動態多尺度卷積網絡結構,清華、快手聯合提出語種識別新方法
快手研究團隊 MMU(Multimedia understanding)聯合清華大學研究人員提出了一種基于音頻信號的語種識別新方法。該方法自研一種動態多尺度卷積的新型網絡結構,通過動態卷積核、局部多尺度學習和全局多尺度池化技術來捕獲全局和局部上下文的語種 / 方言信息。目前該論文已經被國際頂級語音會議 Interspeech2021 所接收。

論文鏈接:https://www.researchgate.net/publication/353652910_Dynamic_Multi-scale_Convolution_for_Dialect_Identification
語種識別是指從一段說話語音中識別出語種(或方言)的類別,如日語、韓語、普通話、粵語等。語種識別技術的應用非常廣泛,不僅可以作為多語言語音識別(ASR)和多語言翻譯系統的前端預處理模塊,也可以用于定向廣告和生物特征驗證。近年來,隨著深度學習技術的興起,語種識別在工業界和學術界都得到廣泛的關注。幾年前,x-vector 是語種(或方言)識別的主流方法。隨著深度學習技術的快速發展,基于 DNN 的語種識別網絡結構進行了快速的迭代,從最初的 TDNN 到 D-TDNN,再到 Ecapa-TDNN 以及 ResNet 網絡結構,語種(或方言)識別性能獲得顯著提升。
