清華和字節(jié)跳動(dòng)提出神經(jīng)網(wǎng)絡(luò)配音器,有望讓影視后期效率倍增
影視配音是一項(xiàng)技術(shù)含量很高的專業(yè)技能。專業(yè)配音演員的聲音演繹往往讓人印象深刻。現(xiàn)在,AI 也有望自動(dòng)實(shí)現(xiàn)這種能力。
近期,清華大學(xué)和字節(jié)跳動(dòng)智能創(chuàng)作語音團(tuán)隊(duì)業(yè)內(nèi)首次提出了神經(jīng)網(wǎng)絡(luò)配音器(Neural Dubber)。這項(xiàng)研究能讓 AI 根據(jù)配音腳本,自動(dòng)生成與畫面節(jié)奏同步的高質(zhì)量配音。相關(guān)論文 Neural Dubber: Dubbing for Videos According to Scripts 已入選機(jī)器學(xué)習(xí)和計(jì)算神經(jīng)科學(xué)領(lǐng)域頂級(jí)學(xué)術(shù)會(huì)議 NeurIPS 2021。

- 論文地址:https://arxiv.org/abs/2110.08243
- 項(xiàng)目主頁:https://tsinghua-mars-lab.github.io/NeuralDubber/
配音(Dubbing)廣泛用于電影和視頻的后期制作,具體指的是在安靜的環(huán)境(即錄音室)中重新錄制演員對(duì)話的后期制作過程。配音常見于兩大應(yīng)用場(chǎng)景:第一個(gè)是替換拍攝時(shí)錄制的對(duì)話,如拍攝場(chǎng)景下錄制的語音音質(zhì)不佳,又或者出于某種原因演員只是對(duì)了口型,聲音需要事后配上;第二個(gè)是對(duì)譯制片配音,例如,為了便于中國(guó)觀眾欣賞,將其他語言的視頻翻譯并配音為中文。
清華大學(xué)和字節(jié)跳動(dòng)智能創(chuàng)作語音團(tuán)隊(duì)的這項(xiàng)研究主要關(guān)注第一個(gè)應(yīng)用場(chǎng)景,即 “自動(dòng)對(duì)話替換(ADR)”。在這一場(chǎng)景下,專業(yè)的配音演員觀看預(yù)先錄制的視頻中的表演,并用適當(dāng)?shù)捻嵚桑ɡ缰匾簟⒄Z調(diào)和節(jié)奏)重新錄制每一句臺(tái)詞,使他們的講話與預(yù)先錄制的視頻同步。
