ResNet假說被推翻?Reddit小哥:這么多年都沒人搞懂Ta的原理
2015年,一個里程碑的神經(jīng)網(wǎng)絡模型ResNet發(fā)布。因為在過深的網(wǎng)絡訓練會產(chǎn)生梯度消失和梯度爆炸,并且訓練過深的網(wǎng)絡中會出現(xiàn)準確率下降的問題,而RestNet 采用殘差連接很容易讓研究人員訓練出上百層甚至上千層的網(wǎng)絡。

在ResNet論文觀察到的退化問題(degradation problem),即34層的網(wǎng)絡在整個訓練過程中比18層的網(wǎng)絡具有更高的訓練誤差,但18層網(wǎng)絡的解空間顯然是34層網(wǎng)絡的子空間。
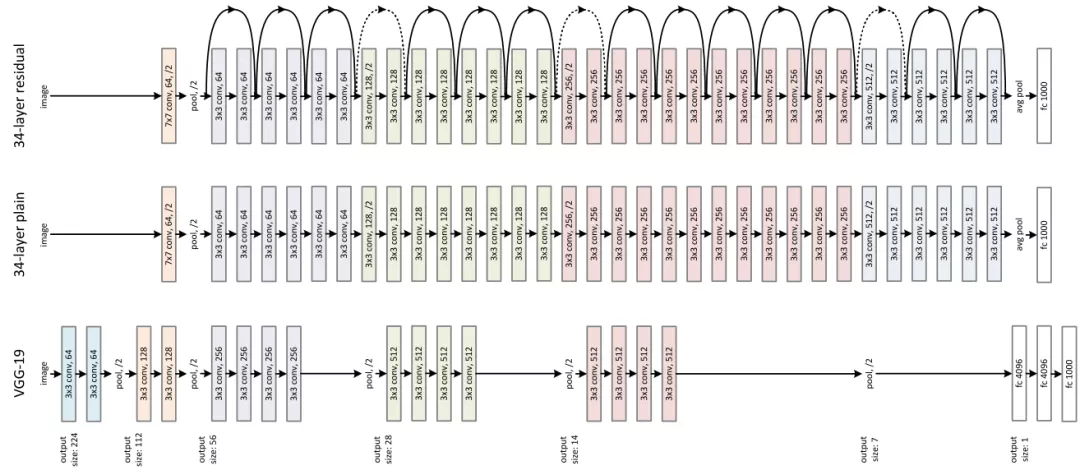
一個很自然的假設是這個問題和RNN 網(wǎng)絡中觀察到的梯度消失問題(Vanishing Gradient Problem)相同,也是長短時記憶網(wǎng)絡(Long-Short Term Memory Networks, LSTM)主要改進的問題。
但論文的作者Kaiming 大神當時并不這么認為,他在論文中寫道:

「我們認為這種優(yōu)化困難不太可能是由梯度消失引起的,因為這些普通神經(jīng)網(wǎng)絡使用 BN 進行訓練,確保前向傳播的信號具有非零方差可以緩解這個問題。我們還驗證了反向傳播的梯度,結果可以看到表現(xiàn)出 BN 的結果也很正常。因此,前向或后向的信號都不會消失。事實上,34 層的普通網(wǎng)絡仍然能夠達到有競爭力的精度,這表明這個解決方法在一定程度上是有效的。我們推測普通神經(jīng)網(wǎng)絡的收斂速度可能呈指數(shù)級低,這會影響訓練誤差的減少。未來將研究這種優(yōu)化困難的原因。」
這個論點也被網(wǎng)友稱為「ResNet 假說」,而關于ResNet 假說的正確性最近又在Reddit 上引起了熱議。

提問者認為,最近的許多論文和教程似乎都假設 ResNet 假設是錯誤的,論文的作者大多添加了跳躍連接以「改進梯度傳播流」,并引用了原始的 ResNet 論文來支持這一主張。雖然添加跳躍連接會改善梯度流是很有道理的,但首先是什么導致了退化問題依然沒有答案。
跳過連接通過改進梯度流來解決退化問題的想法似乎與 ResNet 假設明顯矛盾;那么這個想法是從哪里來的呢?ResNet 假說是否被證偽了?

