













中科院自動化所聯合北方電子設備研究所提多輸入文本人臉合成方法
文本人臉合成指的是基于一個或多個文本描述,生成真實自然的人臉圖像,并盡可能保證生成的圖像符合對應文本描述,可以用于人機交互,藝術圖像生成,以及根據受害者描述生成犯罪嫌疑人畫像等。針對這個問題,中科院自動化所聯合北方電子設備研究所提出了一種基于多輸入的文本人臉合成方法(SEA-T2F),并建立了第一個手工標注的大規模人臉文本描述數據集(CelebAText-HQ)。該方法首次實現多個文本輸入的人臉合成,與單輸入的算法相比生成的圖像更加接近真實人臉。相關成果論文《Multi-caption Text-to-Face Synthesis: Dataset and Algorithm》已被ACM MM 2021錄用。

- 論文地址:https://zhaoj9014.github.io/pub/MM21.pdf
- 數據集和代碼已開源:https://github.com/cripac-sjx/SEA-T2F

圖1 不同方法的文本到人臉圖像生成結果
相較于文本到自然圖像的生成,文本到人臉生成是一個更具挑戰性的任務,一方面,人臉具有更加細密的紋理和模糊的特征,難以建立人臉圖像與自然語言的映射,另一方面,相關數據集要么是規模太小,要么直接基于屬性標簽用網絡生成,目前為止,還沒有大規模手工標注的人臉文本描述數據集,極大地限制了該領域的發展。此外,目前基于文本的人臉生成方法[1,2,3,4]都是基于一個文本輸入,但一個文本不足以描述復雜的人臉特征,更重要的是,由于文本描述的主觀性,不同人對于同一張圖片的描述可能會相互沖突,因此基于多個文本描述的人臉生成具有很重大的研究意義。
針對該問題,團隊提出了一個基于多輸入的文本人臉生成算法。算法采用三階段的生成對抗網絡框架,以隨機采樣的高斯噪聲作為輸入,來自不同文本的句子特征通過SFIM模塊嵌入到網絡當中,在網絡的第二第三階段分別引入了AMC模塊,將不同文本描述的單詞特征與中間圖像特征通過注意力機制進行融合,以生成更加細密度的特征。為了更好地在文本中學習屬性信息,團隊設計了一個屬性分類器,并引入屬性分類損失來優化網絡參數。
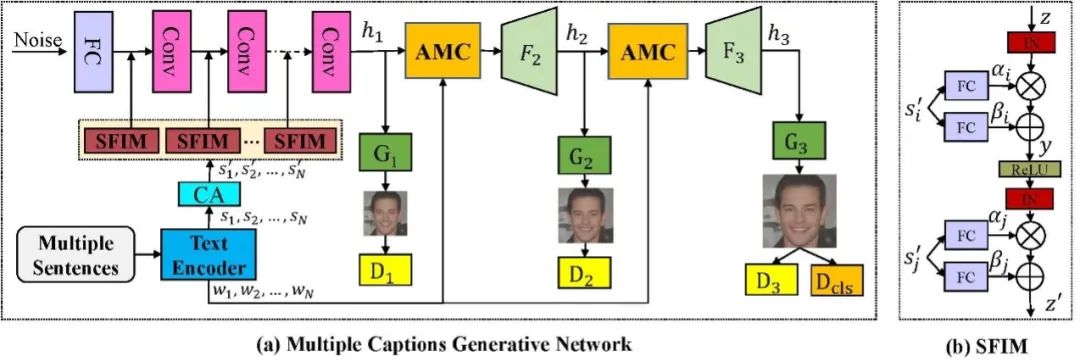
圖2 模型框架示意圖
此外,團隊首次建立了一個大規模手工標注數據集,首先在CelebAMask-HQ數據集中篩選了15010張圖片,每個圖片分別由十個工作人員手工標注十個文本描述,十個描述按照由粗到細的順序分別描述人臉的不同部位。
實驗結果
團隊對提出的方法進行了定性和定量分析[5,6],實驗結果表明,該方法不僅能生成高質量的圖像,并且更加符合文本描述。

