













一文介紹機器學習中的三種特征選擇方法

機器學習中的特征需要選擇,人生又何嘗不是如此?
特征選擇是指從眾多可用的特征中選擇一個子集的過程,其目的和預期效果一般有如下三方面考慮:
- 改善模型效果,主要是通過過濾無效特征或者噪聲特征來實現;
- 加速模型訓練,更為精簡的特征空間自然可以實現模型訓練速度的提升
- 增強特征可解釋性,這方面的作用一般不是特別明顯,比如存在共線性較高的一組特征時,通過合理的特征選擇可僅保留高效特征,從而提升模型的可解釋性
另一方面,理解特征選擇方法的不同,首先需要按照特征對訓練任務的價值高低而對特征作出如下分類:
- 高價值特征,這些特征對于模型訓練非常有幫助,特征選擇的目的就是盡可能精準的保留這些特征
- 低價值特征,這些特征對模型訓練幫助不大,但也屬于正相關特征,在特征選擇比例較低時,這些特征可以被舍棄;
- 高相關性特征,這些特征對模型訓練也非常有幫助,但特征與特征之間往往相關性較高,換言之一組特征可由另一組特征替代,所以是存在冗余的特征,在特征選擇中應當將其過濾掉;
- 噪聲特征,這些特征對模型訓練不但沒有正向作用,反而會干擾模型的訓練效果。有效的特征選擇方法應當優先將其濾除。
在實際應用中,特征選擇方法主要可分為如下三類:
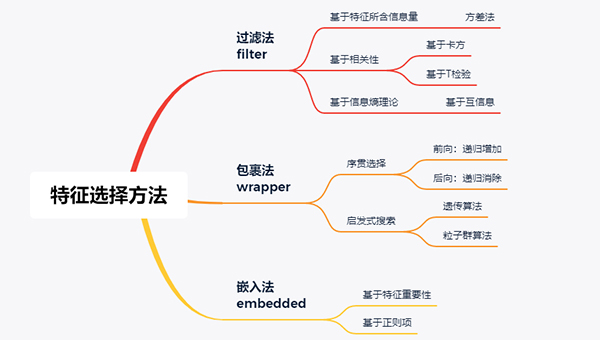
本文將圍繞這三種方法分別介紹,最后以sklearn中自帶的數據集為例給出簡單的應用和效果對比。
01 過濾法
基于過濾法(Filter)實現特征選擇是最為簡單和常用的一種方法,其最大優勢是不依賴于模型,僅從特征的角度來挖掘其價值高低,從而實現特征排序及選擇。實際上,基于過濾法的特征選擇方案,其核心在于對特征進行排序——按照特征價值高低排序后,即可實現任意比例/數量的特征選擇或剔除。顯然,如何評估特征的價值高低從而實現排序是這里的關鍵環節。
為了評估特征的價值高低,大體可分為如下3類評估標準:
- 基于特征所含信息量的高低:這種一般就是特征基于方差法實現的特征選擇,即認為方差越大對于標簽的可區分性越高;否則,即低方差的特征認為其具有較低的區分度,極端情況下當一列特征所有取值均相同時,方差為0,對于模型訓練也不具有任何價值。當然,實際上這里倘若直接以方差大小來度量特征所含信息量是不嚴謹的,例如對于[100, 110, 120]和[1, 5, 9]兩組特征來說,按照方差計算公式前者更大,但從機器學習的角度來看后者可能更具有區分度。所以,在使用方差法進行特征選擇前一般需要對特征做歸一化
- 基于相關性:一般是基于統計學理論,逐一計算各列與標簽列的相關性系數,當某列特征與標簽相關性較高時認為其對于模型訓練價值更大。而度量兩列數據相關性的指標則有很多,典型的包括歐式距離、卡方檢驗、T檢驗等等
- 基于信息熵理論:與源于統計學的相關性方法類似,也可從信息論的角度來度量一列特征與標簽列的相關程度,典型的方法就是計算特征列與標簽列的互信息。當互信息越大時,意味著提供該列特征時對標簽的信息確定程度越高。這與決策樹中的分裂準則思想其實是有異曲同工之妙
當然,基于過濾法的特征選擇方法其弊端也極為明顯:
- 因為不依賴于模型,所以無法有針對性的挖掘出適應模型的最佳特征體系;
- 特征排序以及選擇是獨立進行(此處的獨立是指特征與特征之間的獨立,不包含特征與標簽間的相關性計算等),對于某些特征單獨使用價值低、組合使用價值高的特征無法有效發掘和保留。
02 包裹法
過濾法是從特征重要性高低的角度來加以排序,從而完成目標特征選擇或者低效特征濾除的過程。如前所述,其最大的弊端之一在于因為不依賴任何模型,所以無法針對性的選擇出相應模型最適合的特征體系。同時,其還存在一個隱藏的問題:即特征選擇保留比例多少的問題,實際上這往往是一個超參數,一般需要人為定義或者進行超參尋優。
與之不同,包裹法將特征選擇看做是一個黑盒問題:即僅需指定目標函數(這個目標函數一般就是特定模型下的評估指標),通過一定方法實現這個目標函數最大化,而不關心其內部實現的問題。進一步地,從具體實現的角度來看,給定一個含有N個特征的特征選擇問題,可將其抽象為從中選擇最優的K個特征子集從而實現目標函數取值最優。易見,這里的K可能是從1到N之間的任意數值,所以該問題的搜索復雜度是指數次冪:O(2^N)。
