













中科院自動化所登Science子刊:自組織反向傳播提升網絡學習效率
在人工智能領域,目前人工神經網絡中被廣泛使用的反向傳播算法(Backpropagation,BP)采用全局優化策略,這種端到端的學習方法性能卓越,但學習過程能量消耗大,且缺乏靈活性。中科院腦智卓越中心徐波、蒲慕明聯合研究團隊近期借助生物網絡中發現的介觀尺度自組織反向傳播機制(Self-backpropagation,SBP),在更具效率和靈活性的類腦局部學習方法方面取得了重要進展。
該研究的論文《Self-backpropagation of synaptic modifications elevates the efficiency of spiking and artificial neural networks》已于 2021 年 10 月 20 日(美東時間)在線發表于《科學》子刊《Science Advances》上。

論文地址:https://www.science.org/doi/10.1126/sciadv.abh0146
借助 SBP 降低計算能耗
SBP 的發現最早可以追溯到 1997 年。蒲慕明團隊在 Nature 雜志上撰文發現海馬體內的神經元可以將長時程抑制(Long-term depression,LTD)可塑性自組織地傳播到三個方向,分別是突觸前側向傳播(Presynaptic lateral spread)、突觸后側向傳播(Postsynaptic lateral spread)、反向傳播(Backpropagation)[1],這個發現就是自組織反向傳播神經可塑性機制(SBP)。