圖3 不同方法比較結果

圖4 不同數量輸入的生成結果
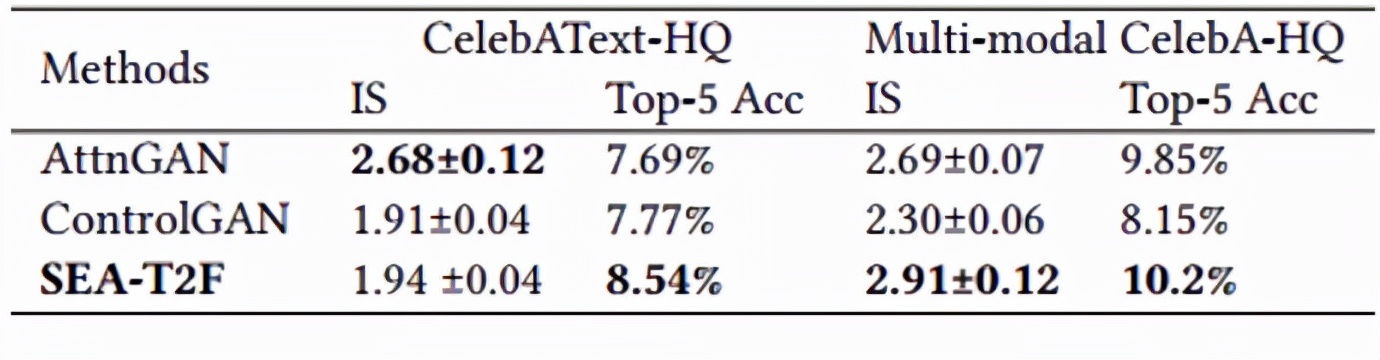
表1 不同方法的定量比較結果
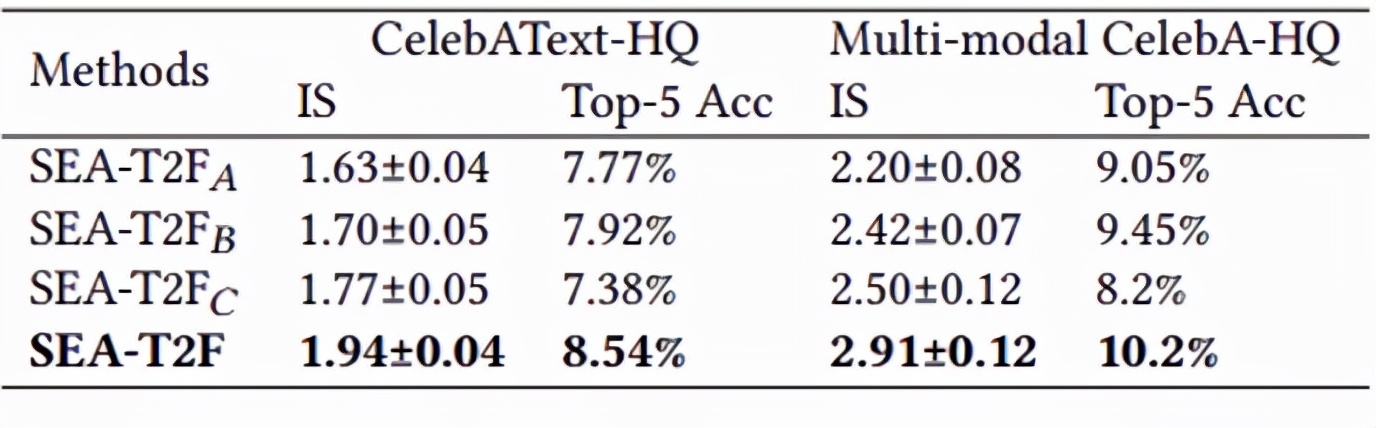
表2 消融實驗結果:前三行分別表示網絡去除SFIM,AMC,和屬性分類損失。