有網(wǎng)友從技術角度認為并沒有完整的分析,關于 ResNets 的工作原理主要存在三種相互競爭的假說,并且給出了相關的論文:
1、進行了迭代細化(iterative refinement)

這篇論文從分析和實證兩方面研究了resnet。研究人員通過顯示殘差連接自然地鼓勵殘差塊的特征在從一個塊到下一個塊的過程中沿著損失的負梯度移動,從而在resnet中形式化了迭代細化的概念。
此外,實證分析表明,resnet能夠進行表征學習和迭代優(yōu)化。通常,Resnet塊傾向于將表示學習行為集中在前幾層,而更高層執(zhí)行特征的迭代細化。
最后,研究人員觀察到共享殘差層會導致表示爆炸和反直覺的過擬合,文中提出了一個簡單的策略可以幫助緩解這個問題。
2、指數(shù)級的集成模型

這項工作中對殘差網(wǎng)絡提出了一種新穎的解釋:這個模型可以被視為許多不同長度路徑的模型的集成。此外,殘差網(wǎng)絡似乎通過在訓練期間僅利用短路徑來實現(xiàn)非常深的網(wǎng)絡。為了支持這一觀察,研究人員將殘差網(wǎng)絡重寫為一個顯式的路徑集合。
研究結果表明,這些路徑表現(xiàn)出類似整體的行為并不強烈地相互依賴。并且大多數(shù)路徑都比人們預期的要短,在訓練期間也只需要短路徑,因為較長的路徑不會產(chǎn)生任何梯度。
例如,具有 110 層的殘差網(wǎng)絡中的大部分梯度來自僅 10-34 層深的路徑。這篇論文的結果認為Resnet 能夠訓練非常深的網(wǎng)絡的關鍵特征之一是殘差網(wǎng)絡通過引入可以在非常深的網(wǎng)絡范圍內(nèi)攜帶梯度的短路徑來避免梯度消失問題。
3、原始論文中提到的,梯度傳播過程被改進了
答主也看過一些神經(jīng)切線內(nèi)核(neural tangent kernel stuff)的東西,但他仍然不明白其中的原理,并且他也認為沒有人真正坐下來試圖弄清楚真正的解釋是什么。
不過他有一個想法,可以通過考慮具有重疊跳過連接(overlapping skip connections)的網(wǎng)絡來測試集成理論(ensemble theory),這些網(wǎng)絡具有集成論文中定義的最大多樣性(maximal multiplicity)。并且可以改變跳過連接長度的同時保持多重性不變,但還沒有人這樣做過任何與此有關的實驗。
還可以嘗試的另一件事是使 Resnets 的梯度流保證完美而無需跳過連接的情況,但是當用戶添加殘差連接時,大多數(shù)此類事情都無法達到完美的情況,因此必須考慮新的方式來達成完美梯度傳播。
另一個高贊網(wǎng)友表示,捷徑連接(shortcut connections)改善了損失情況,能夠使優(yōu)化變得更加容易,有很多研究結果都支持這一點。
The Shattered Gradients Problem: If resnets are the answer, then what is the question? (ICML 2017) 表明 ResNet 具有更穩(wěn)定的梯度。
Visualizing the Loss Landscape of Neural Nets (NeurIPS 2018) 再次表明 ResNets 具有更平滑的損失表面。
并且也有研究表示,可以不需要捷徑來學習有效的表示,但優(yōu)化會更難。例如,F(xiàn)ixup Initialization: Residual Learning without Normalization (ICLR 2019) 表明,如果你對初始化結果進行多次調(diào)整,那你可以在沒有殘差連接的情況下訓練 ResNets 以獲得不錯的結果。
RepVGG:Making VGG-style ConvNets Great Again (CVPR 2021) 表明可以在訓練后移除捷徑并仍然擁有性能不錯的網(wǎng)絡。
但這仍然符合 ResNet 的原始想法:將每個塊初始化為一個identify function,因此最初看起來好像參數(shù)實際上并不存在,也對網(wǎng)絡訓練沒有產(chǎn)生任何影響,然后逐漸讓塊的效果發(fā)揮作用。
也有網(wǎng)友認為標題的用詞實在不準確,因為debunked 相當于直接給Resnet判定為錯誤,提問者也表示自己確實是標題黨了,但標題無法更改了。