一篇文章幫助小白快速入門 Spark

大家好,我是Tom哥。
互聯(lián)網(wǎng)時(shí)代,隨著業(yè)務(wù)數(shù)據(jù)化,數(shù)據(jù)越來越多。如何用好數(shù)據(jù),做好數(shù)據(jù)業(yè)務(wù)化,我們需要有個(gè)利器。
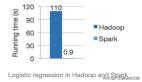
很多人都用過Hadoop,包含兩部分 HDFS 和 MapReduce,其中 MapReduce 是Hadoop的分布式計(jì)算引擎,計(jì)算過程中需要頻繁落盤,性能會(huì)弱一些。
今天,帶大家 快速熟悉一個(gè)大數(shù)據(jù)框架,Spark。
Spark 是內(nèi)存計(jì)算引擎,性能更好一些。盛行自 2014年,支持 流計(jì)算 Streaming、數(shù)據(jù)分析 SQL、機(jī)器學(xué)習(xí) MLlib、圖計(jì)算 GraphFrames 等多種場(chǎng)景。
語(yǔ)言支持很多,如 Python、Java、Scala、R 和 SQL。提供了種類豐富的開發(fā)算子,如 RDD、DataFrame、Dataset。
有了這些基礎(chǔ)工具,開發(fā)者就可以像搭樂高一樣,快速完成各種業(yè)務(wù)場(chǎng)景系統(tǒng)開發(fā)。
一、先來個(gè)體感
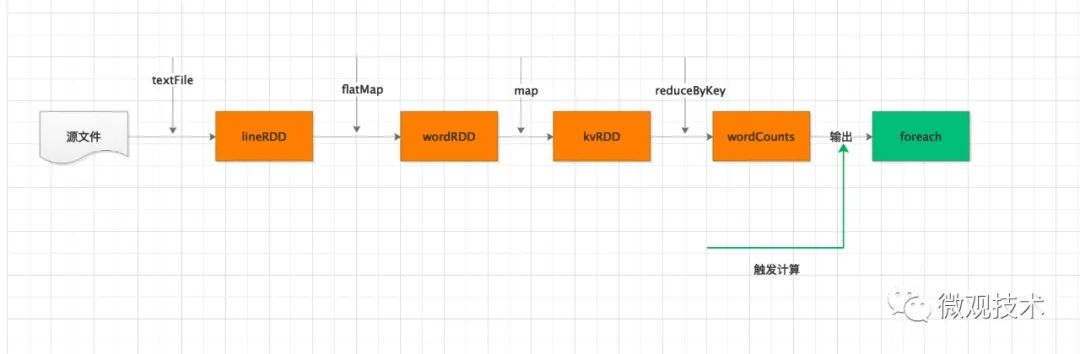
首先,我們看一個(gè)簡(jiǎn)單的代碼示例,讓大家有個(gè)體感。
import org.apache.spark.rdd.RDD
val file: String = "/Users/onlyone/spark/demo.txt"
// 加載文件
val lineRDD: RDD[String] = spark.sparkContext.textFile(file)
val wordRDD: RDD[String] = lineRDD.flatMap(line => line.split(" "))
val kvRDD: RDD[(String, Int)] = wordRDD.map(word => (word, 1))
val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)
wordCounts.foreach(wordCount => println(wordCount._1 + " appeared " + wordCount._2 + " times"))