為了有效捕獲音頻中的上下文語種信息,進一步提升語種識別性能,快手研究團隊 MMU(Multimedia understanding)聯合清華大學研究人員提出了一種基于音頻信號的語種識別新方法。該方法自研一種動態多尺度卷積的新型網絡結構,通過動態卷積核、局部多尺度學習和全局多尺度池化技術來捕獲全局和局部上下文的語種 / 方言信息。具體來說,引入動態卷積核的方法,模型能夠自適應地捕獲短期和長期上下文之間的特征;局部多尺度學習在細粒度級別表示多尺度特征,能夠增加卷積運算的感受野范圍,同時使模型參數量大幅下降;全局多尺度池化用于聚合來自模型不同瓶頸層的語種 / 方表征。文章的貢獻包括如下 3 點:
1. 第一次將動態卷積核引入語種 / 方言識別領域。
2. 局部多尺度學習,在更細粒度層面上對多尺度特征進行表征學習。
3. 全局多尺度池化,能夠聚合模型多個層次的特征。
針對 2020 年東方語種識別 (OLR2020) 挑戰賽的 AP20-OLR 語種識別任務,所提語種識別新方法取得了平均代價損失 (Cavg) 為 0.067,等誤差率 (EER) 為 6.52% 的成績。相比 OLR2020 挑戰賽中的最優(SOTA,state-of-the-art)識別系統,所提語種識別新方法獲得了 9% 的 Cavg 和 45% 的 EER 相對提升,而且模型參數減少了 91%,性能顯著優于 SOTA 系統。目前該論文已經被國際頂級語音會議 Interspeech2021 所接收。
方法介紹
快手 MMU 和清華自研的動態多尺度卷積的新型網絡結構框圖如圖 1 所示,為了簡化,批歸一化層 BatchNormalization (BN) 和 ReLU 激活函數已省略。從圖中可以看出,動態多尺度卷積的新型網絡結構采用 D-TDNN 網絡作為基本骨架,將第一個 D-TDNN 層修改為動態多尺度卷積塊,它在粒度級別上表示局部多尺度特征,并增加了卷積運算的感受野范圍。此外,全局多尺度池化方法聚合了不同的瓶頸層特征,以便從多個方面收集信息。
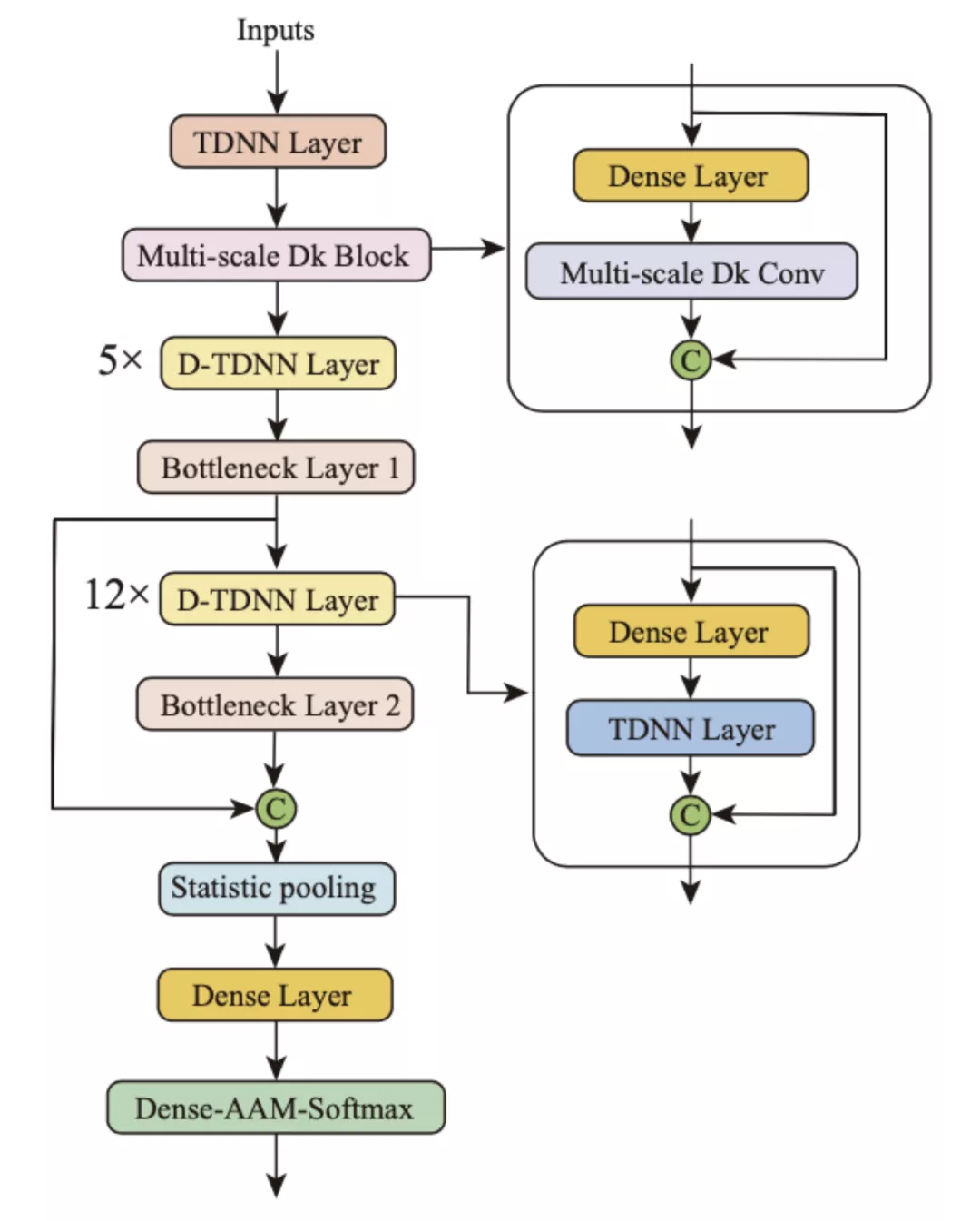
圖 1: 動態多尺度卷積結構。在圖中,"Multi-scale Dk Block" 指的是全局和局部多尺度動態卷積核模塊,"Multi-scale Dk Conv" 指的是局部多尺度動態卷積核操作。綠色的 "C" 定義了 "拼接" 操作。
1. 動態卷積核
