













研究表明強化學習模型容易受到成員推理攻擊
譯文?譯者 | 李睿
審校 | 孫淑娟?
隨著機器學習成為人們每天都在使用的很多應用程序的一部分,人們越來越關注如何識別和解決機器學習模型的安全和隱私方面的威脅。
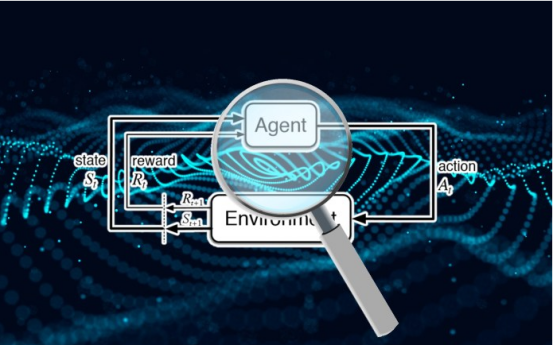
然而,不同機器學習范式面臨的安全威脅各不相同,機器學習安全的某些領域仍未得到充分研究。尤其是強化學習算法的安全性近年來并未受到太多關注。
加拿大的麥吉爾大學、機器學習實驗室(MILA)和滑鐵盧大學的研究人員開展了一項新研究,主要側重于深度強化學習算法的隱私威脅。研究人員提出了一個框架,用于測試強化學習模型對成員推理攻擊的脆弱性。
研究結果表明,攻擊者可以對深度強化學習(RL)系統進行有效攻擊,并可能獲得用于訓練模型的敏感信息。他們的研究成果意義重大,因為強化學習技術目前正在進入工業和消費者應用領域。
成員推理攻擊
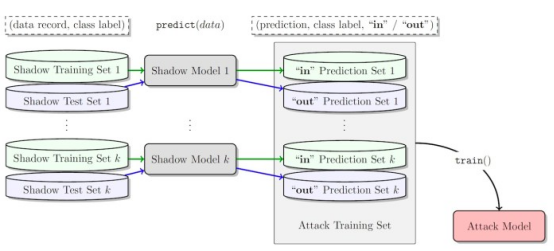
成員推理攻擊可以觀察目標機器學習模型的行為,并預測用于訓練它的示例。
每個機器學習模型都在一組示例上進行訓練。在某些情況下,訓練示例包括敏感信息,例如健康或財務數據或其他個人身份信息。
成員推理攻擊是一系列試圖強制機器學習模型泄露其訓練集數據的技術。雖然對抗性示例(針對機器學習的更廣為人知的攻擊類型)專注于改變機器學習模型的行為,并被視為安全威脅,但成員推理攻擊側重于從模型中提取信息,并且更多的是隱私威脅。
成員推理攻擊已經在有監督的機器學習算法中進行了深入研究,其中模型是在標記示例上進行訓練的。
與監督學習不同的是,深度強化學習系統不使用標記示例。強化學習(RL)代理從它與環境的交互中獲得獎勵或懲罰。它通過這些互動和強化信號逐漸學習和發展自己的行為。
該論文的作者在書面評論說,“強化學習中的獎勵不一定代表標簽;因此,它們不能充當其他學習范式中成員推理攻擊設計中經常使用的預測標簽。”
研究人員在他們的論文中寫道,“目前還沒有關于直接用于訓練深度強化學習代理的數據的潛在成員泄漏的研究。”
而缺乏這種研究的部分原因是強化學習在現實世界中的應用有限。
研究論文的作者說,“盡管深度強化學習領域取得了重大進展,例如Alpha Go、Alpha Fold和GT Sophy,但深度強化學習模型仍未在工業規模上得到廣泛采用。另一方面,數據隱私是一個應用非常廣泛的研究領域,深度強化學習模型在實際工業應用中的缺乏極大地延遲了這一基礎和重要研究領域的研究,導致對強化學習系統的攻擊的研究不足。”
隨著在現實世界場景中工業規模應用強化學習算法的需求不斷增長,從對抗性和算法的角度對解決強化學習算法隱私方面的框架的關注和嚴格要求變得越來越明顯和相關。
深度強化學習中成員推斷的挑戰
研究論文的作者說,“我們在開發第一代保護隱私的深度強化學習算法方面所做出的努力,使我們意識到從隱私的角度來看,傳統機器學習算法和強化學習算法之間存在根本的結構差異。”
研究人員發現,更關鍵的是,考慮到潛在的隱私后果,深度強化學習與其他學習范式之間的根本差異在為實際應用部署深度強化學習模型方面提出了嚴峻挑戰。