我們看到,入口代碼是從第四行的 spark 變量開始。
在 spark-shell 中 由系統(tǒng)自動(dòng)創(chuàng)建,是 SparkSession 的實(shí)例化對(duì)象,可以直接使用,不需要每次自己 new 一個(gè)新對(duì)象。
SparkSession 是 Spark 程序的統(tǒng)一開發(fā)入口。開發(fā)一個(gè) Spark 應(yīng)用,必須先創(chuàng)建 SparkSession。
二、RDD
彈性分布式數(shù)據(jù)集,全稱 Resilient Distributed Datasets,是一種抽象,囊括所有內(nèi)存和磁盤中的分布式數(shù)據(jù)實(shí)體,是Spark最核心的模塊和類。
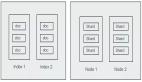
RDD 中承載數(shù)據(jù)的基本單元是數(shù)據(jù)分片。在分布式計(jì)算環(huán)境中,一份完整的數(shù)據(jù)集,會(huì)按照某種規(guī)則切割成多份數(shù)據(jù)分片。這些數(shù)據(jù)分片被均勻地分發(fā)給集群內(nèi)不同的計(jì)算節(jié)點(diǎn)和執(zhí)行進(jìn)程,從而實(shí)現(xiàn)分布式并行計(jì)算。
RDD 包含 4大屬性:
- 數(shù)據(jù)分片,partitions。
- 分片切割規(guī)則, partitioner。
- RDD 依賴關(guān)系, dependencies。
- 轉(zhuǎn)換函數(shù),compute。
RDD 表示的是分布式數(shù)據(jù)形態(tài),RDD 到 RDD 之間的轉(zhuǎn)換,本質(zhì)上是數(shù)據(jù)形態(tài)上的轉(zhuǎn)換,這里面的一個(gè)重要角色就是算子。
三、算子
算子分為兩大類,Transformations 和 Actions。
- Transformations 算子:通過函數(shù)方法對(duì)數(shù)據(jù)從一種形態(tài)轉(zhuǎn)換為另一種形態(tài)。
- Actions 算子:收集計(jì)算結(jié)果,或者將數(shù)據(jù)物化到磁盤。

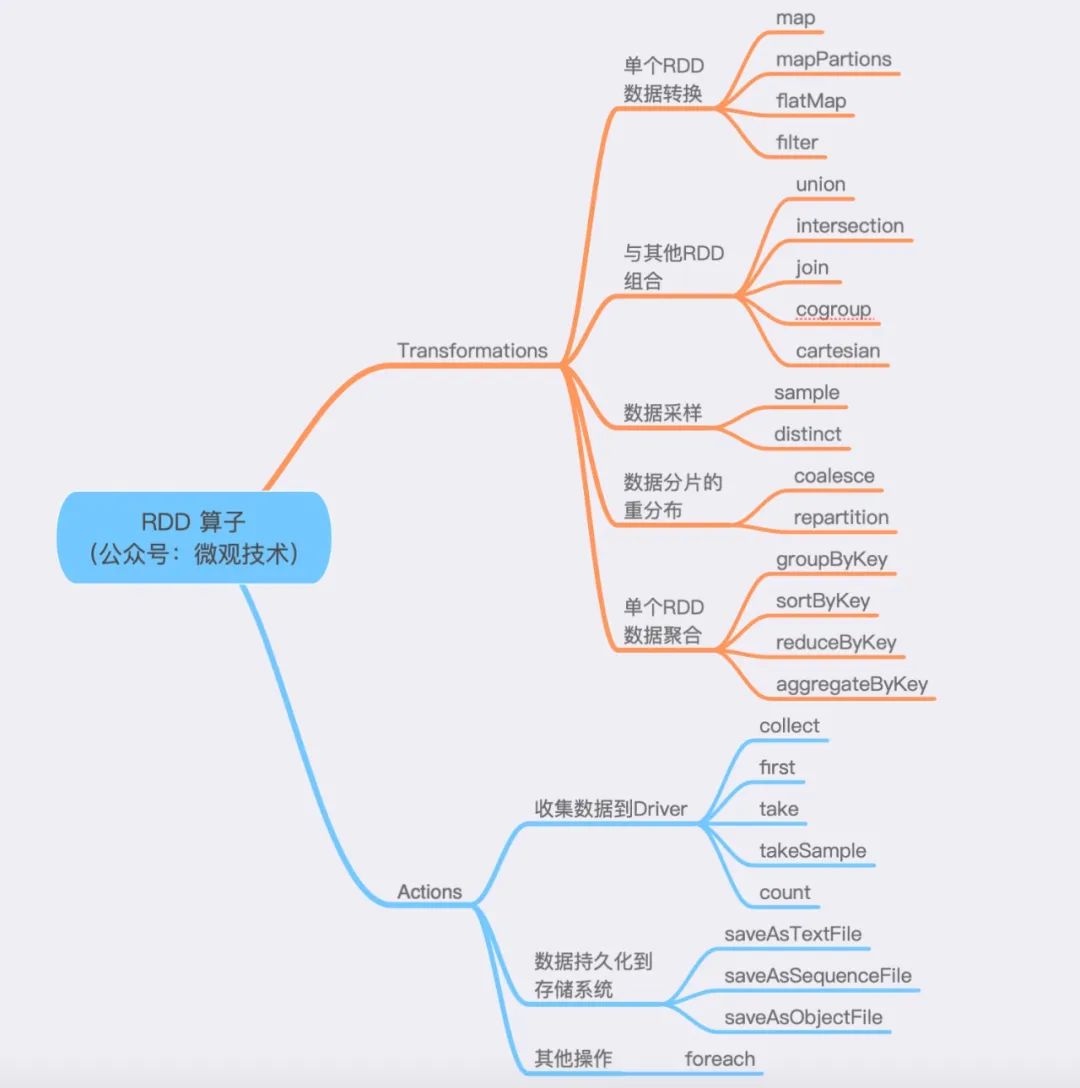
劃重點(diǎn):mapPartitions 與 map 的功能類似,但是mapPartitions 算子是以數(shù)據(jù)分區(qū)為粒度初始化共享對(duì)象,比如:數(shù)據(jù)庫(kù)連接對(duì)象,S3文件句柄等。