動態卷積核(Dk Conv)是一種基于 Softmax 注意力的動態通道選擇機制,具體結構如圖 2 所示。
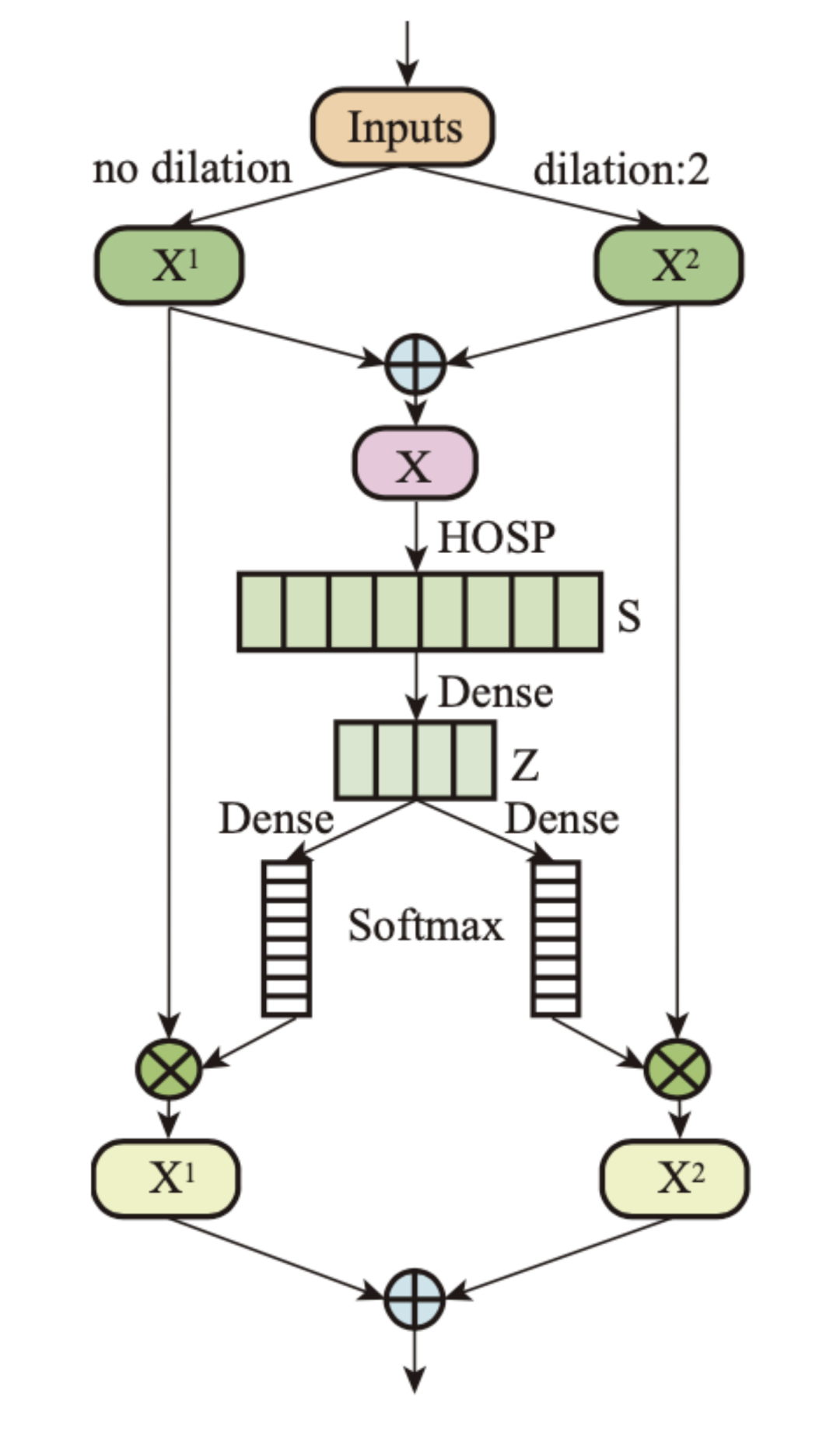
圖 2:動態卷積核 (Dk Conv) 模塊。
從圖中看出,網絡結構具體描述為:高階統計池化層(HOSP)- 線性層 - 線性層 - Softmax,其中 HOSP 目的是從空間維度收集通道信息,其它神經網絡模塊是為了評估不同分支的重要性。卷積的多分支擴展能夠使模型自適應地捕獲短期和長期上下文之間不同的方言表征。
2. 局部多尺度學習
受 Res2Net 中層內殘差連接的啟發,該團隊采用局部多尺度學習來提高卷積操作的表征能力。局部多尺度學習是指在卷積中實現更細粒度的多個可用感受野。如圖 3 所示,作者將特征平均分成 s 個特征子集,用 Xi 表示,其中 i∈[1,2,...,s]。
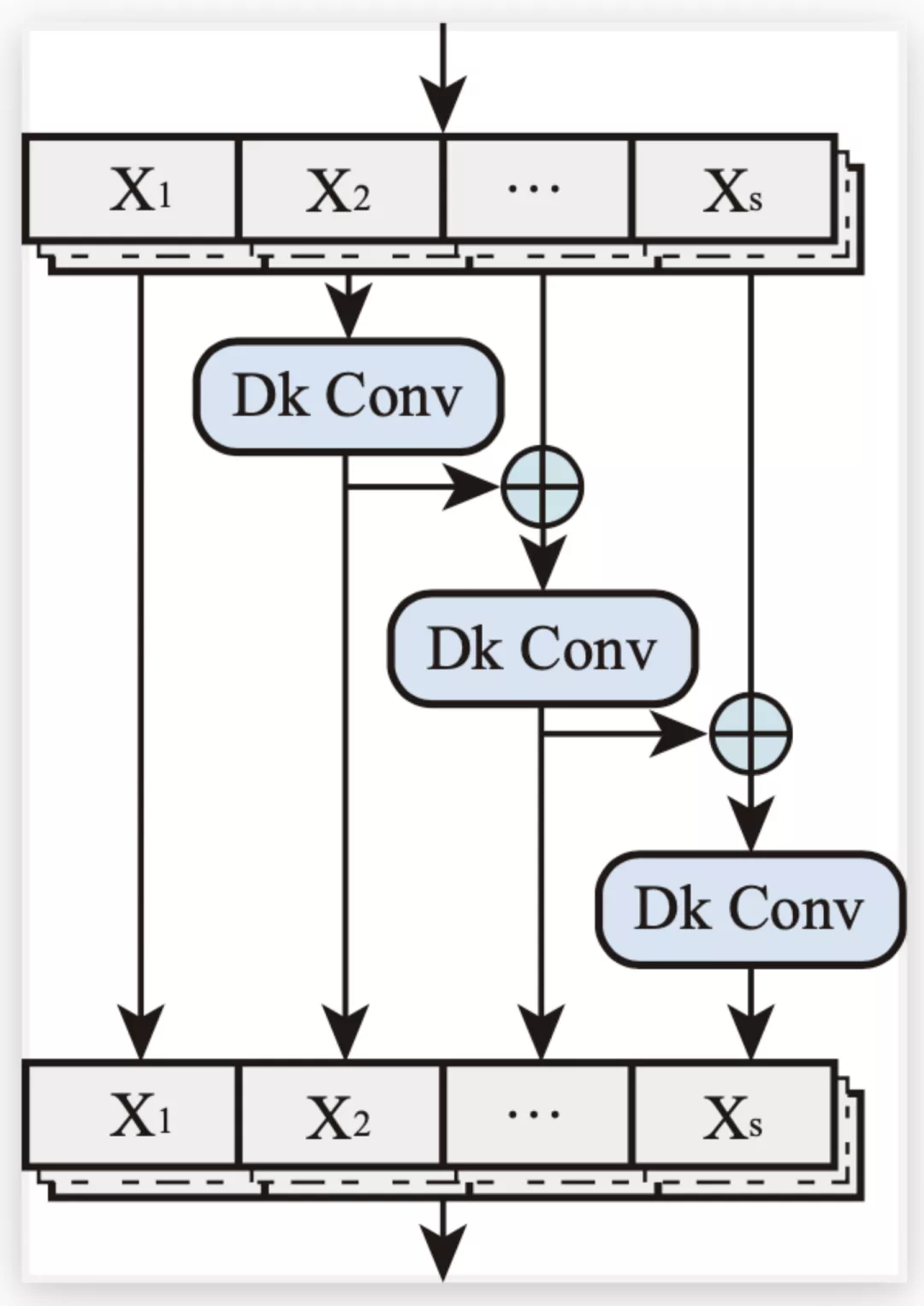
圖 3: 局部多尺度學習。在圖中,"Dk Conv" 表示動態卷積核操作,⊕表示逐元素相加
一組過濾器首先從相應的特征子集中提取特征。然后將前一組的輸出特征與另一組輸入特征一起發送到下一組過濾器:
其中 F 表示 Dk Conv 的操作。在 Multi-scale Dk Block 中,Dk Conv 過濾器的數量是 D-TDNN 層通道數的 1/s 倍。所有的 F 操作完結后,可以得到 Outi 的串聯作為當前模塊的輸出:
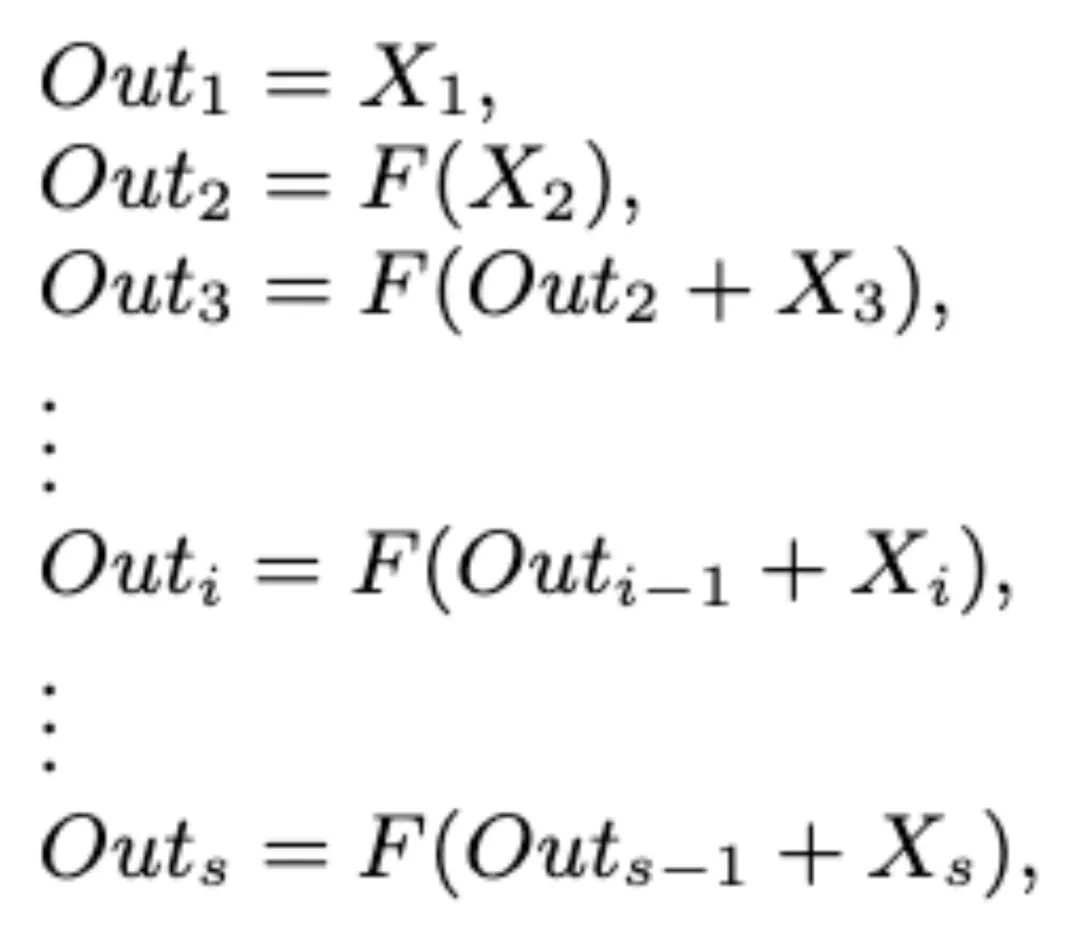
最后,在處理完這些特征集合后,將所有組的特征按照通道數連接起來并發送到下一個操作以融合信息。通過引入超參數 s,局部多尺度學習(在粒度級別表示多尺度特征)被證明可以有效地增加卷積運算的感受野范圍。此外,隨著每一個尺度卷積濾波器數量的減少,模型參數量也得到了顯著下降。
3. 全局多尺度池化
前人的工作得出結論:不同層的特征聚合可以提高聲紋識別任務中說話人表征的區分性。瓶頸特征是一種高層次的信息聚合。因此在通道維度上聚合不同的瓶頸特征并將它們送入統計池層,以增強語種 / 方言分類能力是十分必要的。全局多尺度池化方法的結構如圖 4 所示。
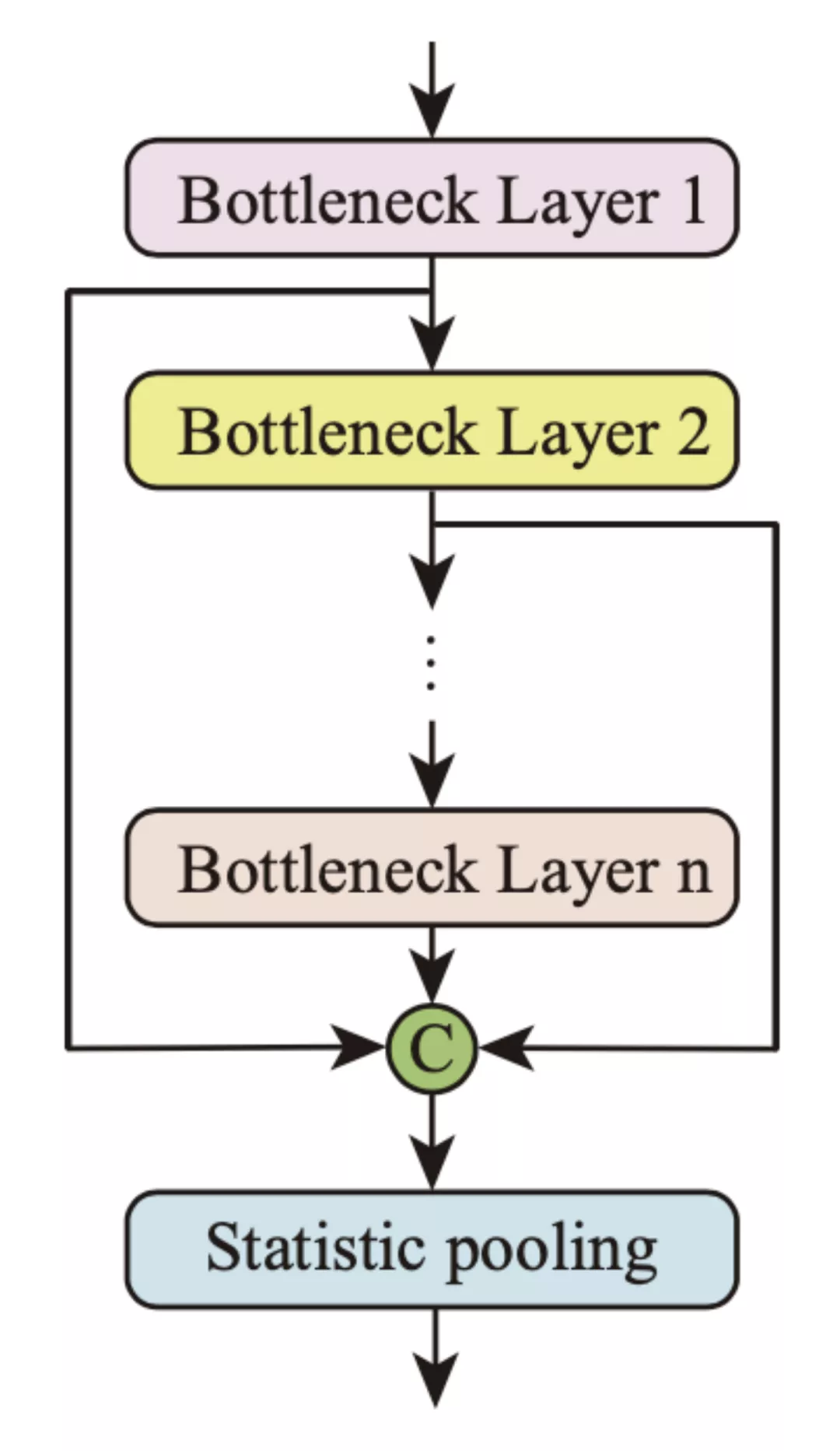
圖 4: 全局多尺度池化
該團隊重新定義了幀級特征 h_t,在通道維度上聚合了不同層的瓶頸特征 h_bi (i = 1, · · · , n),其中 n 是瓶頸層的數量。