為了實(shí)現(xiàn)上述目標(biāo),該團(tuán)隊(duì)定義了一個(gè)新的任務(wù),自動(dòng)視頻配音(Automatic Video Dubbing, AVD), 從給定文本和給定視頻中合成與該視頻時(shí)序上同步的語音。
此前,行業(yè)內(nèi)的很多研究是,根據(jù)給定語音生成與之同步的說話人的面部視頻(Talking Face Generation)。而 AVD 任務(wù)正好相反,是用于生成與視頻同步的語音,更加適用于真實(shí)的應(yīng)用場(chǎng)景,因?yàn)橛耙曌髌放臄z的視頻往往質(zhì)量很高,并不希望再對(duì)其進(jìn)行修改。
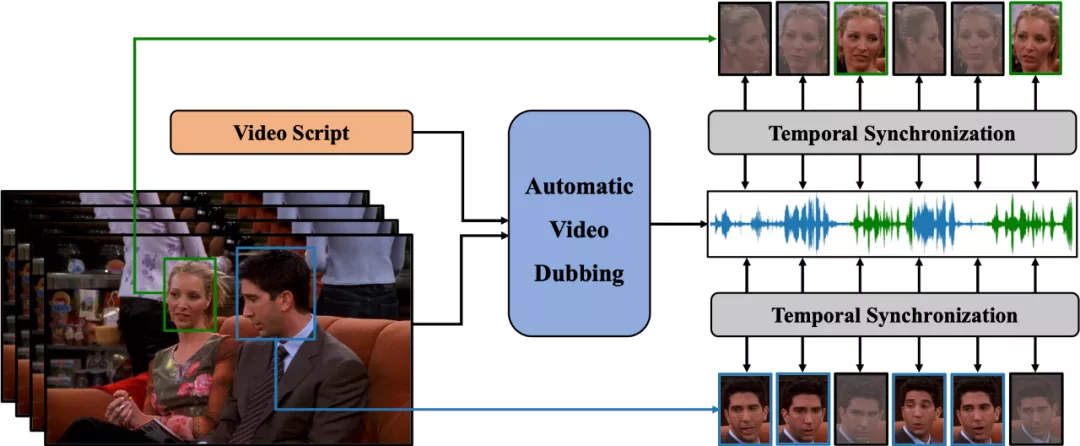
圖 1:自動(dòng)視頻配音(AVD)任務(wù)示意圖。給定文本和視頻作為輸入,AVD 任務(wù)旨在合成與視頻在時(shí)間上同步的語音。這是兩個(gè)人互相交談的場(chǎng)景。面部圖片是灰色的,表示當(dāng)時(shí)這個(gè)人沒有說話。
清華大學(xué)和字節(jié)跳動(dòng)智能創(chuàng)作語音團(tuán)隊(duì)提出的神經(jīng)網(wǎng)絡(luò)配音器(Neural Dubber)旨在解決自動(dòng)視頻配音(AVD)任務(wù)。這是第一個(gè)解決 AVD 任務(wù)的神經(jīng)網(wǎng)絡(luò)模型:能夠從文本中端到端地并行合成與給定視頻同步的高質(zhì)量語音。神經(jīng)網(wǎng)絡(luò)配音器是一種多模態(tài)文本到語音 (TTS) 模型,它利用視頻中的嘴部運(yùn)動(dòng)來控制生成語音的韻律,以達(dá)到語音和視頻同步的目的。此外,該工作還針對(duì)多說話人場(chǎng)景開發(fā)了基于圖像的說話人嵌入 (ISE) 模塊,該模塊使神經(jīng)網(wǎng)絡(luò)配音器能夠根據(jù)說話人的面部生成具有合理音色的語音。
具體的技術(shù)方法如下:
神經(jīng)網(wǎng)絡(luò)配音器(Neural Dubber)將 AVD 任務(wù)具體建模成如下形式:給定音素序列和視頻幀序列,模型需要預(yù)測(cè)與視頻同步的梅爾頻譜序列。
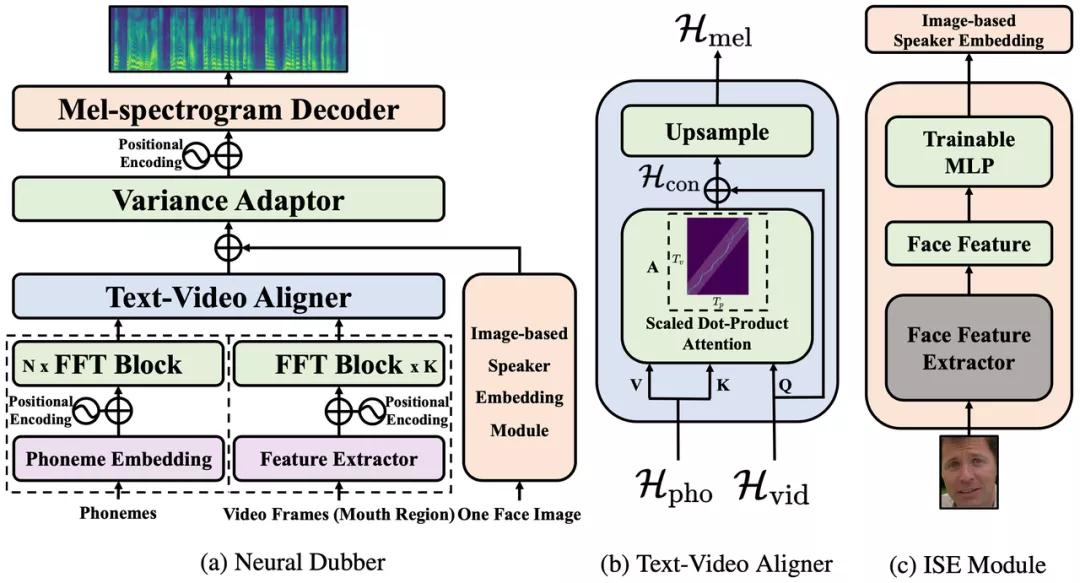
圖 2:神經(jīng)網(wǎng)絡(luò)配音器(Neural Dubber)的模型結(jié)構(gòu)。