結(jié)合上面的兩類算子,Spark 運(yùn)行劃分為兩個(gè)環(huán)節(jié):
- 不同數(shù)據(jù)形態(tài)之間的轉(zhuǎn)換,構(gòu)建計(jì)算流圖 (DAG)。
- 通過 Actions 類算子,以回溯的方式去觸發(fā)執(zhí)行這個(gè)計(jì)算流圖。

題外話,回溯在Java 中也有引入,比如 Stream 流也是類似機(jī)制。
一個(gè)流程可能會(huì)引入很多算子,但是他們并不會(huì)立即執(zhí)行,只有當(dāng)開發(fā)者調(diào)用了 Actions 算子,之前調(diào)用的轉(zhuǎn)換算子才會(huì)執(zhí)行。這個(gè)也稱為 延遲計(jì)算。
延遲計(jì)算是 Spark 分布式運(yùn)行機(jī)制的一大亮點(diǎn)。可以讓執(zhí)行引擎從全局角度來優(yōu)化執(zhí)行流程。
四、分布式計(jì)算
Spark 應(yīng)用中,程序的入口是帶有 SparkSession 的 main 函數(shù)。
SparkSession 提供了 Spark 運(yùn)行時(shí)的上下文,如 調(diào)度系統(tǒng)、存儲(chǔ)系統(tǒng)、內(nèi)存管理、RPC 通信),同時(shí)為開發(fā)者提供創(chuàng)建、轉(zhuǎn)換、計(jì)算分布式數(shù)據(jù)集的開發(fā) API。
運(yùn)行這個(gè) SparkSession 的main函數(shù)的JVM進(jìn)程,我們稱為 Driver。
Driver 職責(zé):
解析用戶代碼,構(gòu)建 DAG 圖,然后將計(jì)算流圖轉(zhuǎn)化為分布式任務(wù),將任務(wù)分發(fā)給集群的 Executor 執(zhí)行。定期與每個(gè) Executor 通信,及時(shí)獲取任務(wù)的進(jìn)展,從而協(xié)調(diào)整體的執(zhí)行進(jìn)度。
Executors 職責(zé):
調(diào)用內(nèi)部線程池,結(jié)合事先分配好的數(shù)據(jù)分片,并發(fā)地執(zhí)行任務(wù)代碼。每個(gè) Executors 負(fù)責(zé)處理 RDD 的一個(gè)數(shù)據(jù)分片子集。
分布式計(jì)算的核心是任務(wù)調(diào)度,主要是 Driver 與 Executors 之間的交互。
Driver 的任務(wù)調(diào)度依賴于 DAGScheduler、TaskScheduler 和 SchedulerBackend。