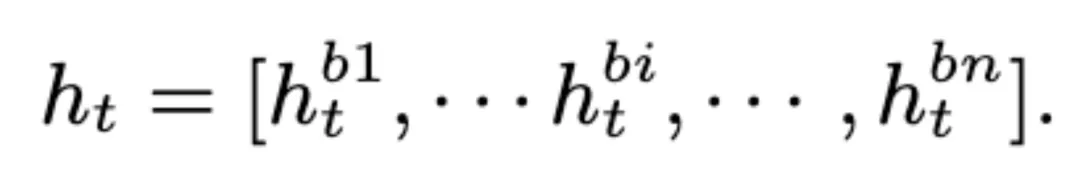
全局多尺度池化層在幀級特征 h_t(t = 1,... ,T) 上以標準差向量 σ 的形式計算均值向量 μ 以及二階統計量。
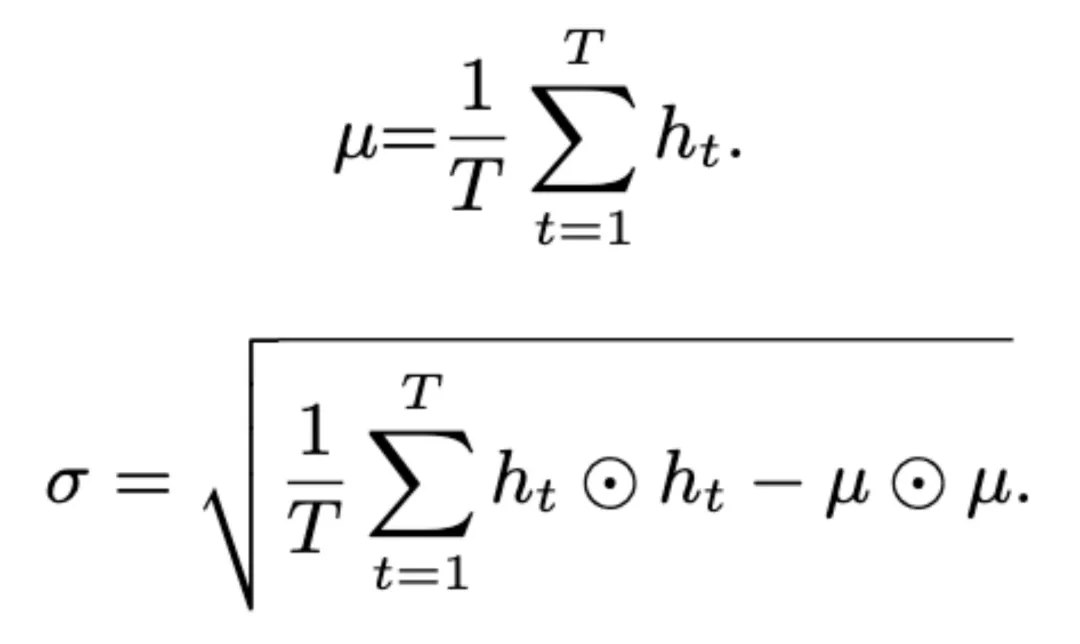
該團隊在實驗中使用兩個瓶頸層用于全局多尺度池化。實驗表明,使用全局多尺度池化方法可以產生更加具有區分力的語種 / 方言表征。
實驗結果
為了證明所提模型在語種 / 方言識別任務上的有效性,該團隊研究人員在東方語種 OLR2020 挑戰賽識別任務 2 的方言識別任務上面進行了測試實驗,采用了兩個評價指標:平均損失性能 Cavg 和等錯誤率 EER 進行性能評估,并且和主流的語種 / 方言識別技術進行了性能和參數量的對比。
1. 東方語種識別大賽數據介紹
在 2020 年東方語言識別 (OLR) 挑戰賽中,該團隊使用 AP17-OL3、AP17-OLR-test、AP18-OLR-test、AP19-OLR-dev、AP19-OLR-test 和 AP20-OLR-dialect 作為語種 / 方言任務的訓練集。所有訓練數據包括 16 種語言,包括日語、韓語、閩南話、上海話、四川話等語種 / 方言。組合數據集的詳細信息如表 1 所示。
