提出AI消除性別偏見新方法,適用于任何模型
?陳丹琦新論文來了!
研究團隊全員女將,這是她在普林斯頓的第一篇all-female author論文。

論文主題也和女性議題有關。
論文提出了MABEL,一種使用限定標簽來讓AI減少性別偏見的方法。
通過這一方法,團隊證明如果上游預訓練中對于性別偏見的矯正,能直接影響下游任務。
而且適用于任何模型。
目前該論文被EMNLP 2022接收,項目已開源。
在Hugging Face上也能找到使用了這一方法的BERT-base和BERT-large模型,即插即用。

使用限定標簽減輕偏見
陳丹琦團隊的這個新方法MABEL,全稱是一種使用專用標簽消除性別偏見的方法(a Method for Attenuating Gender Bias using Entailment Labels)。
MABEL是在任務不可知的情況下來消除偏見的,換言之,這種方法適用于任何模型。
此前適用于這種情況的消除偏見方法,比較流行的是SEAT(句子編碼器關聯測試),但后來被相關研究證明:
其內在指標衡量出的結果與外部指標沒有直接的相關性。
也就是說,雖然一個模型在使用SEAT方法測試其消除偏見的得分很高,但在實際執行任務的過程中仍然不及預期。
而這次研究團隊呢,吸取了SEAT的經驗,內在指標與外部指標兩手抓。
并且據團隊介紹,MABEL還是第一個利用來自監督句子對的語義信號來消除偏見的方法。
那它到底是怎樣來消除模型中的性別偏見的呢?
一言以蔽之,MABEL通過對預訓練數據庫中的所有帶有敏感屬性的詞進行反義替換,其他詞則保持不變,然后進行對比學習來消除偏見。
具體來說,研究團隊做了兩方面的工作。
首先是數據集方面,研究團隊使用的是自然語言推理(NLI)數據集,它在訓練有區別性和高質量的句子表征方面特別有效。
由于研究團隊主攻性別歧視方向的偏見,因此,他們從NLI數據集中提取了在前提或者假設中包含性別術語的所有隱含對。
然后對數據進行反事實增強,即將數據集中包含性別敏感的詞匯全部替換成反義詞匯,如男生→女生…
接下來的步驟就比較關鍵了:訓練!
訓練主要針對的是以下三個損失函數:

第一個是基于隱含的對比損失 (Entailment-based contrastive loss),它比較像SimCSE。

△SimCSE

△Entailment-based contrastive loss
這種對比性的損失是將具有類似含義的兩個句子進行對比,使兩個句子的隱含對中有更強的關聯,進而使編碼器學習更多豐富的語義關聯。
第二個是對齊損失 (Alignment loss),這就比較好理解了,它是用來表示原始隱含對和其增強對之間的內部關聯。
也就是說,這個函數能夠使模型最后生成的結果在男女之間更加平衡,以保證最后模型生成的結果性別歧視降到最低。

第三個是掩碼語言模型損失 (Masked language modeling loss),這是最后額外附加的一個損失,目的是為了保持模型的語言建模能力。
研究團隊在所有句子中隨機屏蔽了15%的標記。通過利用周圍的上下文來預測原始的術語,編碼器被激勵去保留token級別的知識。
最終的損失函數如下:

講了這么多,那MABEL這個方法偏見消除的效果如何?
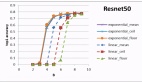
研究團隊直接做了個可視化的柱狀圖來呈現這個方法消除性別歧視的效果。
在五個衡量指標中,包括兩個內在指標(左邊兩個)和三個外部指標,MABEL表現出了良好的公平性-性能權衡。

此外,研究團隊還評估了語言模型在使用了消除性別歧視的方法后是否仍然保持一般的語言理解,結果顯示模型能夠很好地保留其在GLUE上的自然語言理解(NLU)能力。

陳丹琦帶隊,全員女將
最后,來看一下研究團隊陣容。
陳丹琦,清華姚班校友,計算機領域近年來最受關注的青年學者之一。

現任普林斯頓大學助理教授,NLP組共同負責人、也是AIML組成員。
此前,她憑借在信息學競賽圈內的傳奇經歷引發眾人關注——CDQ分治算法就是以她的名字命名。2008年,代表中國隊斬獲一枚IOI金牌。
她長達 156 頁的博士畢業論文《Neural Reading Comprehension and Beyond》,也一度火爆出圈。不光獲得當年斯坦福最佳博士論文獎,還成為了斯坦福大學近十年來最熱門畢業論文之一。
今年2月,陳丹琦憑借在NLP領域的成就和潛力,斬獲斯隆研究獎,該獎項素有“諾獎風向標”稱號。
論文一作為Jacqueline He。

她是一位今年剛剛畢業的普林斯頓計算機系本科生,目前是在Meta工作。
陳丹琦介紹說,Jacqueline同時也在申請博士學位。
團隊中還有一位陳丹琦的學生Mengzhou Xia。

她現在是普林斯頓計算機專業的一位博士生,本科畢業于復旦大學,后赴卡內基梅隆大學讀研。研究興趣領域為大規模預訓練模型的性能和效率。
除此之外,研究團隊中還有一位72歲的高齡女學者。
她是普林斯頓語言學&計算機科學系教授Christiane D. Fellbaum。
其研究領域包括自然語言處理、詞匯語義、計算語言學、文本語料庫等,曾聯合開發WordNet。這是一個基于認知語言學的英語詞典,可按照單詞意思組成了一個“單詞的網絡”。

論文地址:https://arxiv.org/abs/2210.14975
參考鏈接:[1]https://twitter.com/danqi_chen/status/1599828154839093248?[2]https://www.cs.princeton.edu/~danqic/?