神經(jīng)網(wǎng)絡(luò)配音器(Neural Dubber)的整體模型結(jié)構(gòu)如圖 2 所示。首先,神經(jīng)網(wǎng)絡(luò)配音器應(yīng)用音素編碼器和視頻編碼器分別處理音素序列和視頻幀序列。編碼后,音素序列變成音素隱表示序列,視頻幀序列變成視頻隱表示序列。然后,音素隱表示序列和視頻隱表示序列被輸入到文本視頻對(duì)齊器(Text-Video Aligner),得到經(jīng)過擴(kuò)展后的梅爾頻譜隱表示序列,它與目標(biāo)梅爾頻譜序列的長(zhǎng)度相同。該工作在文本視頻對(duì)齊器中解決了音素和梅爾頻譜序列長(zhǎng)度不一致的問題。在多說話人場(chǎng)景時(shí),模型會(huì)從視頻幀序列中隨機(jī)選擇的一張人臉圖像,輸入到基于圖像的說話人嵌入(Image-based Speaker Embedding, ISE)模塊以生成基于圖像的說話人嵌入。梅爾頻譜隱表示序列會(huì)與 ISE 相加,并輸入到可變信息適配器(Variance Adaptor)中以添加一些方差信息(例如,音高、音量(頻譜能量))。最后,梅爾頻譜解碼器(Mel-spectrogram Decoder)將隱表示序列轉(zhuǎn)換為梅爾頻譜序列。
文本視頻對(duì)齊器(Text-Video Aligner)
文本視頻對(duì)齊器(圖 2(b))可以找到文本和嘴部運(yùn)動(dòng)之間的對(duì)應(yīng)關(guān)系,利用這種對(duì)應(yīng)關(guān)系可以進(jìn)一步生成與視頻同步的語音。
在文本視頻對(duì)齊器中,注意力模塊學(xué)習(xí)音素序列和視頻幀序列之間的對(duì)齊方式,并生成文本視頻上下文特征序列。然后執(zhí)行上采樣操作以將此序列從與視頻幀序列一樣長(zhǎng)擴(kuò)展到與目標(biāo)梅爾頻譜序列一樣長(zhǎng)。
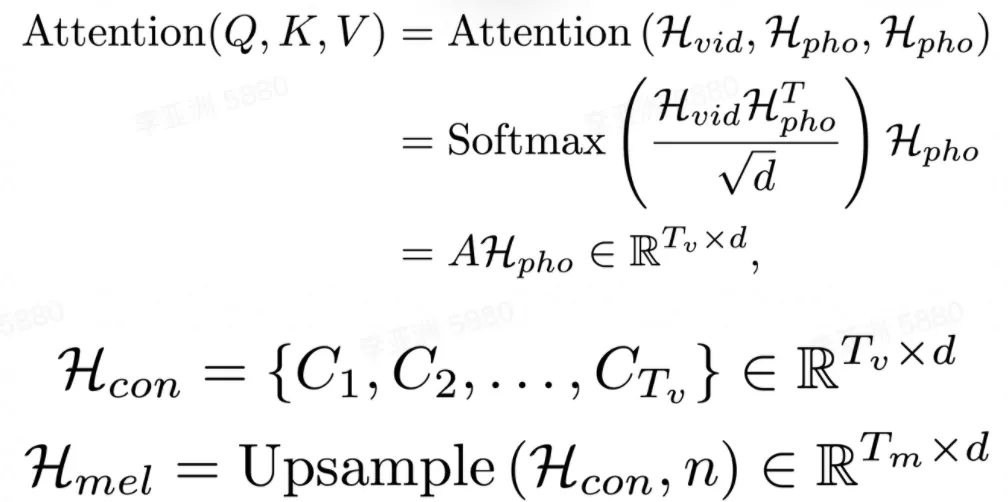
注意力模塊中,視頻隱表示序列用作查詢。因此,注意力權(quán)重由視頻顯式地控制,并實(shí)現(xiàn)了視頻幀和音素之間的時(shí)序?qū)R。獲得的視頻幀和音素之間的單調(diào)對(duì)齊有助于合成出的語音在細(xì)粒度(音素)級(jí)別上和視頻同步。
