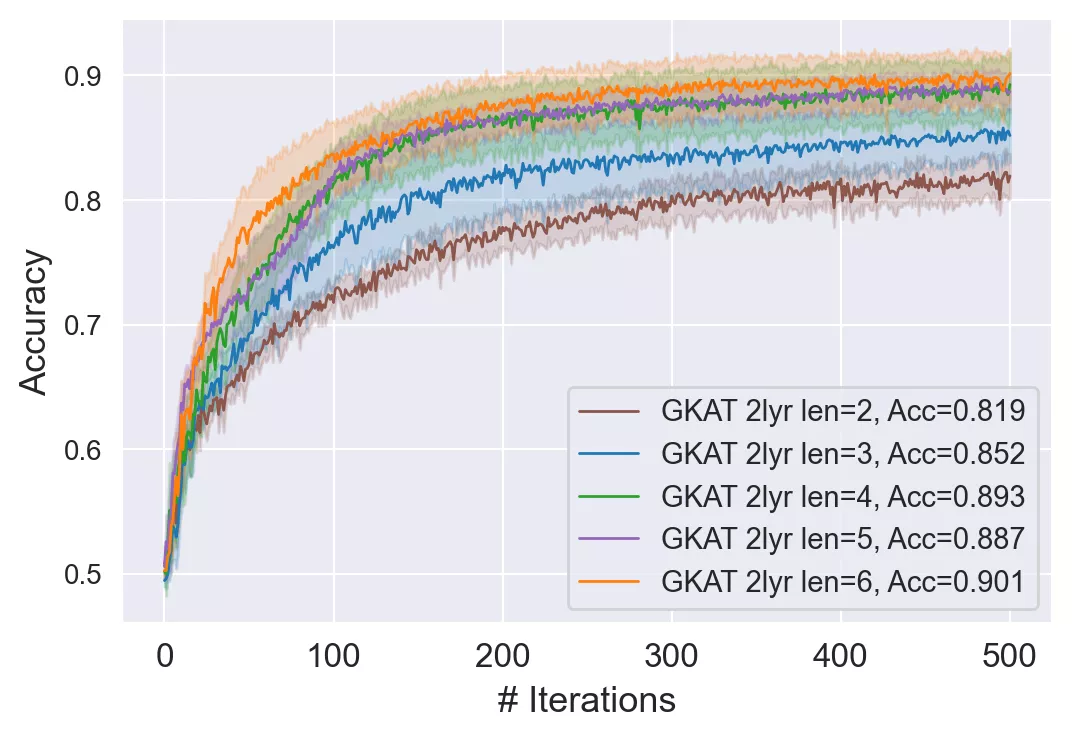
雙層GKAT與不同隱層數量(2-6)的GCN、GAT和SGC的比較
可以看到,更淺的GKAT幾乎擊敗了所有的GCN變體以及小于4層的GATs和SGCs。
此外,GKAT在趨勢上等同于四層GAT和SGC,但它在訓練和運行推理方面更快。
生物信息學任務和社交網絡數據測試
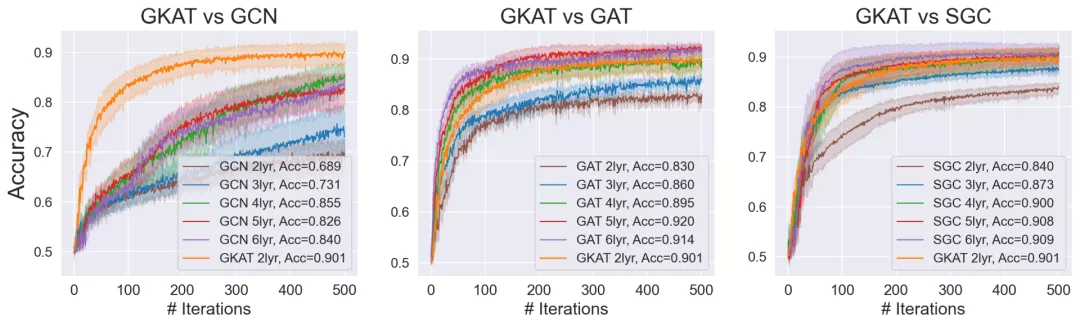
作者將GKAT與其他的SOTA GNN方法進行比較,其中包括:DCGNN, DiffPool, ECC, GraphSAGE和RWNN 。
對于生物信息學數據集,使用分子指紋(Molecular Fingerprint, MF)方法作為基線。
對于社交網絡數據集,使用深度多重集合(DeepMultisets, DM)方法作為基線。
在GKAT配置方面,首先應用了一個有k個頭的注意層(一個有待調整的超參數)。
然后是另一個有一個頭的注意層,以聚合圖上的拓撲信息。
接下來,應用MF方法或DM方法來進一步處理聚合的信息。
每個GKAT層中的隨機游走長度τ滿足:τ≤4,并且取決于所評估的數據集。
長的隨機游走原則上可以捕獲更多的信息,但代價是要增加非相關節點。

