SFT在幫倒忙?新研究:直接進行強化學習,模型多模態推理上限更高
隨著 OpenAI 的 o1/o3 和 Deepseek-R1 等具備強大推理能力的大語言模型相繼問世,學界普遍采用「監督微調 + 強化學習」的兩階段訓練范式:先通過推理數據進行監督微調(SFT),再通過強化學習(RL)進一步提升性能。這種成功模式啟發了研究人員將其優勢從純文本領域拓展到視覺 - 語言大模型(LVLM)領域。
但近日的一項研究成果卻給出了一個驚人的發現:「SFT 可能會阻礙學習 —— 經常導致出現偽推理路徑,而 RL 則是在促進真正的多模態推理!」

這個發現來自加州大學圣克魯茲分校和德克薩斯大學達拉斯分校等機構的一個研究團隊,他們深入探討了「SFT+RL」這一經典范式在視覺語言模型開發中的適用性,其中重點關注了兩個核心問題:1)SFT 與 RL 在多模態推理中分別產生何種獨特作用?2)這種兩階段訓練對 LVLM 的推理能力是否確有必要?

- 論文標題: SFT or RL? An Early Investigation into Training R1-Like Reasoning Large Vision-Language Models
- 論文地址:https://arxiv.org/pdf/2504.11468
- 項目頁面:https://ucsc-vlaa.github.io/VLAA-Thinking/
為系統性地研究這些問題,研究者構建了首個支持 SFT 與 RL 的全方位高質量圖文推理數據集 VLAA-Thinking。下表給出了該數據集的統計數據。

與現有數據集不同,該數據集包含基于 R1 模型「先思考后回答」范式生成的完整推理鏈條,其中 SFT 分支包含適合視覺指令調優的多模態思維鏈(CoT)樣本,強化學習分支則從同源數據中篩選更具挑戰性的樣本以激發深度推理行為。
為有效遷移純文本模型的推理能力,研究者設計了六階段數據處理流程:元數據收集→圖像描述生成→基于 R1 的知識蒸餾→答案重寫→人工驗證→數據劃分。
具體而言,他們將圖像描述和視覺問題輸入 DeepSeek-R1 生成初始推理軌跡,經改寫優化流暢度后,再由 GPT 驗證器進行質量把關,最終形成高質量的 SFT 與 RL 訓練數據。
意料之外的發現
基于 VLAA-Thinking 數據集,研究者系統分析了 SFT 與 RL 在多模態推理中的作用機制。為探究 SFT 的影響,他們詳細考察了數據類型(如是否包含反思性頓悟時刻,即 aha moment)、數據規模和模型能力等因素。
針對視覺語境下的 RL 優化,他們在 GRPO 框架中創新性地設計了融合感知與認知獎勵的混合獎勵函數,包含 2 大類 5 種子函數:規則類問題采用數字識別、多項選擇題、數學運算和邊界框檢測函數,開放類問題則采用稱職的獎勵模型 XComposer-2.5-RM,以及基于參考的獎勵方法來對答案進行評分。
研究者對 SFT 和 RL 進行了廣泛的實驗比較,發現了幾個值得注意的問題:
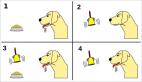
首先,他們探究了 SFT 和 RL 在多模態推理中的貢獻:與基礎模型相比,SFT 提高了模型在標準任務中的性能,但在增強復雜推理方面能力卻有所欠缺。如圖 1 所示,僅僅通過 SFT 來模仿專家的思維往往會誘發「偽推理路徑」,這是一種膚淺的推理模式,其中可能包含「偽 aha moment」(膚淺的自我反思線索)。

這項研究表明,這些模仿的推理模式會阻礙真正的推理進步,即在 7B 模型上相對性能下降 47%。這一觀察結果也與最近的研究結果一致,即需要反饋和探索信號來驅動高級推理行為。此外,消融分析表明,對于基于規則的獎勵,數學和多選題比其他獎勵更有益,而基于規則和開放式獎勵的結合則能得到最佳性能。

現有研究認為 LVLM 應先通過 SFT 學習推理格式,再通過 RL 反饋進行優化,但研究者發現:如果對已對齊的模型使用 SFT+GRPO,會導致平均 12.7% 的性能下降,且模型規模差異影響甚微 ——7B 模型與更小模型呈現相似的性能衰減。

訓練過程分析表明,響應長度、獎勵分數與性能表現無顯著相關性:經 SFT 的模型雖能獲得更高初始獎勵和更長響應,但實際表現遜于純 RL 訓練模型,這與「更優模型通常產生更長響應」的既有結論相悖。
研究表明:SFT 雖可幫助未對齊模型遵循指令,但其倡導的模仿式推理會限制 RL 階段的探索空間;相比之下,直接從獎勵信號學習能產生更有效的適應性思維。實證研究表明純 RL 方案更具優勢 —— 該團隊訓練得到的 VLAA-Thinker-Qwen2.5VL-3B 模型在 Open LMM 推理榜單 4B 量級模型中位列第一,以 1.8% 優勢刷新紀錄。案例分析表明,該模型生成的推理軌跡更簡潔有效。
使用混合獎勵提升多模態推理
上面的結果表明 SFT 不足以將 R1 的能力遷移到 LVLM。于是,研究者提出了自己的方案。
由于強化學習在增強推理能力方面表現出色,且 GRPO 在文本數學推理任務中被證明比其他方法(如 PPO)更有效、更高效,這促使他們將 GRPO 訓練應用于視覺語言推理任務。
數學上,設 q 為一個查詢, 為從舊策略模型 π_old 中采樣的 G 個輸出,GRPO 最大化以下目標:
為從舊策略模型 π_old 中采樣的 G 個輸出,GRPO 最大化以下目標:

