一文讀懂機器學習中的模型偏差
在人工智能(AI)和機器學習(ML)領(lǐng)域,將預測模型參與決策過程的手段越來越常見,但難點是決策者需要確保這些模型不會根據(jù)模型預測做出偏見或者不公平的決策(有意或無意的歧視)。設想一下銀行業(yè)、保險業(yè)和就業(yè)等行業(yè),在確定面試候選人、批準貸款/信貸、額定保險費等環(huán)節(jié)中使用模型作為解決方案,如果最終決策出現(xiàn)偏差,對最終用戶造成的傷害有多大?因此,對于研究ML問題的產(chǎn)品經(jīng)理、業(yè)務分析師和數(shù)據(jù)科學家來說,理解模型預測偏差的不同細微差至關(guān)重要。
什么是ML模型的公平和偏差
機器學習模型中的偏差是由缺乏足夠的特征和用于訓練模型的相關(guān)數(shù)據(jù)集不全面引起的。鑒于用于訓練模型的特征和相關(guān)數(shù)據(jù)是由人類設計和收集的,數(shù)據(jù)科學家和產(chǎn)品經(jīng)理的偏見可能會影響訓練模型的數(shù)據(jù)準備。例如:在收集數(shù)據(jù)特征的過程中,遺漏掉一個或多個特征 ,或者用于訓練的數(shù)據(jù)集的覆蓋范圍不夠。換句話說,模型可能無法正確捕獲數(shù)據(jù)集中存在的基本規(guī)則,由此產(chǎn)生的機器學習模型最終將出現(xiàn)偏差(高偏差)。
可以通過以下幾個方面進一步理解機器學習模型偏差:
缺乏適當?shù)墓δ芸赡軙a(chǎn)生偏差。這樣的模型是欠擬合的,即模型表現(xiàn)出高偏差和底方差。 缺乏適當?shù)臄?shù)據(jù)集:盡管功能是適當?shù)模狈m當?shù)臄?shù)據(jù)也會導致偏見。大量不同性質(zhì)的(覆蓋不同場景的)數(shù)據(jù)可以解決偏差問題。然而,必須注意避免過度高方差,這可能會影響模型性能,因為模型無法推廣所有類型的數(shù)據(jù)集。
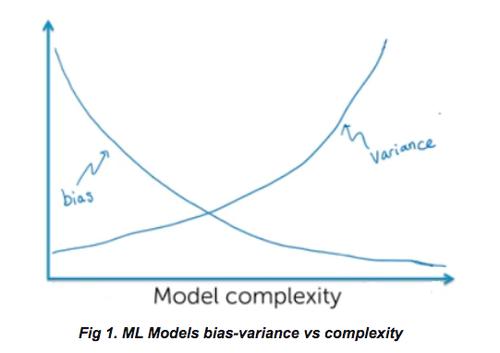
如果發(fā)現(xiàn)模型具有高偏差,則該模型將被稱為不公平,反之亦然。需注意的是,減少偏差的嘗試可能會導致具有高方差的高復雜度模型。下圖代表了模型在偏差和方差方面的復雜性。
注意:隨著偏差的減小,模型越來越復雜,可能會出現(xiàn)高方差。
如何測試ML模型的公平/偏差
想要測試ML模型是公平的還是存在偏見的,首先要了解模型的偏見程度。常見的方法是確定輸入值(與特征相關(guān))在模型預測/輸出上的相對重要性。確定輸入值的相對重要性將有助于使模型不過度依賴于討論部分的受保護屬性(年齡、性別、顏色、教育等)。其他技術(shù)包括審計數(shù)據(jù)分析、ML建模流水線等。
為了確定模型偏差和相關(guān)的公平性,可以使用以下框架:
Lime FairML SHAP Google What-If IBM Bias Assessment Toolkit
偏差的特征和屬性
以下是導致偏差的常見屬性和特征
種族 性別 顏色 宗教 國籍 婚姻狀況 性取向 教育背景 收入來源 年齡
考慮到上述特性相關(guān)的數(shù)據(jù)可能導致的偏差,我們希望采用適當?shù)牟呗詠碛柧毢蜏y試模型和相關(guān)性能。
AI偏見在行業(yè)中的示例
銀行業(yè)務:由于系統(tǒng)中引入的模型,其訓練數(shù)據(jù)(如性別、教育、種族、地點等)存在偏見,導致一個有效的貸款申請人貸款請求被拒。或者一個申請人的貸款請求被批準,但其實他并不符合批準標準。
保險:因為預測模型數(shù)據(jù)集涵蓋的特征不齊全,導致一個人被要求支付高額的保險費。
就業(yè):一個存在偏見的機器學習模型,根據(jù)候選人的種族、膚色等屬性錯誤的篩選候選人的簡歷,導致有資質(zhì)的候選人被篩選掉,致使公司錯失聘用優(yōu)秀候選人的機會。
住房:在住房領(lǐng)域,可能會因為位置、社區(qū)、地理等相關(guān)數(shù)據(jù),在引入過程中出現(xiàn)偏差,導致模型具有高偏見,對房價做出了錯誤的預測,最后致使業(yè)主和客戶(買方)失去交易機會。
欺詐(刑事/恐怖分子):由于訓練模型對種族、宗教、國籍等特征存在偏見,將一個沒有犯過罪行的人歸類為潛在罪犯且進行審問。例如,在某些國家或地區(qū),某一宗教人士被懷疑成恐怖組織。目前,這變成了個人偏見的一部分,而這種偏見在模型中反應了出來。
政府:假設政府給某一特定人群設定政策,機器學習負責對這些計劃中的收益人群進行分類。模型偏見可能會導致本應該享受相關(guān)政策的人群沒有享受到政策,而沒有資格享受相關(guān)政策的人卻成為政策受益人。
教育:假設一位學生的入學申請因為基礎的機器學習模型偏見被拒絕,而原因是因為使用模型訓練的數(shù)據(jù)集不全。
金融:在金融行業(yè)中,使用有偏差的數(shù)據(jù)建立的模型會導致誤批申請者的貸款請求,而違反《平等信貸機會法》。而且,誤批之后,用戶會對最終結(jié)果提出質(zhì)疑,要求公司對未批準原因進行解釋。
1974年,法律規(guī)定,禁止金融信用因為種族、膚色、宗教、性別等屬性歧視任何人和組織。在模型構(gòu)建的過程中,產(chǎn)品經(jīng)理(業(yè)務分析師)和數(shù)據(jù)科學家需要盡可能考慮所有可能情況,確保構(gòu)建模型(訓練或測試)的數(shù)據(jù)的通用和準確,無意中的一絲細節(jié)就可能導致偏見。
總結(jié)
通過閱讀本文,您了解了機器學習模型偏差、偏差相關(guān)的屬性和特征以及模型偏差在不同行業(yè)中的示例。導致偏差的原因可能是因為產(chǎn)品經(jīng)理或數(shù)據(jù)科學家在研究機器學習問題時,對數(shù)據(jù)特征、屬性以及用于模型訓練的數(shù)據(jù)集概括不全面,導致機器學習模型無法捕獲重要特征并覆蓋所有類型的數(shù)據(jù)來訓練模型。具有高偏見的機器學習模型可能導致利益相關(guān)者采取不公平/有偏見的決策,會嚴重影響整個交易過程甚至是最終客戶的利益。