一篇文章了解 Spark Shuffle 內存使用
在使用 Spark 進行計算時,我們經常會碰到作業 (Job) Out Of Memory(OOM) 的情況,而且很大一部分情況是發生在 Shuffle 階段。那么在 Spark Shuffle 中具體是哪些地方會使用比較多的內存而有可能導致 OOM 呢? 為此,本文將圍繞以上問題梳理 Spark 內存管理和 Shuffle 過程中與內存使用相關的知識;然后,簡要分析下在 Spark Shuffle 中有可能導致 OOM 的原因。
一、Spark 內存管理和消費模型
在分析 Spark Shuffle 內存使用之前。我們首先了解下以下問題:當一個 Spark 子任務 (Task) 被分配到 Executor 上運行時,Spark 管理內存以及消費內存的大體模型是什么樣呢?(注:由于 OOM 主要發生在 Executor 端,所以接下來的討論主要針對 Executor 端的內存管理和使用)。
1,在 Spark 中,使用抽象類 MemoryConsumer 來表示需要使用內存的消費者。在這個類中定義了分配,釋放以及 Spill 內存數據到磁盤的一些方法或者接口。具體的消費者可以繼承 MemoryConsumer 從而實現具體的行為。 因此,在 Spark Task 執行過程中,會有各種類型不同,數量不一的具體消費者。如在 Spark Shuffle 中使用的 ExternalAppendOnlyMap, ExternalSorter 等等(具體后面會分析)。
2,MemoryConsumer 會將申請,釋放相關內存的工作交由 TaskMemoryManager 來執行。當一個 Spark Task 被分配到 Executor 上運行時,會創建一個 TaskMemoryManager。在 TaskMemoryManager 執行分配內存之前,需要首先向 MemoryManager 進行申請,然后由 TaskMemoryManager 借助 MemoryAllocator 執行實際的內存分配。
3,Executor 中的 MemoryManager 會統一管理內存的使用。由于每個 TaskMemoryManager 在執行實際的內存分配之前,會首先向 MemoryManager 提出申請。因此 MemoryManager 會對當前進程使用內存的情況有著全局的了解。
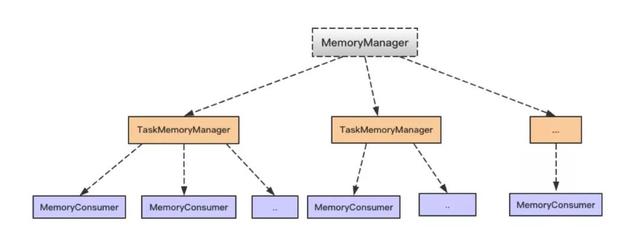
MemoryManager,TaskMemoryManager 和 MemoryConsumer 之前的對應關系,如下圖。總體上,一個 MemoryManager 對應著至少一個 TaskMemoryManager (具體由 executor-core 參數指定),而一個 TaskMemoryManager 對應著多個 MemoryConsumer (具體由任務而定)。
了解了以上內存消費的整體過程以后,有兩個問題需要注意下:
1,當有多個 Task 同時在 Executor 上執行時, 將會有多個 TaskMemoryManager 共享 MemoryManager 管理的內存。那么 MemoryManager 是怎么分配的呢?答案是每個任務可以分配到的內存范圍是 [1 / (2 * n), 1 / n],其中 n 是正在運行的 Task 個數。因此,多個并發運行的 Task 會使得每個 Task 可以獲得的內存變小。