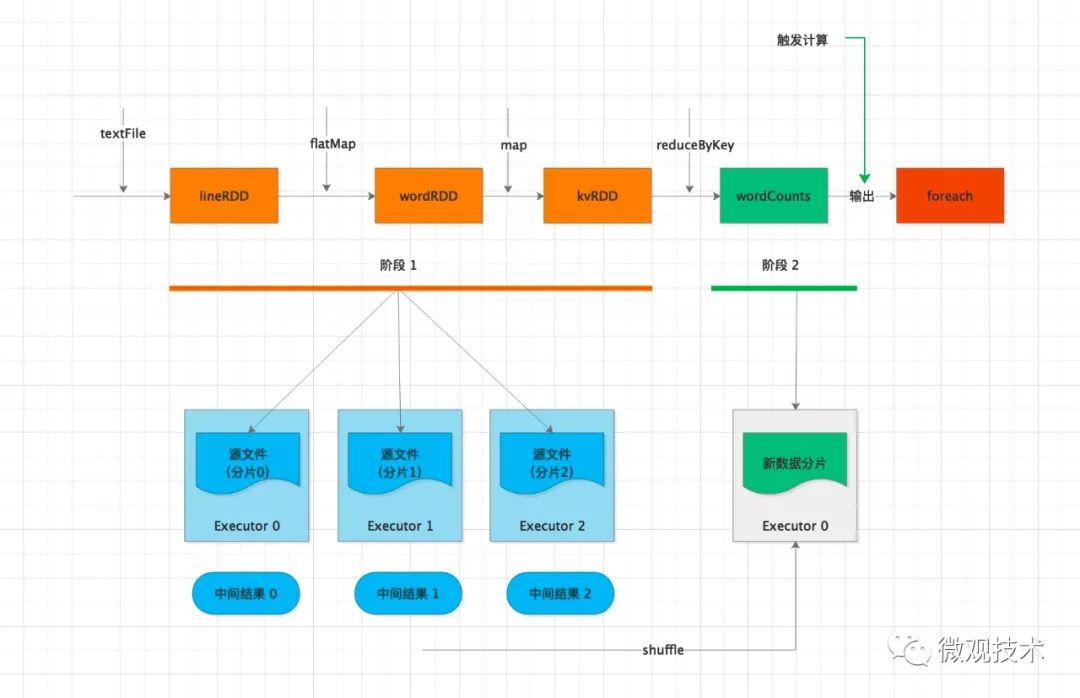
計(jì)算過程:
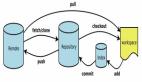
Driver 通過 foreach 這個(gè) Action 算子,觸發(fā)計(jì)算流圖的執(zhí)行,上圖自左向右執(zhí)行,以 shuffle 為邊界,創(chuàng)建、分發(fā)分布式任務(wù)。
其中的 textFile、flatMap、map 三個(gè)算子合并成一份任務(wù),分發(fā)給每一個(gè) Executor。Executor 收到任務(wù)后,對(duì)任務(wù)進(jìn)行解析,把任務(wù)拆解成 textFile、flatMap、map 3 個(gè)步驟,然后分別對(duì)自己負(fù)責(zé)的數(shù)據(jù)分片進(jìn)行處理。
每個(gè) Executor 執(zhí)行完得到中間結(jié)果,然后向 Driver 匯報(bào)任務(wù)進(jìn)度。接著 Driver 進(jìn)行后續(xù)的聚合計(jì)算,由于數(shù)據(jù)分散在多個(gè)分片,會(huì)觸發(fā) shuffle 操作。
shuffle 機(jī)制是將原來多個(gè) Executor中的計(jì)算結(jié)果重新路由、分發(fā)到同一個(gè) Executor,然后對(duì)匯總后的數(shù)據(jù)再次處理。在集群范圍內(nèi)跨進(jìn)程、跨節(jié)點(diǎn)的數(shù)據(jù)交換。可能存在網(wǎng)絡(luò)性能瓶頸,需要特別關(guān)注。
在不同 Executor 完成數(shù)據(jù)交換之后,Driver 分發(fā)下一個(gè)階段的任務(wù),對(duì)單詞計(jì)數(shù)。
同一個(gè)key的數(shù)據(jù)已經(jīng)分發(fā)到相同的 Executor ,每個(gè) Executor 獨(dú)自完成計(jì)數(shù)統(tǒng)計(jì)。
最后,Executors 把最終的計(jì)算結(jié)果統(tǒng)一返回給 Driver。
劃重點(diǎn):DAG 到 Stages 的拆分過程,以 Actions 算子為觸發(fā)起點(diǎn),從后往前回溯 DAG,以 Shuffle 為邊界劃分 Stages。
收集結(jié)果:
收集結(jié)果,按照收集的路徑不同,主要分為兩類:
- 把計(jì)算結(jié)果從各個(gè) Executors 收集到 Driver 端。
- 把計(jì)算結(jié)果通過 Executors 直接持久化到文件系統(tǒng)。如:HDFS 或 S3 分布式文件系統(tǒng)。
五、調(diào)度系統(tǒng)
1、DAGScheduler
根據(jù)用戶代碼構(gòu)建 DAG,以 Shuffle 為邊界切割 Stages。每個(gè)Stage 根據(jù) RDD中的Partition分區(qū)個(gè)數(shù)決定Task的個(gè)數(shù),然后構(gòu)建 TaskSets,然后將 TaskSets 提交給 TaskScheduler 請(qǐng)求調(diào)度。
2、TaskScheduler
按照任務(wù)的本地傾向性,挑選出 TaskSet 中適合調(diào)度的 Task,然后將 Task 分配到 Executor 上執(zhí)行。
3、SchedulerBackend
通過ExecutorDataMap 數(shù)據(jù)結(jié)構(gòu),來記錄每一個(gè)計(jì)算節(jié)點(diǎn)中 Executors 的資源狀態(tài),如 RPC 地址、主機(jī)地址、可用 CPU 核數(shù)和滿配 CPU 核數(shù)等。
4、Task
運(yùn)行在Executor上的工作單元。
5、Job
SparkContext提交的具體Action操作,常和Action對(duì)應(yīng)。
6、Stage
每個(gè)Job會(huì)被拆分很多組任務(wù)(task),每組任務(wù)被稱為Stage,也稱 TaskSet。
調(diào)度系統(tǒng)的核心思想:數(shù)據(jù)不動(dòng)、代碼動(dòng)。
六、內(nèi)存管理
Spark 的內(nèi)存分為 4 個(gè)區(qū)域,Reserved Memory、User Memory、Execution Memory 和 Storage Memory。

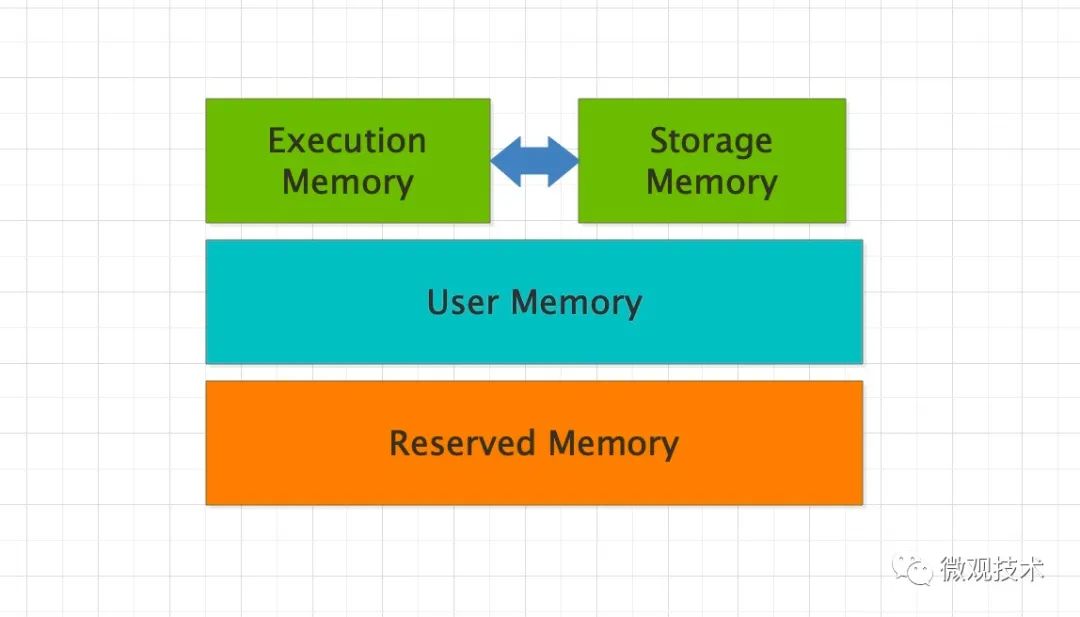
- Reserved Memory:固定為 300MB,Spark 預(yù)留的,用來存儲(chǔ)各種 Spark 內(nèi)部對(duì)象的內(nèi)存區(qū)域。
- User Memory:存儲(chǔ)開發(fā)者自定義的數(shù)據(jù)結(jié)構(gòu),例如 RDD 算子中引用的數(shù)組、列表、映射。
- Execution Memory:執(zhí)行分布式任務(wù)。分布式任務(wù)的計(jì)算,主要包括數(shù)據(jù)的轉(zhuǎn)換、過濾、映射、排序、聚合、歸并等。