之后,將文本視頻上下文特征序列擴(kuò)展到與目標(biāo)梅爾頻譜序列一樣的長(zhǎng)度。這樣音素和梅爾頻譜序列之間的長(zhǎng)度不匹配問題,就在沒有音素和梅爾頻譜細(xì)粒度對(duì)齊監(jiān)督的情況下得到解決。由于視頻幀和音素之間的注意力機(jī)制,合成語音的速度和韻律由輸入視頻顯式地控制,使得能夠合成與視頻同步的語音。
基于圖像的說話人嵌入(Image-based Speaker Embedding)
在真實(shí)的配音場(chǎng)景中,配音演員需要為不同的表演者改變音色。為了更好地模擬 AVD 任務(wù)的真實(shí)情況,該研究提出了基于圖像的說話人嵌入模塊(圖 2(c)),目標(biāo)是在多說話人的場(chǎng)景中利用說話人的面部特征對(duì)合成語音進(jìn)行不同音色的調(diào)節(jié)。就像人們可以從他人的外表(性別、年齡等)大致推斷出對(duì)方說話的音色。
基于圖像的說話人嵌入是一種新型的多模態(tài)說話人嵌入,能夠從人臉圖片生成說話人嵌入,該嵌入蘊(yùn)含了圖像中所能體現(xiàn)的說話人的聲音特征。ISE 模塊利用視頻中人臉和語音的天然對(duì)應(yīng)關(guān)系,采用自監(jiān)督的方式進(jìn)行訓(xùn)練,不需要說話人身份的監(jiān)督。ISE 模塊學(xué)習(xí)到人臉和聲音特征的相關(guān)性,讓神經(jīng)網(wǎng)絡(luò)配音器(Neural Dubber)能夠產(chǎn)生具有合理音色的語音。合理指的是聲音特征與從說話人面部推斷出的各種屬性(例如,性別和年齡等)相符。
實(shí)驗(yàn)和結(jié)果
在單說話人數(shù)據(jù)集 Chemistry Lectures 和多說話人數(shù)據(jù)集 LRS2 上的實(shí)驗(yàn)表明,神經(jīng)網(wǎng)絡(luò)配音器(Neural Dubber)可以生成與 SOTA 的 TTS 模型在音質(zhì)方面相當(dāng)?shù)恼Z音。最重要的是,定性和定量評(píng)估都表明,神經(jīng)網(wǎng)絡(luò)配音器可以通過視頻控制合成語音的韻律,并生成與視頻同步的高質(zhì)量語音。
評(píng)價(jià)指標(biāo)
由于 AVD 任務(wù)旨在給定文本和視頻合成與該視頻同步的語音,因此語音質(zhì)量和音視頻同步度是重要的評(píng)估標(biāo)準(zhǔn)。定性評(píng)價(jià)上,該研究在測(cè)試集進(jìn)行平均意見分?jǐn)?shù)(MOS)評(píng)估,以衡量語音質(zhì)量和音視頻同步度。定量評(píng)價(jià)上,該研究采用兩個(gè)指標(biāo):Lip Sync Error - Distance (LSE-D) 和 Lip Sync Error - Confidence (LSE-C)。