生物信息學數據集

社交網絡數據集
其中,平均圖徑(每對節點的最長最短路徑的平均值)有助于校準游走長度,并在實驗中選擇節點數與平均節點數最相似的圖。
作者在9個標準和公開的生物信息學和社交網絡數據集上測試了GKAT的圖分類任務。
對于每個數據集,表現最好的方法被加粗顯示,第二的由下劃線表示。
GKAT在生物信息學數據集的四個任務中有三個結果最好
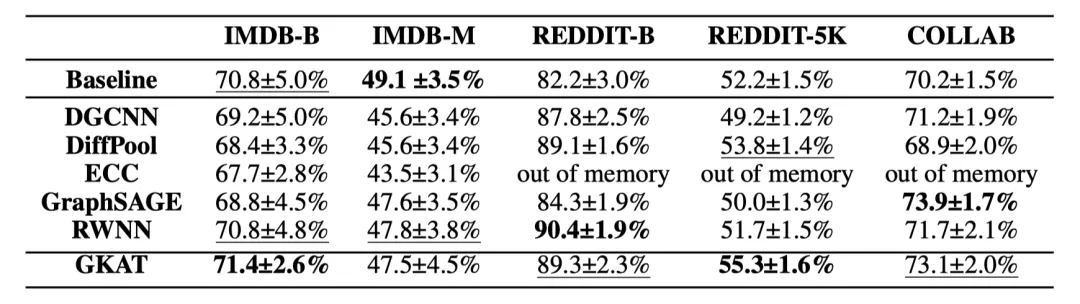
GKAT在社交網絡數據集的五個任務中有四個位居前兩位
值得注意的是,除了一個生物信息學數據集之外,GKAT是唯一一個在所有的生物信息學數據集上持續優于基線的GNN方法。
GKAT的空間和時間復雜度增益
作者對比了加入可分解注意力機制的GKAT(GKAT+)與GAT在速度和記憶上的改進,以及與常規的GKAT在準確性上的損失。
可以看到,相應的GKAT和GKAT+模型的準確率差距很小。
但是與GAT相比,GKAT+在每個注意層中產生了一致的速度和記憶增益,特別是對于那些來自Citeseer和Pubmed的非常大的圖形來說,這種增益是非常可觀的。
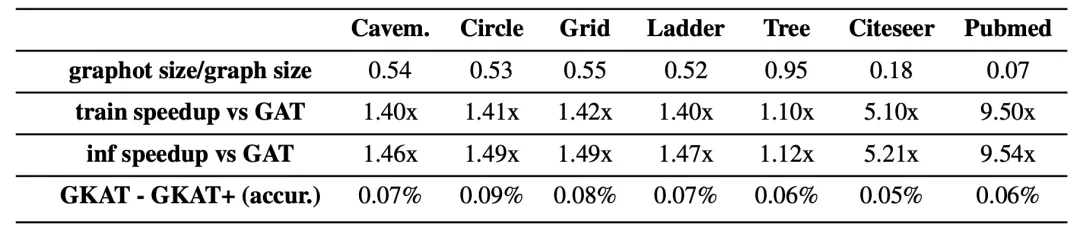
GKAT+在速度和空間復雜度方面的提升
第一行:通過graphot對圖形進行內存壓縮(越低越好)。
第二行和第三行:與GAT相比,每一個注意力層的訓練和推理速度分別提高。
第四行:與不應用可分解注意力機制的GKAT相比,準確率的下降。

訓練不同網絡的時間,均為雙層結構
此外,在達到特定精度水平所需的時間方面,常規的GKAT也比相應的模型(GCN、GAT和SGC)快。
總結
作者提出了一個全新的基于注意力的圖神經網:Graph Kernel Attention Transformers(GKATs):
- 利用了圖核方法和可擴展注意力
- 在處理圖數據方面更具表現力
- 具有低時間復雜性和內存占用
- 在廣泛的任務上優于其他SOTA模型