后續研究證實,SBP 現象具有普遍性,不僅覆蓋更多的神經區域如視網膜 - 頂蓋系統 [2],還覆蓋更多的可塑性類型 [3],如長時程增強(Long-term potentiation,LTP)。該機制的發生歸結于生物神經元內分子調制信號的天然逆向傳遞,被認為是可能導致生物神經網絡高效反饋學習的關鍵 [4]。
中科院研究團隊受到該機制的啟發,對 SBP 的反向傳播方向(第三個方向)單獨構建數學模型(圖 1A),重點描述了神經元輸出突觸的可塑性可以反向傳播到輸入突觸中(圖 1B),可塑性的發生可以通過時序依賴突觸可塑性(Spike timing-dependent plasticity,STDP),也可以通過人工局部梯度調節。在標準三層脈沖神經網絡(Spiking neural network,SNN)的學習過程中,SBP 機制可以自組織地完成前一層網絡權重的學習,且可以結合短時突觸可塑性(Short-term plasticity,STP)、膜電位平衡(Homeo-static membrane potential)等,形成更強大的 SNN 組合學習方法(圖 1C)。
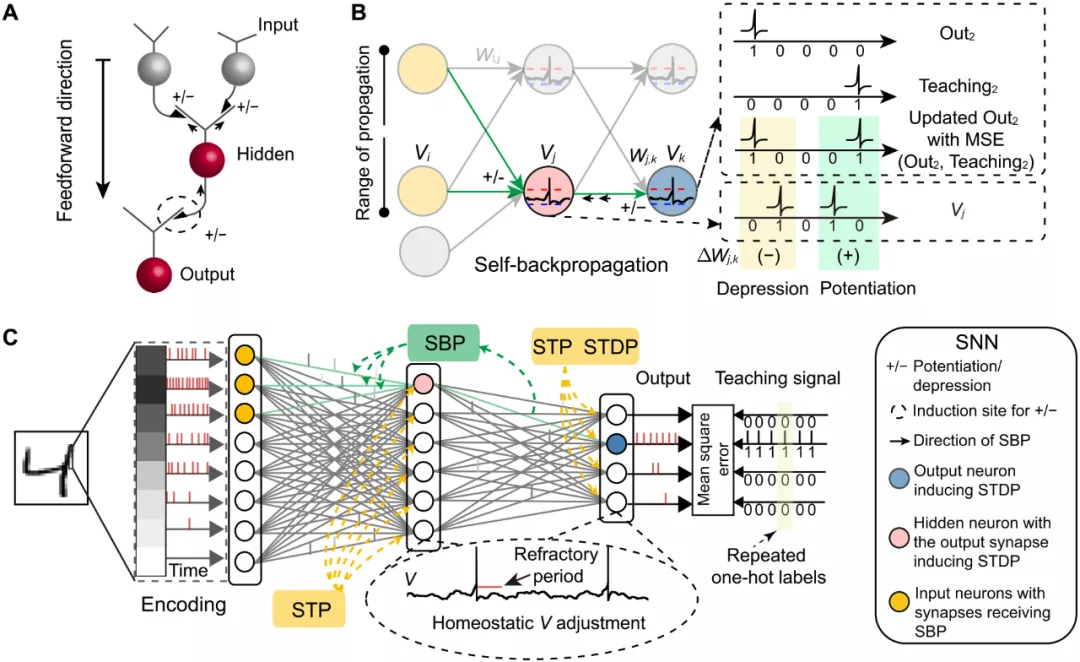
圖 1:SBP 在 SNN 中的應用。(A),SBP 可塑性機制。(B),SBP 在 SNN 中的局部反向傳播。(C),SBP 和其它可塑性機制在 SNN 中的組合優化。