單說話人場(chǎng)景
研究者首先在單說話人數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn),將 Neural Dubber 與以下幾個(gè)系統(tǒng)進(jìn)行比較,包括 1) GT,真實(shí)音視頻數(shù)據(jù);2) GT (Mel + PWG),先將真實(shí)音頻轉(zhuǎn)換為梅爾頻譜圖,然后使用 Parallel WaveGAN (PWG) 將其轉(zhuǎn)換回音頻;3) FastSpeech 2 (Mel + PWG);4) Video-based Tacotron (Mel + PWG)。為了進(jìn)行公平比較,2)、3)、4) 和 Neural Dubber 中的使用相同預(yù)訓(xùn)練的 Parallel WaveGAN。
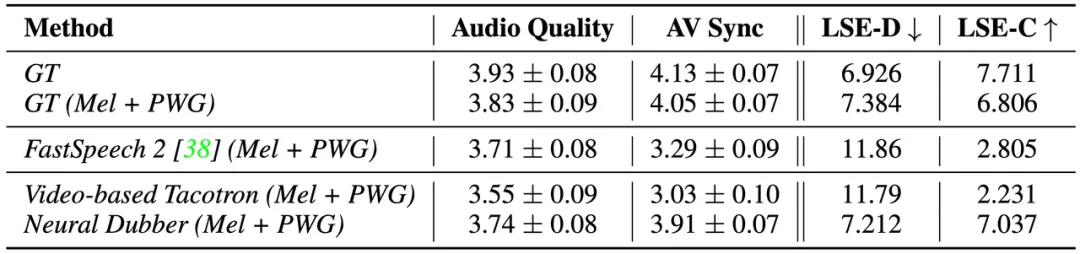
表 1:?jiǎn)握f話人場(chǎng)景下自動(dòng)視頻配音的測(cè)評(píng)結(jié)果。
從結(jié)果(如表 1 所示)可以看出,Neural Dubber 在音頻質(zhì)量上與 FastSpeech 2 不相上下,這表明 Neural Dubber 可以合成高質(zhì)量的語音。此外,在音視頻同步度方面,Neural Dubber 明顯優(yōu)于 FastSpeech 2 和 Video-based Tacotron,而且與 GT (Mel + PWG) 系統(tǒng)相媲美,這表明 Neural Dubber 可以用視頻控制語音的韻律并生成與視頻同步的語音。然而, FastSpeech 2 和 Video-based Tacotron 都無法生成與視頻同步的語音。
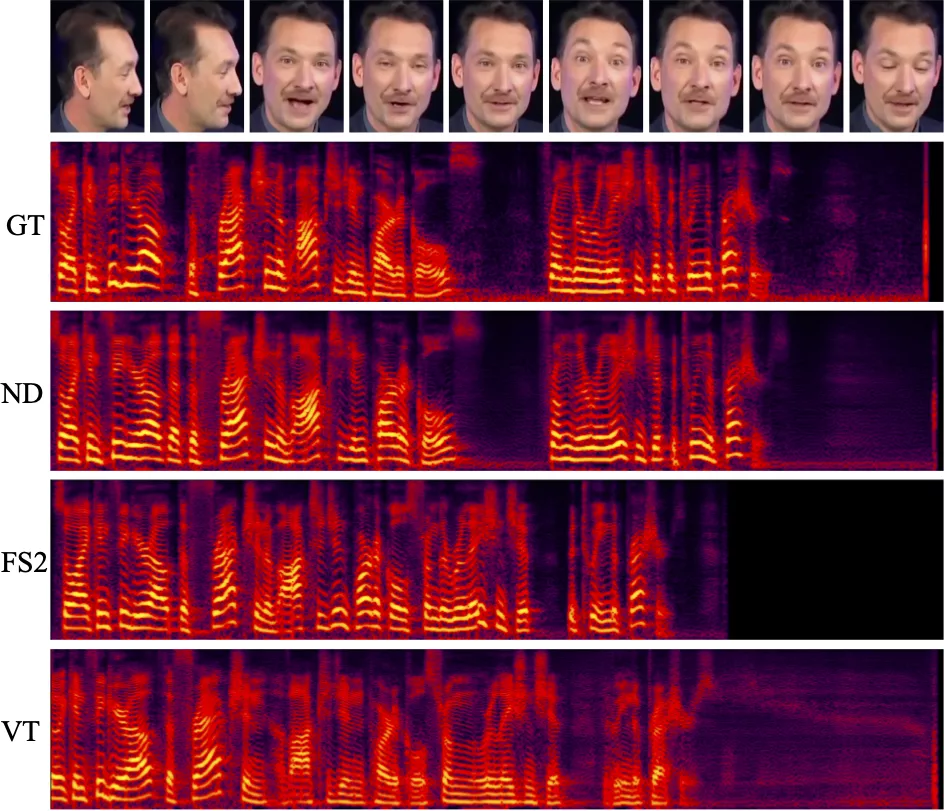
圖 3: 由以下系統(tǒng)合成的音頻的梅爾頻譜圖:Ground Truth (GT)、Neural Dubber (ND)、FastSpeech 2 (FS2) 和 Video-based Tacotron (VT)。