他們說,“基于這一認識,對我們來說最大的問題是:深度強化學習算法對隱私攻擊(如成員推斷攻擊)的脆弱性有多大?現有的成員推理攻擊攻擊模型是專門為其他學習范式設計的,因此深度強化學習算法對這類攻擊的脆弱程度在很大程度上是未知的。鑒于在世界范圍內部署對隱私的嚴重影響,這種對未知事物的好奇心以及提高研究和工業界意識的必要性是這項研究的主要動機。”
在訓練過程中,強化學習模型經歷了多個階段,每個階段都由動作和狀態的軌跡或序列組成。因此,一個成功的用于強化學習的成員推理攻擊算法必須學習用于訓練模型的數據點和軌跡。一方面,這使得針對強化學習系統設計成員推理算法變得更加困難;而另一方面,也使得難以評估強化學習模型對此類攻擊的魯棒性。
作者說,“與其他類型的機器學習相比,在強化學習中成員推理攻擊(MIA)很困難,因為在訓練過程中使用的數據點具有順序和時間相關的性質。訓練和預測數據點之間的多對多關系從根本上不同于其他學習范式。”
強化學習和其他機器學習范式之間的根本區別,使得在設計和評估用于深度強化學習的成員推理攻擊時以新的方式思考至關重要。
設計針對強化學習系統的成員推理攻擊
在他們的研究中,研究人員專注于非策略強化學習算法,其中數據收集和模型訓練過程是分開的。強化學習使用“重放緩沖區”來解相關輸入軌跡,并使強化學習代理可以從同一組數據中探索許多不同的軌跡。
非策略強化學習對于許多實際應用程序尤其重要,在這些應用程序中,訓練數據預先存在并提供給正在訓練強化學習模型的機器學習團隊。非策略強化學習對于創建成員推理攻擊模型也至關重要。
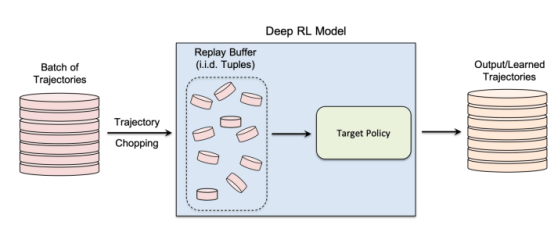
非策略強化學習使用“重放緩沖區”在模型訓練期間重用先前收集的數據
作者說,“探索和開發階段在真正的非策略強化學習模型中是分離的。因此,目標策略不會影響訓練軌跡。這種設置特別適合在黑盒環境中設計成員推理攻擊框架時,因為攻擊者既不知道目標模型的內部結構,也不知道用于收集訓練軌跡的探索策略。”
在黑盒成員推理攻擊中,攻擊者只能觀察訓練好的強化學習模型的行為。在這種特殊情況下,攻擊者假設目標模型已經從一組私有數據生成的軌跡上進行了訓練,這就是非策略強化學習的工作原理。
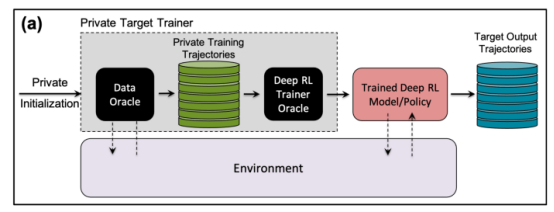
在研究中,研究人員選擇了“批量約束深度Q學習”(BCQ),這是一種先進的非策略強化學習算法,在控制任務中表現出卓越的性能。然而他們表示,他們的成員推理攻擊技術可以擴展到其他非策略強化學習模型。
攻擊者進行成員推理攻擊的一種方法是開發“影子模型”。這是一個分類器機器學習模型,它已經在來自與目標模型的訓練數據和其他地方的相同分布的數據混合上進行了訓練。在訓練之后,影子模型可以區分屬于目標機器學習模型訓練集的數據點和模型以前未見過的新數據。由于目標模型訓練的順序性,為強化學習代理創建影子模型很棘手。研究人員通過幾個步驟實現了這一點。