在一類人工神經網絡(Artificial neural network,ANN)如受限玻爾茲曼機網絡(Restricted Boltzmann machine,RBM)的學習中(圖 2A),SBP 機制也可以替換迭代過程中部分 BP 機制,實現交替的協作優化(圖 2B-E)。針對 SNN 和 RBM 的不同,團隊又分別設置了兩種不同的能量函數約束,來保證訓練過程中網絡參數學習的平穩性。
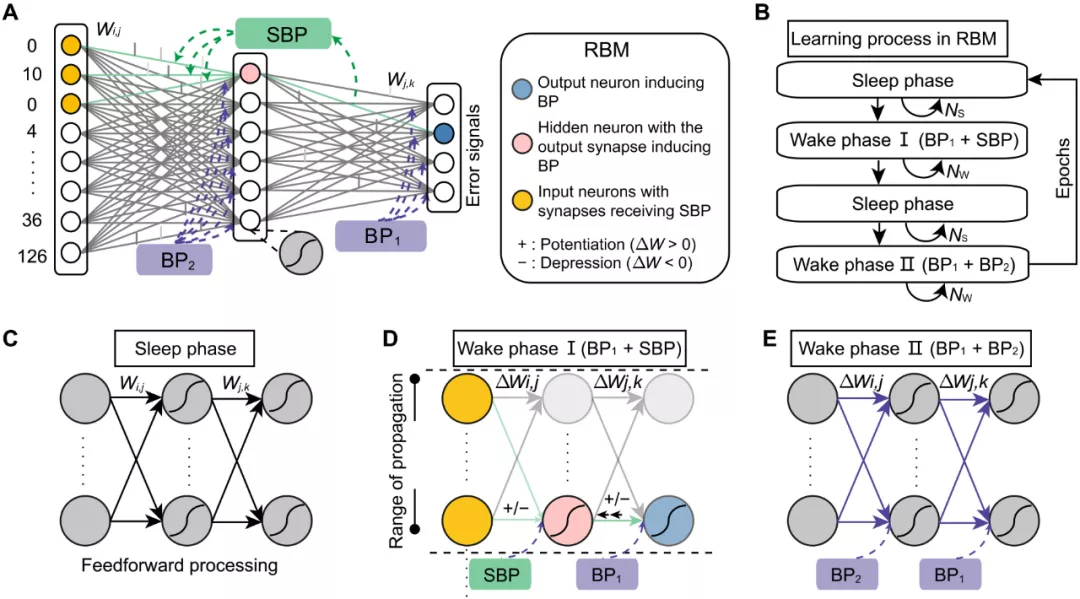
圖 2:SBP 在 RBM 中的應用。(A),SBP 和 BP 在 RBM 中的組合優化。(B),SBP 和 BP 的交替協作流程。(C),RBM 中的標準 Sleep Phase。(D),含有 SBP 的 Wake Phase。(E),含有 BP 的 Wake Phase。
此外,研究團隊針對性地提出了一種統計訓練過程中能量消耗的新方法(圖 3)。在圖片分類(MNIST)、語音識別(NETtalk)、動態手勢識別(DvsGesture)等多類標準數據集上,SBP 機制通過組合其它可塑性機制,實現了更低能耗和更高精度的 SNN 局部學習(圖 4)。在 ANN-RBM 的學習中,SBP 機制也可以大量的替換 BP 機制實現全局和局部交叉學習,在降低計算能耗同時卻不損失精度(圖 5)。如圖 5C 所示,使用 SBP 進行訓練的計算成本比僅使用 BP 進行訓練時降低了約 57.1%。
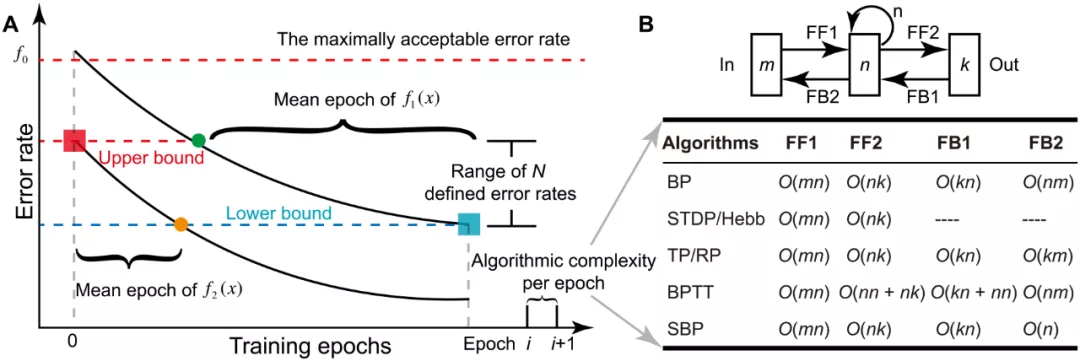
圖 3:訓練能量消耗的計算方法。(A),平均迭代次數。(B),每次迭代中的算法復雜度。
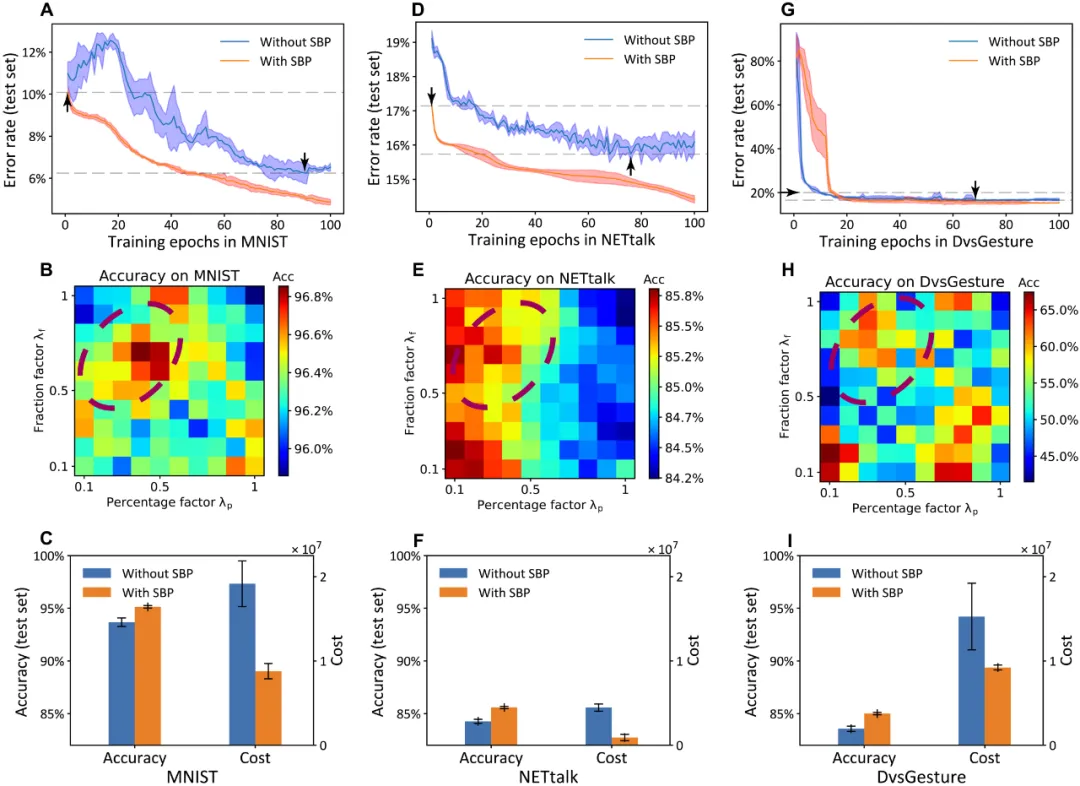