圖 3 展示了一個(gè)定性比較,其中包含由上述系統(tǒng)生成的音頻的梅爾頻譜圖。結(jié)果表明 Neural Dubber 生成的音頻的韻律十分接近于真實(shí)音頻的韻律,即與視頻同步度很高。
多說話人場(chǎng)景
該研究還在多說話人數(shù)據(jù)集 LRS2 上進(jìn)行了相同的定性和定量評(píng)估。
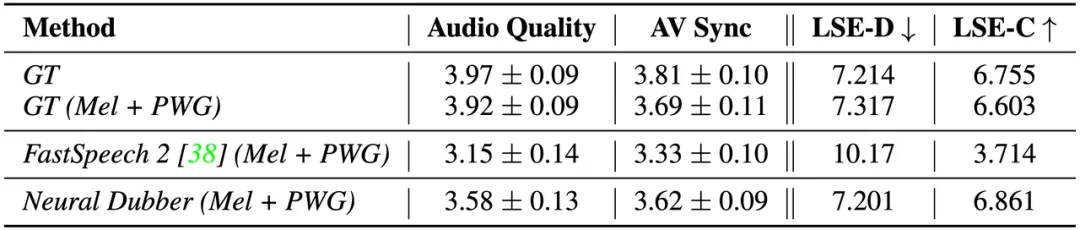
表 2: 多說話人場(chǎng)景下自動(dòng)視頻配音的測(cè)評(píng)結(jié)果。
從結(jié)果(如表 2 所示)可以看出, Neural Dubber 在音頻質(zhì)量方面明顯優(yōu)于 FastSpeech 2,展示了 ISE 在多說話人場(chǎng)景中的有效性。定性和定量評(píng)估表明,在音視頻同步度方面,Neural Dubber 比 FastSpeech 2 好得多,并且與 GT (Mel + PWG) 系統(tǒng)相當(dāng)。這些結(jié)果表明,Neural Dubber 可以解決比單說話人場(chǎng)景更具挑戰(zhàn)性的多說話人場(chǎng)景下的自動(dòng)視頻配音(AVD)問題。
為了展示 ISE 使得 Neural Dubber 能夠通過人臉圖像控制生成語音的音色。該研究用 Neural Dubber 生成了一些由不同說話者人臉圖像作為輸入的音頻片段。研究者從 LRS2 數(shù)據(jù)集的測(cè)試集中隨機(jī)選擇 12 名男性和 12 名女性進(jìn)行評(píng)估,每個(gè)人選擇了 10 張具有不同頭部姿勢(shì)、光照和化妝的人臉圖像。

圖 4: 說話人嵌入的可視化。
從圖 4 可以看出,由同一說話人的圖像生成的語音形成一個(gè)緊密的簇,不同說話人的簇彼此分離。此外,由不同性別的人臉圖像合成的語音之間存在明顯差異。
與基于嘴部運(yùn)動(dòng)的語音生成方法的對(duì)比
與基于嘴部運(yùn)動(dòng)的語音生成(Lip-motion Based Speech Generation )模型 Lip2Wav 對(duì)比,Neural Dubber 在自動(dòng)視頻配音任務(wù)下的優(yōu)越性十分顯著。
研究者使用 STOI 和 ESTOI 來評(píng)估語音可懂度,使用 PESQ 來評(píng)估語音質(zhì)量,使用單詞錯(cuò)誤率 (WER) 評(píng)估語音發(fā)音準(zhǔn)確度。
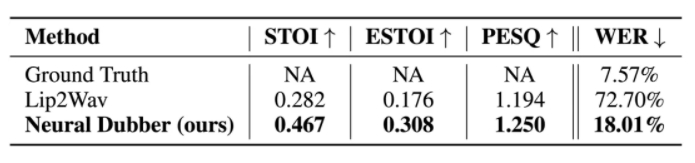