其中, 是估計的優勢,β 是 KL 懲罰系數,π_θ、π_θ_old、π_ref 分別是當前、舊的和參考的策略。
是估計的優勢,β 是 KL 懲罰系數,π_θ、π_θ_old、π_ref 分別是當前、舊的和參考的策略。
帶有混合獎勵的 GRPO
為了更好地將 GRPO 應用于多模態推理,除了采用類似文本 GRPO 訓練中的基于規則的獎勵機制外,還需要考慮視覺模態引入的額外特征。受多模態大型語言模型綜合評價基準 MME 的啟發(MME 通過感知和認知(推理)來對視覺語言模型進行基準測試),研究者提出了一個用于 GRPO 訓練的混合獎勵框架,如圖 4 所示。該獎勵系統包含五種可驗證的獎勵類型,采用兩種格式,涵蓋了視覺感知和視覺推理任務。

SFT 對 GRPO 訓練的影響
SFT 與多模態推理中的 GRPO 不兼容。 盡管論文中揭示了單獨使用 SFT 會導致多模態推理性能下降,但目前仍不清楚 SFT 是否像 DeepSeekR1 中的「金鑰匙」一樣對 GRPO 訓練起到關鍵作用。研究者使用不同的模型架構進行 GRPO 訓練實驗。具體來說,他們采用了 Qwen2VL-7B-Base 和 Qwen2VL-7B-Inst,并在它們上使用 25K 樣本進行 SFT,隨后進行 GRPO 訓練。
從表 3 中可以觀察到,在 GRPO 訓練之前進行 SFT 的模型,其性能比僅使用 GRPO 訓練的模型更差,平均而言,Qwen2VL-Base 和 Qwen2VL-Inst 在經過 SFT 后比未經過 SFT 的模型性能下降了 8.9%。研究者還發現,SFT 對指令模型的性能損害比對沒有指令跟隨能力的基礎模型更大。例如,經過 SFT 后,Qwen2VL-Inst 的性能比 Qwen2VL-Base 下降了 7.7%,這表明 SFT 可能會削弱對有效 GRPO 訓練至關重要的指令跟隨能力。
綜合這些結果,可以得出結論:在多模態推理的背景下,SFT 目前與 GRPO 不兼容,會損害基礎模型和經過指令調優的 LVLM 的性能。

此外,研究者還發現,較小的 SFT 數據集仍然會影響 GRPO 的性能,如圖 5 所示。

回應長度、獎勵與模型性能并非必然相關。先前的強化學習研究通常認為,更長的回應往往與更好的推理能力以及更高的 RL 獎勵相關。然而,圖 6 中的發現表明,在 GRPO 中,回應長度和獎勵并不是推理能力的可靠指標。

有趣的是,經過 SFT 的模型在訓練初期的獎勵更高。這可能是由于它們在早期通過監督學習獲得了經驗,因為 SFT 和 GRPO 數據共享相同的分布。然而,這些經過 SFT 的模型在訓練過程中獎勵提升有限,而僅使用 GRPO 的模型則迅速超過了它們。
這些趨勢進一步揭示,SFT 僅提供了 RL 訓練的一個更高的「下限」,但它可能會降低「上限」,因為推理相關的 SFT 數據限制了模型的探索路徑。因此,推理是一種內生的、更可能通過強化學習而非 SFT 發展起來的能力。盡管經過 SFT 的模型可能看起來在進行推理,但它們的行為更接近于模式模仿 —— 一種缺乏泛化推理能力的偽推理形式。
無 SFT 的 GRPO 訓練
根據前一節的發現,研究者直接進行了 GRPO 訓練,生成了四個模型:VLAA-Thinker-Qwen2-VL-2B、VLAA-Thinker-Qwen2-VL-7B、VLAA-Thinker-Qwen2.5-VL-3B 和 VLAA-Thinker-Qwen2.5-VL-7B。他們還在 Qwen2-VL-7B 的基礎模型上進行了訓練,得到的模型命名為 VLAA-Thinker-Qwen2-7B-Zero。
表 4 中展示了評估結果:

主要發現如下:
- 直接使用 GRPO 訓練的模型在視覺語言推理任務中顯著優于其基礎模型。
- 經過更好指令調優的模型在 GRPO 訓練后表現更佳,說明高質量的指令調優能夠增強模型在強化學習后的推理能力。
- GRPO 訓練能夠誘導模型產生真實的自我反思行為,但「aha」時刻的數量與整體推理性能并不直接相關。(見圖 7)

更多細節請參見原論文。