圖 4:在 MNIST、NETtalk、DvsGesture 三個數據集上的性能對比。(A,C,E),SBP 分別取得了基于梯度和基于可塑性方法的 SNN 最優性能。(B,D,F),SBP 分別取得了基于梯度和基于可塑性方法的 SNN 最低能耗。
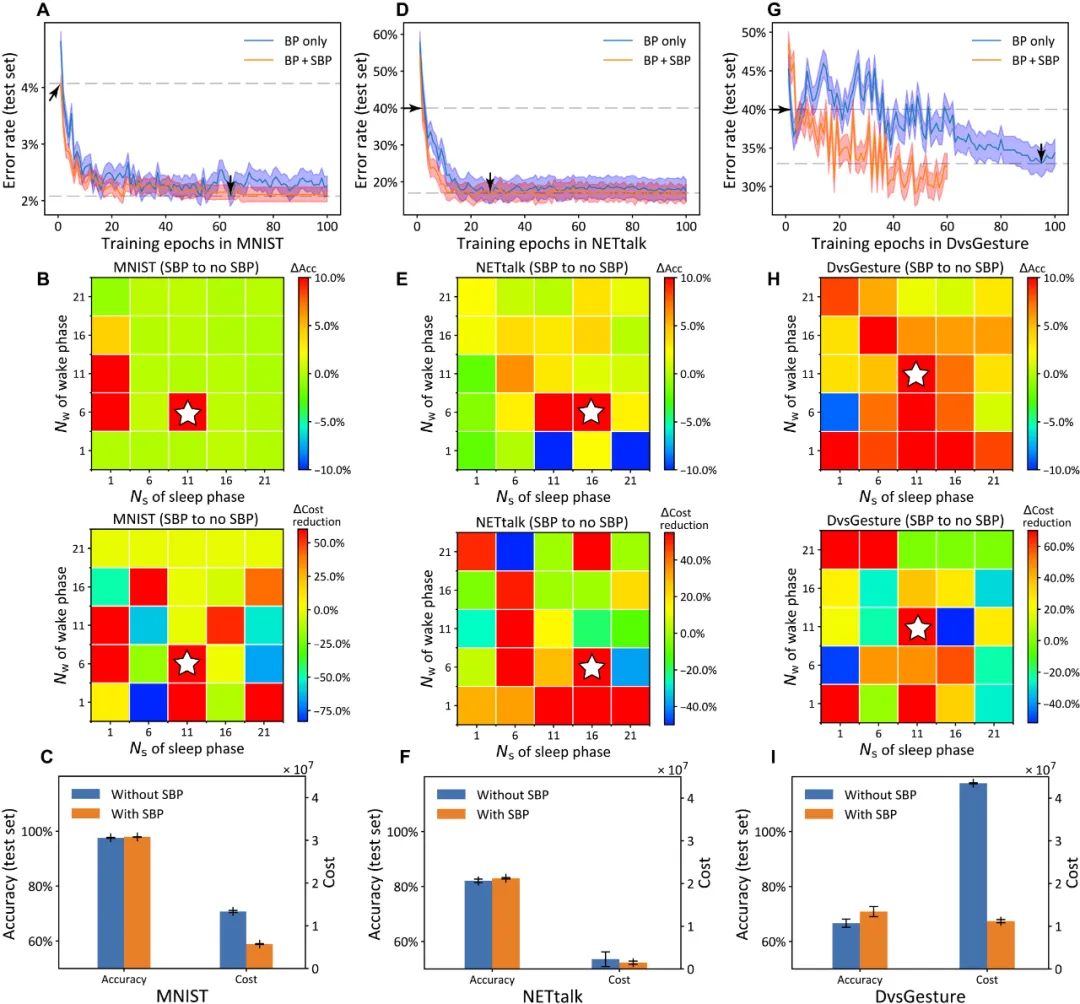
圖 5:SBP 有助于 RBM 提升精度和降低能耗。(A-C),在 MNIST 數據集中,SBP 可以少量降低 RBM 的訓練誤差(A),可以同時平衡精度和能耗得到最優的 Wake Phase 次數(B),且可以顯著降低訓練能耗(C)。(D-I),在 NETtalk 和 DvsGesture 數據集中,SBP 得到了和在 MNIST 中類似的結論。
研究人員認為,SBP 是一類介觀尺度的特殊生物可塑性機制,該機制同時在 SNN 和 ANN 中獲得了廣泛的組合優化優勢,對進一步深入探索類腦局部計算具有很大的啟示性。生物智能計算的本質,很可能就是靈活融合多類微觀、介觀等可塑性機制的自組織局部學習,結合遺傳演化賦予的遠程投射網絡結構,實現高效的全局優化學習效果。該工作可以進一步引導生物和人工網絡的深度融合,最終實現能效比高、可解釋性強、靈活度高的新一代人工智能模型。
中國科學院自動化研究所類腦智能研究中心張鐵林副研究員為該研究第一作者,徐波研究員為通訊作者,程翔(博士生)、賈順程(博士生)、蒲慕明研究員和曾毅研究員為共同作者。相關研究工作得到了國家自然科學基金委、先導 B 等項目的資助。