表 3: Lip2Wav 和 Neural Dubber 在單說話人場(chǎng)景下的比較。
如表 3 的結(jié)果所示,Neural Dubber 在語音質(zhì)量和可懂度方面均超過 Lip2Wav。最重要的是,Neural Dubber 的 WER 比 Lip2Wav 低 4 倍左右。這表明 Neural Dubber 在發(fā)音準(zhǔn)確度上明顯優(yōu)于 Lip2Wav。Lip2Wav 的 WER 高達(dá) 72.70%,說明它誤讀了很多內(nèi)容,這在 AVD 任務(wù)中是不可接受的。總而言之,Neural Dubber 在語音可懂度、音質(zhì)和發(fā)音準(zhǔn)確度方面明顯優(yōu)于 Lip2Wav,更適合自動(dòng)視頻配音任務(wù)。
清華大學(xué) MARS Lab 多模態(tài)學(xué)習(xí)實(shí)驗(yàn)室簡(jiǎn)介:MARS Lab 多模態(tài)學(xué)習(xí)實(shí)驗(yàn)室,是清華大學(xué)交叉信息院下的交叉學(xué)科人工智能實(shí)驗(yàn)室,由趙行教授組建和指導(dǎo)。團(tuán)隊(duì)特別感興趣如何讓機(jī)器像人一樣的能夠通過多種感知輸入進(jìn)行學(xué)習(xí)、推理和交互。團(tuán)隊(duì)的研究涵蓋了多模態(tài)學(xué)習(xí)的基礎(chǔ)問題及其應(yīng)用。
字節(jié)跳動(dòng)智能創(chuàng)作語音團(tuán)隊(duì)簡(jiǎn)介:字節(jié)跳動(dòng)智能創(chuàng)作 - 語音團(tuán)隊(duì) (Speech, Audio and Music Intelligence, SAMI) 致力于語音、音頻、音樂等技術(shù)的研發(fā)和產(chǎn)品創(chuàng)新,使命是通過多模態(tài)音頻技術(shù)賦能內(nèi)容創(chuàng)作和互動(dòng),讓內(nèi)容消費(fèi)和創(chuàng)作變得更簡(jiǎn)單和愉悅。 團(tuán)隊(duì)支持包括語音合成、音頻處理和理解、音樂理解和生成等技術(shù)方向,并以中臺(tái)形式服務(wù)于公司眾多業(yè)務(wù)線以及向外部企業(yè)開放成熟的能力和服務(wù)。
項(xiàng)目主頁:https://tsinghua-mars-lab.github.io/NeuralDubber/