當然,對于這樣一個具有如此高復雜度的算法,聰明的前輩們是不可能去直接暴力嘗試的,尤其是考慮這個目標函數往往還是足夠expensive的(即模型在特定的特征子集上的評估過程一般是較為耗時的過程),所以具體的實現方式一般有如下兩種:
- 序貫選擇。美其名曰序貫選擇,其實就是貪心算法。即將含有K個特征的最優子空間搜索問題簡化為從1->K的遞歸式選擇(Sequential Feature Selection, SFS)或者從N->K的遞歸式消除(Sequential Backward Selection, SBS)的過程,其中前者又稱為前向選擇,后者相應的稱作后向選擇。
- 具體而言,以遞歸式選擇為例,初始狀態時特征子空間為空,嘗試逐一選擇每個特征加入到特征子空間中,計算相應的目標函數取值,執行這一過程N次,得到當前最優的第1個特征;如此遞歸,不斷選擇得到第2個,第3個,直至完成預期的特征數目K。這一過程的目標函數執行次數為O(K^2),相較于指數次冪的算法復雜度而言已經可以接受。當然,在實際應用過程中還衍生了很多改進算法,例如下面流程圖所示:
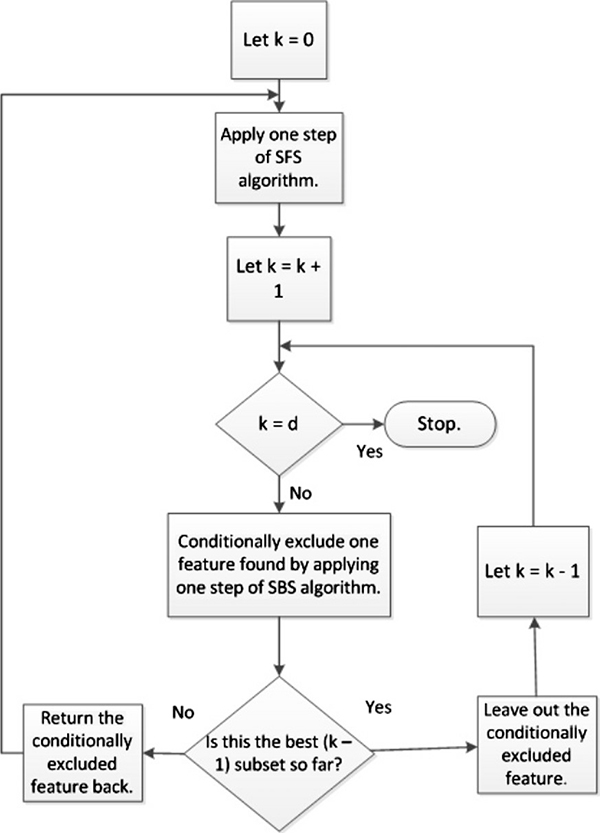
圖源:《A survey on feature selection methods》
- 啟發式搜索。啟發式搜索一般是應用了進化算法,例如在優化領域廣泛使用的遺傳算法。在具體實現中,需要考慮將特征子空間如何表達為種群中的一個個體(例如將含有N個特征的選擇問題表達為長度為N的0/1序列,其中1表示選擇該特征,0表示不選擇,序列中1的個數即為特征子空間中的特征數量),進而可將模型在相應特征子空間的效果定義為對應個體在種群中的適應度;其次就是定義遺傳算法中的主要操作:交叉、變異以及繁殖等進化過程。
基于包裹法的特征選擇方案是面向模型的實現方案,所以理論而言具有最佳的選擇效果。但實際上在上述實現過程中,其實一般也需要預先指定期望保留的特征數量,所以也就涉及到超參的問題。此外,基于包裹法的最大缺陷在于巨大的計算量,雖然序貫選擇的實現方案將算法復雜度降低為平方階,但仍然是一個很大的數字;而以遺傳算法和粒子群算法為代表的啟發式搜索方案,由于其均是population-based的優化實現,自然也更是涉及大量計算。
03 嵌入法
與包裹法依賴于模型進行選擇的思想相似,而又與之涉及巨大的計算量不同:基于嵌入法的特征選擇方案,顧名思義,是將特征選擇的過程"附著"于一個模型訓練任務本身,從而依賴特定算法模型完成特征選擇的過程。
個人一直以為,"嵌入"(embedded)一詞在機器學習領域是一個很魔性的存在,甚至在剛接觸特征選擇方法之初,一度將嵌入法和包裹法混淆而不能感性理解。
實際上,行文至此,基于嵌入法的特征選擇方案也就呼之欲出了,最為常用的就是樹模型和以樹模型為基礎的系列集成算法,由于模型提供了特征重要性這個重要信息,所以其可天然的實現模型價值的高低,從而根據特征重要性的高低完成特征選擇或濾除的過程。另外,除了決策樹系列模型外,LR和SVM等廣義線性模型也可通過擬合權重系數來評估特征的重要程度。
基于嵌入法的特征選擇方案簡潔高效,一般被視作是集成了過濾法和包裹法兩種方案的優點:既具有包裹法中面向模型特征選擇的優勢,又具有過濾法的低開銷和速度快。但實際上,其也具有相應的短板:不能識別高相關性特征,例如特征A和特征B都具有較高的特征重要性系數,但同時二者相關性較高,甚至說特征A=特征B,此時基于嵌入法的特征選擇方案是無能為力的。
04 三種特征選擇方案實戰對比
本小節以sklearn中的乳腺癌數據集為例,給出三種特征選擇方案的基本實現,并簡單對比特征選擇結果。
加載數據集并引入必備包:
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import SelectFromModel, SelectKBest, RFE
from sklearn.ensemble import RandomForestClassifier