- Storage Memory:緩存分布式數(shù)據(jù)集,如 RDD Cache、廣播變量等。
整個(gè)內(nèi)存區(qū)域,Execution Memory 和 Storage Memory 最重要。在 1.6 版本之后,Spark 推出了統(tǒng)一內(nèi)存管理模式,這兩者可以相互轉(zhuǎn)化。
七、共享變量
Spark 提供兩類共享變量,分別是廣播變量(Broadcast variables)和累加器(Accumulators)。
1、廣播變量
val list: List[String] = List("Tom哥", "Spark")
// sc為SparkContext實(shí)例
val bc = sc.broadcast(list)
廣播變量的用法很簡(jiǎn)單,通過調(diào)用 SparkContext 下的 broadcast 即可完成廣播變量的創(chuàng)建。
如果要讀取封裝的共享數(shù)據(jù)內(nèi)容,調(diào)用它的 bc.value 函數(shù)。
好奇寶寶會(huì)問,既然 list 可以獲取字符串列表,為什么還要封裝廣播變量呢?
答案:
Driver 端對(duì)普通的共享變量的分發(fā)是以 Task 為粒度的,系統(tǒng)中有多少個(gè) Task,變量就需要在網(wǎng)絡(luò)中分發(fā)多少次,存在巨大的內(nèi)存資源浪費(fèi)。
使用廣播變量后,共享變量分發(fā)的粒度以 Executors 為單位,同一個(gè) Executor 內(nèi)多個(gè)不同的 Tasks 只需訪問同一份數(shù)據(jù)拷貝即可。也就是說,變量在網(wǎng)絡(luò)中分發(fā)與存儲(chǔ)的次數(shù),從 RDD 的分區(qū)數(shù),減少為集群中 Executors 的個(gè)數(shù)。
2、累加器
累加器也是在 Driver 端定義,累計(jì)過程是通過在 RDD 算子中調(diào)用 add 函數(shù)為累加器計(jì)數(shù),從而更新累加器狀態(tài)。
應(yīng)用執(zhí)行完畢之后,開發(fā)者在 Driver 端調(diào)用累加器的 value 函數(shù),獲取全局計(jì)數(shù)結(jié)果。
Spark 提供了 3 種累加器,longAccumulator、doubleAccumulator 和 collectionAccumulator ,滿足不同的業(yè)務(wù)場(chǎng)景。