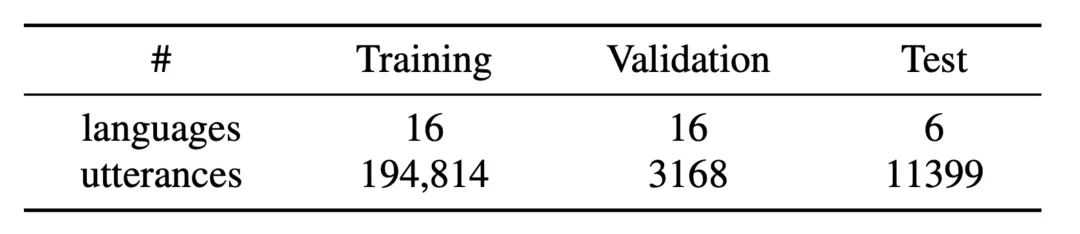
表 1: 訓練集和評估集的數據。
2. 橫向對比
從表 2 中,我們可以觀察到,在相同的語種 / 方言識別任務中,動態多尺度卷積方法的性能明顯優于東方語種識別 2020 任務 2 中 top2 的模型。與 OLR Challenge 2020 排行榜 No.1 (SOTA,state-of-the-art)識別系統相比,我們的模型僅使用 290 萬個參數即可分別實現 9.2% 的 Cavg 和 45% 的 EER 相對改進。

表 2: 與 top2 系統的比較。在這張表中,Royal Flush 和 Phonexia 分別是 2020 年 OLR 挑戰賽排行榜的第 2 名和第 1 名。該系統相比 top1 分別實現了 9% 的 Cavg 和 45% 的 EER 相對改進。
3. 縱向對比
表 3 顯示在東方語種識別中語種 / 方言識別任務上的消融研究的性能。測評分析了福建話、四川話和上海話的 Softmax-output 分數。該方案所有提出的模型在 EER 方面都要優于 OLR2020 挑戰賽中 最先進系統。值得注意的是,該團隊所提出的動態多尺度卷積方法在包括 Cavg 在內的所有指標中都取得了最佳性能,這表明該方法對于語種 / 方言識別任務是非常有效的。