默認數據集訓練模型,通過在train_test_split中設置隨機數種子確保后續切分一致:
%%time
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=3)
rf = RandomForestClassifier(max_depth=5, random_state=3)
rf.fit(X_train, y_train)
rf.score(X_test, y_test)
# 輸出結果
CPU times: user 237 ms, sys: 17.5 ms, total: 254 ms
Wall time: 238 ms
0.9370629370629371
過濾法的特征選擇方案,調用sklearn中的SelectKBest實現,內部默認采用F檢驗來度量特征與標簽間相關性,選擇特征維度設置為20個:
%%time
X_skb = SelectKBest(k=20).fit_transform(X, y)
X_skb_train, X_skb_test, y_train, y_test = train_test_split(X_skb, y, random_state=3)
rf = RandomForestClassifier(max_depth=5, random_state=3)
rf.fit(X_skb_train, y_train)
rf.score(X_skb_test, y_test)
# 輸出結果
CPU times: user 204 ms, sys: 7.14 ms, total: 211 ms
Wall time: 208 ms
0.9300699300699301
包裹法的特征選擇方案,調用sklearn中的RFE實現,傳入的目標函數也就是算法模型為隨機森林,特征選擇維度也設置為20個:
%%time
X_rfe = RFE(RandomForestClassifier(), n_features_to_select=20).fit_transform(X, y)
X_rfe_train, X_rfe_test, y_train, y_test = train_test_split(X_rfe, y, random_state=3)
rf = RandomForestClassifier(max_depth=5, random_state=3)
rf.fit(X_rfe_train, y_train)
rf.score(X_rfe_test, y_test)
# 輸出結果
CPU times: user 2.76 s, sys: 4.57 ms, total: 2.76 s
Wall time: 2.76 s
0.9370629370629371
嵌入法的特征選擇方案,調用sklearn中的SelectFromModel實現,依賴的算法模型也設置為隨機森林,特征選擇維度仍然是20個:
%%time
X_sfm = SelectFromModel(RandomForestClassifier(), threshold=-1, max_features=20).fit_transform(X, y)
X_sfm_train, X_sfm_test, y_train, y_test = train_test_split(X_sfm, y, random_state=3)
rf = RandomForestClassifier(max_depth=5, random_state=3)
rf.fit(X_sfm_train, y_train)
rf.score(X_sfm_test, y_test)
# 輸出結果
CPU times: user 455 ms, sys: 0 ns, total: 455 ms
Wall time: 453 ms
0.9370629370629371
通過以上簡單的對比實驗可以發現:相較于原始全量特征的方案,在僅保留20維特征的情況下,過濾法帶來了一定的算法性能損失,而包裹法和嵌入法則保持了相同的模型效果,但嵌入法的耗時明顯更短。

