2,前面提到,在 MemoryConsumer 中有 Spill 方法,當 MemoryConsumer 申請不到足夠的內存時,可以 Spill 當前內存到磁盤,從而避免無節制的使用內存。但是,對于堆內內存的申請和釋放實際是由 JVM 來管理的。因此,在統計堆內內存具體使用量時,考慮性能等各方面原因,Spark 目前采用的是抽樣統計的方式來計算 MemoryConsumer 已經使用的內存,從而造成堆內內存的實際使用量不是特別準確。從而有可能因為不能及時 Spill 而導致 OOM。
二、Spark Shuffle 過程
整體上 Spark Shuffle 具體過程如下圖,主要分為兩個階段:Shuffle Write 和 Shuffle Read。
Write 階段大體經歷排序(最低要求是需要按照分區進行排序),可能的聚合 (combine) 和歸并(有多個文件 spill 磁盤的情況 ),最終每個寫 Task 會產生數據和索引兩個文件。其中,數據文件會按照分區進行存儲,即相同分區的數據在文件中是連續的,而索引文件記錄了每個分區在文件中的起始和結束位置。
而對于 Shuffle Read, 首先可能需要通過網絡從各個 Write 任務節點獲取給定分區的數據,即數據文件中某一段連續的區域,然后經過排序,歸并等過程,最終形成計算結果。
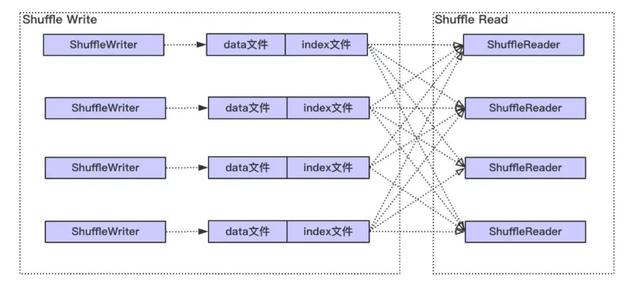
對于 Shuffle Write,Spark 當前有三種實現,具體分別為 BypassMergeSortShuffleWriter, UnsafeShuffleWriter 和 SortShuffleWriter (具體使用哪一個實現有一個判斷條件,此處不表)。而 Shuffle Read 只有一種實現。
2.1 Shuffle Write 階段分析
2.1.1 BypassMergeSortShuffleWriter 分析
對于 BypassMergeSortShuffleWriter 的實現,大體實現過程是首先為每個分區創建一個臨時分區文件,數據寫入對應的分區文件,最終所有的分區文件合并成一個數據文件,并且產生一個索引文件。由于這個過程不做排序,combine(如果需要 combine 不會使用這個實現)等操作,因此對于 BypassMergeSortShuffleWriter,總體來說是不怎么耗費內存的。
2.1.2 SortShuffleWriter 分析
SortShuffleWriter 是最一般的實現,也是日常使用最頻繁的。SortShuffleWriter 主要委托 ExternalSorter 做數據插入,排序,歸并 (Merge),聚合 (Combine) 以及最終寫數據和索引文件的工作。ExternalSorter 實現了之前提到的 MemoryConsumer 接口。下面分析一下各個過程使用內存的情況:
1,對于數據寫入,根據是否需要做 Combine,數據會被插入到 PartitionedAppendOnlyMap 這個 Map 或者 PartitionedPairBuffer 這個數組中。每隔一段時間,當向 MemoryManager 申請不到足夠的內存時,或者數據量超過 spark.shuffle.spill.numElementsForceSpillThreshold 這個閾值時 (默認是 Long 的最大值,不起作用),就會進行 Spill 內存數據到文件。假設可以源源不斷的申請到內存,那么 Write 階段的所有數據將一直保存在內存中,由此可見,PartitionedAppendOnlyMap 或者 PartitionedPairBuffer 是比較吃內存的。