表 3: 東方語種 2020 比賽賽道二語種 / 方言識別任務上的消融實驗
實驗結果表明,與使用 Softmax 損失函數的模型相比,使用 AAM-Softmax 的模型可以獲得更優異的性能。與基線系統 D-TDNN 的方法相比,動態卷積核的操作是非常有助于進行語種 / 方言識別的。局部多尺度動態卷積核將多尺度學習與動態卷積核相結合,通過引入多尺度學習,進一步提高了性能,相對減少了 36% 的參數,而模型參數量僅有 250 萬。此外卷積內的局部多尺度學習方法可以有效地通過超參數 s 減少模型參數量。全局和局部多尺度動態卷積核方法采用了全局多尺度池化方法,是局部多尺度動態卷積核的變體。將全局和局部多尺度動態卷積核的結果與局部多尺度動態卷積核結果進行比較,可以看出全局多尺度池化對于提高語種 / 方言識別的性能是大有幫助的。
目前,語種 / 方言識別已應用于快手視頻審核、同城直播、推薦、素材挖掘等多個業務場景,為各個業務帶來顯著收益。
- 在同城直播業務,利用方言直播識別技術為同城直播打上方言標簽,助力同城主播的消費指標提升。
- 在推薦業務場景,為視頻打上語種(或方言)標簽,助力推薦將作品進行區域分發,提升視頻的消費效果。