首先,他們為強化學習模型訓練器提供一組新的非私有數據軌跡,并觀察目標模型生成的軌跡。然后,攻擊訓練器使用訓練和輸出軌跡來訓練機器學習分類器,以檢測在目標強化學習模型訓練中使用的輸入軌跡。最后,為分類器提供了新的軌跡,將其分類為訓練成員或新的數據示例。
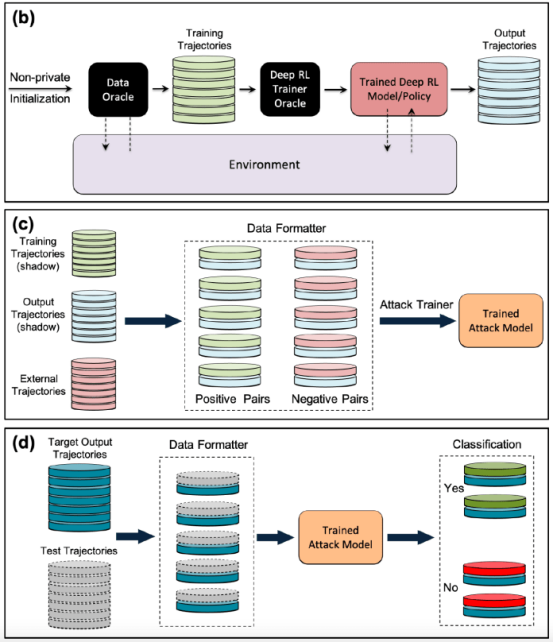
針對強化學習模型訓練成員推理攻擊的影子模型
針對強化學習系統測試成員推理攻擊
研究人員以不同的模式測試了他們的成員推理攻擊,其中包括不同的軌跡長度、單軌跡與多軌跡,以及相關軌跡與去相關軌跡。
研究人員在他們的論文中指出:“研究結果表明,我們提出的攻擊框架在推斷強化學習模型訓練數據點方面非常有效……獲得的結果表明,采用深度強化學習時存在很高的隱私風險。”
他們的研究結果表明,具有多條軌跡的攻擊比單一軌跡的攻擊更有效,并且隨著軌跡變長并相互關聯,攻擊的準確性也會提高。
作者說,“自然設置當然是個體模型,攻擊者有興趣在用于訓練目標強化學習策略的訓練集中識別特定個體的存在(在強化學習中設置整個軌跡)。然而,成員推理攻擊(MIA)在集體模式下的更好表現表明,除了由訓練策略的特征捕獲的時間相關性之外,攻擊者還可以利用目標策略的訓練軌跡之間的互相關性。”
研究人員表示,這也意味著攻擊者需要更復雜的學習架構和更復雜的超參數調整,以利用訓練軌跡之間的互相關和軌跡內的時間相關性。
研究人員說,“了解這些不同的攻擊模式,可以讓我們更深入地了解對數據安全和隱私的影響,因為它可以讓我們更好地了解可能發生攻擊的不同角度以及對隱私泄露的影響程度。”
現實世界中針對強化學習系統的成員推理攻擊
研究人員測試了他們對基于Open AIGym和MuJoCo物理引擎的三項任務訓練的強化學習模型的攻擊。
研究人員說,“我們目前的實驗涵蓋了三個高維運動任務,Hopper、Half-Cheetah和Ant,這些任務都屬于機器人模擬任務,主要推動將實驗擴展到現實世界的機器人學習任務。”
該論文的研究人員表示,另一個應用成員推斷攻擊的令人興奮的方向是對話系統,例如亞馬遜Alexa、蘋果Siri和谷歌助理。在這些應用程序中,數據點由聊天機器人和最終用戶之間的完整交互軌跡呈現。在這一設置中,聊天機器人是經過訓練的強化學習策略,用戶與機器人的交互形成輸入軌跡。
作者說,“在這種情況下,集體模式就是自然環境。換句話說,當且僅當攻擊者正確推斷出代表訓練集中用戶的一批軌跡時,攻擊者才能推斷出用戶在訓練集中的存在。”
該團隊正在探索此類攻擊可能影響強化學習系統的其他實際應用程序。他們可能還會研究這些攻擊如何應用于其他環境中的強化學習。
作者說,“這一研究領域的一個有趣擴展是在白盒環境中針對深度強化學習模型研究成員推理攻擊,其中目標策略的內部結構也為攻擊者所知。”
研究人員希望他們的研究能夠闡明現實世界中強化學習應用程序的安全和隱私問題,并提高機器學習社區的意識,以便在該領域開展更多研究。
原文標題:??Reinforcement learning models are prone to membership inference attacks???,作者:Ben Dickson




