2,無論是 PartitionedAppendOnlyMap 還是 PartitionedPairBuffer, 使用的排序算法是 TimSort。在使用該算法是正常情況下使用的臨時額外空間是很小,但是最壞情況下是 n / 2,其中 n 表示待排序的數組長度(具體見 TimSort 實現)。
3,當插入數據因為申請不到足夠的內存將會 Spill 數據到磁盤,在將最終排序結果寫入到數據文件之前,需要將內存中的 PartitionedAppendOnlyMap 或者 PartitionedPairBuffer 和已經 spill 到磁盤的 SpillFiles 進行合并。Merge 的大體過程如下圖。
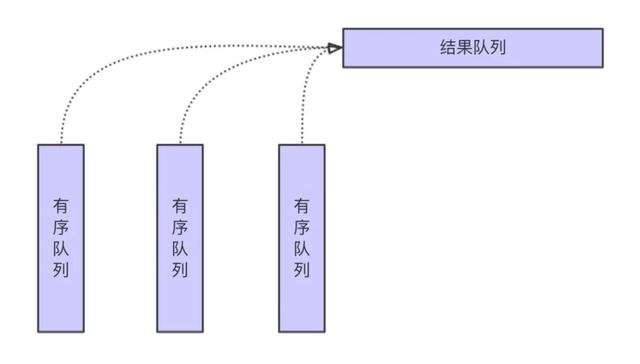
從上圖可見,大體差不多就是歸并排序的過程,由此可見這個過程是沒有太多額外的內存消耗。歸并過程中的聚合計算大體也是差不多的過程,唯一需要注意的是鍵值碰撞的情況,即當前輸入的各個有序隊列的鍵值的哈希值相同,但是實際的鍵值不等的情況。這種情況下,需要額外的空間保存所有鍵值不同,但哈希值相同值的中間結果。但是總體上來說,發生這種情況的概率并不是特別大。
4,寫數據文件的過程涉及到不同數據流之間的轉化,而在流的寫入過程中,一般都有緩存,主要由參數 spark.shuffle.file.buffer 和 spark.shuffle.spill.batchSize 控制,總體上這部分開銷也不大。
以上分析了 SortShuffleWriter write 階段的主要過程,從中可以看出主要的內存消耗在寫入 PartitionedAppendOnlyMap 或者 PartitionedPairBuffer 這個階段。
2.1.3 UnsafeShuffleWriter
UnsafeShuffleWriter 是對 SortShuffleWriter 的優化,大體上也和 SortShuffleWriter 差不多,在此不再贅述。從內存使用角度看,主要差異在以下兩點:
一方面,在 SortShuffleWriter 的 PartitionedAppendOnlyMap 或者 PartitionedPairBuffer 中,存儲的是鍵值或者值的具體類型,也就是 Java 對象,是反序列化過后的數據。而在 UnsafeShuffleWriter 的 ShuffleExternalSorter 中數據是序列化以后存儲到實際的 Page 中,而且在寫入數據過程中會額外寫入長度信息。總體而言,序列化以后數據大小是遠遠小于序列化之前的數據。
另一方面,UnsafeShuffleWriter 中需要額外的存儲記錄(LongArray),它保存著分區信息和實際指向序列化后數據的指針(經過編碼的Page num 以及 Offset)。相對于 SortShuffleWriter, UnsafeShuffleWriter 中這部分存儲的開銷是額外的。
2.2 Shuffle Read 階段分析
Spark Shuffle Read 主要經歷從獲取數據,序列化流,添加指標統計,可能的聚合 (Aggregation) 計算以及排序等過程。大體流程如下圖。
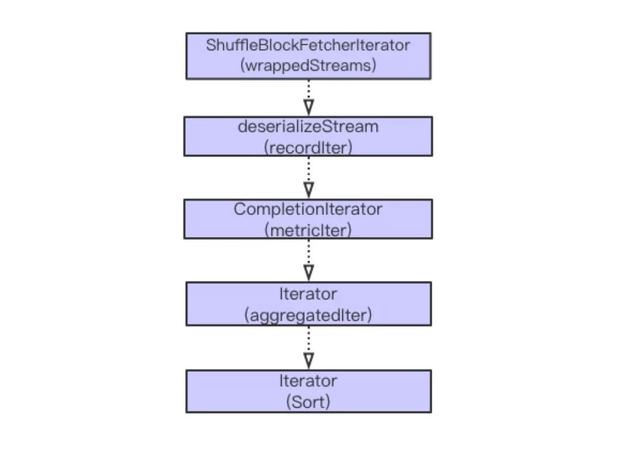
以上計算主要都是迭代進行。在以上步驟中,比較復雜的操作是從遠程獲取數據,聚合和排序操作。接下來,依次分析這三個步驟內存的使用情況。
1,數據獲取分為遠程獲取和本地獲取。本地獲取將直接從本地的 BlockManager 取數據, 而對于遠程數據,需要走網絡。在遠程獲取過程中,有相關參數可以控制從遠程并發獲取數據的大小,正在獲取數據的請求數,以及單次數據塊請求是否放到內存等參數。具體參數包括 spark.reducer.maxSizeInFlight (默認 48M),spark.reducer.maxReqsInFlight, spark.reducer.maxBlocksInFlightPerAddress 和 spark.maxRemoteBlockSizeFetchToMem。
考慮到數據傾斜的場景,如果 Map 階段有一個 Block 數據特別的大,默認情況由于 spark.maxRemoteBlockSizeFetchToMem 沒有做限制,所以在這個階段需要將需要獲取的整個 Block 數據放到 Reduce 端的內存中,這個時候是非常的耗內存的。可以設置 spark.maxRemoteBlockSizeFetchToMem 值,如果超過該閾值,可以落盤,避免這種情況的 OOM。 另外,在獲取到數據以后,默認情況下會對獲取的數據進行校驗(參數 spark.shuffle.detectCorrupt 控制),這個過程也增加了一定的內存消耗。
2,對于需要聚合和排序的情況,這個過程是借助 ExternalAppendOnlyMap 來實現的。整個插入,Spill 以及 Merge 的過程和 Write 階段差不多。總體上,這塊也是比較消耗內存的,但是因為有 Spill 操作,當內存不足時,可以將內存數據刷到磁盤,從而釋放內存空間。
三、Spark Shuffle OOM 可能性分析
圍繞內存使用,前面比較詳細的分析了 Spark 內存管理以及在 Shuffle 過程可能使用較多內存的地方。接下來總結的要點如下:
1,首先需要注意 Executor 端的任務并發度,多個同時運行的 Task 會共享 Executor 端的內存,使得單個 Task 可使用的內存減少。
2,無論是在 Map 還是在 Reduce 端,插入數據到內存,排序,歸并都是比較都是比較占用內存的。因為有 Spill,理論上不會因為數據傾斜造成 OOM。 但是,由于對堆內對象的分配和釋放是由 JVM 管理的,而 Spark 是通過采樣獲取已經使用的內存情況,有可能因為采樣不準確而不能及時 Spill,導致OOM。
3,在 Reduce 獲取數據時,由于數據傾斜,有可能造成單個 Block 的數據非常的大,默認情況下是需要有足夠的內存來保存單個 Block 的數據。因此,此時極有可能因為數據傾斜造成 OOM。 可以設置 spark.maxRemoteBlockSizeFetchToMem 參數,設置這個參數以后,超過一定的閾值,會自動將數據 Spill 到磁盤,此時便可以避免因為數據傾斜造成 OOM 的情況。在我們的生產環境中也驗證了這點,在設置這個參數到合理的閾值后,生產環境任務 OOM 的情況大大減少了。
4,在 Reduce 獲取數據后,默認情況會對數據流進行解壓校驗(參數 spark.shuffle.detectCorrupt)。正如在代碼注釋中提到,由于這部分沒有 Spill 到磁盤操作,也有很大的可性能會導致 OOM。在我們的生產環境中也有碰到因為檢驗導致 OOM 的情況。
四、小結
本文主要圍繞內存使用這個點,對 Spark shuffle 的過程做了一個比較詳細的梳理,并且分析了可能造成 OOM 的一些情況以及我們在生產環境碰到的一些問題。本文主要基于作者對 Spark 源碼的理解以及實際生產過程中遇到 OOM 案例總結而成,限于經驗等各方面原因,難免有所疏漏或者有失偏頗。如有問題,歡迎聯系一起討論。