MDFR:基于人臉圖像復原和人臉轉正聯合模型的人臉識別方法

本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。
在現實生活中,許多因素可能會影響人臉識別系統的識別性能,例如大姿勢,不良光照,低分辨率,模糊和噪聲等。為了應對這些挑戰,之前的人臉識別方法通常先把低質量的人臉圖像恢復成高質量人臉圖像,然后進行人臉識別。然而,這些方法大多是階段性的,并不是解決人臉識別的最優方案。
AI 科技評論今天介紹一篇能夠對此有著很好的解決方案的論文,在本文中,作者提出一種多退化因子的人臉復原模型(Multi-Degradation Face Restoration,MDFR),來一次性解決所有的這些影響因素。

原文標題:《Joint Face Image Restoration and Frontalization For Recognition》
論文地址:https://ieeexplore.ieee.org/document/9427073/
MDFR 可以從給定的多姿態、多重低質量因素影響的人臉圖像中復原其高質量的正面人臉圖像。MDFR是一個設計良好的編碼器-解碼器網絡結構。
在模型的構建中,作者引入了姿態殘差學習策略,以及一個基于3D的姿勢歸一化模塊(3D-based Pose Normalization Module,PNM),該模塊可以感知輸入人臉姿態和正面人臉姿態之間的差異,以此差異來指導人臉的轉正學習。
實驗表示,訓練完成之后的MDFR可以通過一個單一化的網絡,一次性地從多重低質量因素影響的側面人臉圖像中恢復其高清的正面人臉圖像,并有效的提高人臉算法的識別率。
1、背景及簡介
非限制條件下的人臉識別方法是計算機視覺任務中一項重要的工作。在實際應用中,采集到的人臉圖像可能包含大姿態,不良光照,低分辨率以及模糊和噪聲等,這些影響人臉成像質量的因素可能導致人臉識別應用的失敗。為了解決這些問題,已經有很多方法使用分階段模型來分別處理相應的低質量因子影響的人臉圖像,即首先將低質量人臉恢復成高質量的人臉圖像,隨后進行人臉轉正并用于人臉識別。
然而這些方法都只考慮了人臉識別的單一因素,很少有方法能夠同時解決影響人臉識別的多重因素。因此,這類基于單一因素的人臉處理方法并不能很好的適用于非限制條件下的人臉識別。在本文中,作者提出了一種解決多退化因子的人臉復原模型(MDFR),從給定任意姿態的低質量人臉圖像中恢復出高質量正面人臉。
文章的貢獻如下:
- 提出了一種多退化因子人臉復原模型(Multi-Degradation Face Restoration, MDFR),將給定的任意姿態和受多重低質量因子影響的人臉圖像恢復為正面且高質量的圖像;
- 在人臉轉正過程中,使用了姿態殘差學習策略,并且提出了一種基于3D的姿態歸一化模塊;
- 提出了一種有效的整合訓練策略將人臉重建和轉正任務融合到一個統一的網絡中,該方法能夠進一步提升輸出的人臉質量和后續的人臉識別效果;
2、方法描述
MDFR結構如圖1所示。在訓練過程中,MDFR主要包含兩個模塊,即雙代理生成器(Dual-Agent Generator)和雙代理判別器(Dual-Agent Discriminator)。姿態歸一化模型模塊(Pose Normalization Module, PNM)被嵌入到網絡中對人臉的姿態進行歸一化。
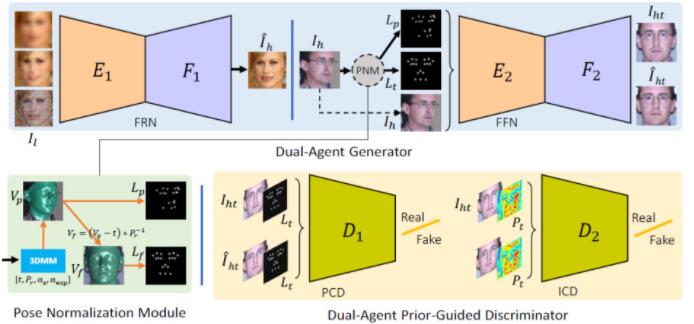
圖1. MDFR模型的結構,包括雙代理生成器,姿態歸一化模型,以及雙代理判別器。
(1)雙代理生成器
雙代理生成器包含一個人臉復原子網絡(Face Restoration sub-Net, FRN)和一個人臉轉正子網絡(Face Frontalization sub-Net, FFN)。FRN網絡的作用是將低質量人臉圖像重建為高質量人臉圖像,而FFN網絡將FRN生成的側臉圖像進行轉正。其中每個子網絡均包含一個編碼器和解碼器,前者用來將輸入映射到特征空間,而后者主要將編碼后的特征重建為相應的目標人臉圖像。兩個子網絡具有相同的網絡結構,但是輸入有所不同。FRN的編碼器對輸入的人臉圖像進行編碼,隨后解碼器對編碼器的特征進行解碼。FFN的解碼器的輸入除了人臉的編碼特征外,還包含人臉兩種姿態的編碼殘差,如圖2所示。
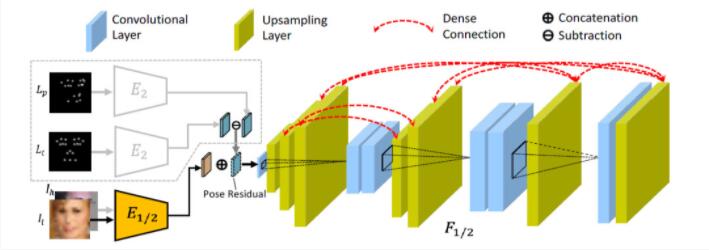
圖2生成網絡的網絡結構
(2)姿態歸一化模塊
作者設計了一個姿態歸一化模塊(PNM)對姿態進行歸一化。PNM提供了標準的、并且尺度統一的真實正面姿態來來引導人臉轉正。基于3D形變模型(3D Morphable Model, 3DMM),二維人臉圖像對應的三維頂點可以通過人臉正交基線性加權相加而得到:
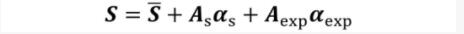
通過尺度正交映射將三維人臉頂點映射到二維圖像平面,二維側臉人臉圖像可以表示為:

其中,參數MDFR :基于人臉圖像復原和人臉轉正聯合模型的人臉識別方法是相應的旋轉矩陣,t 為平移向量。當移去旋轉矩陣和平移向量后,歸一化后真實轉正的人臉密集二維坐標可以表述為:
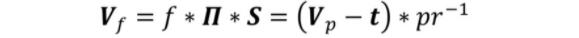
在文章中,作者使用3D人臉轉正方法 2DAL 從一張給定的二維人臉圖像中獲取人臉密集坐標,最后選取18個常用的關鍵點來生成相應的高斯熱力圖(Gaussian Heatmaps)。
(3)雙代理先驗引導判別器
在人臉超分辨率領域使用的判別損失能夠很好的提高重建人臉的真實度。因此,在本文中,作者在判別器中加入兩種額外的先驗信息:目標人臉的landmarks以及正臉的身份特征圖,使得生成的人臉不僅能夠獲得目標姿態,還具有真實的身份信息。對應的判別器分別為PCD(Pose Conditioned Discriminator)以及ICD(Identity Conditioned Discriminator)。
在實現過程中,作者將兩種先驗信息分別作用到輸入判別器中引導人臉的生成,然后再輸入到相應的判別器中進行判別損失的求解。PCD和ICD不僅可以區分真實人臉和生成的人臉,同時可以學習到真實人臉和生成人臉的姿態和身份差異。
(4)網絡訓練
網絡的訓練主要分為兩個階段:Separate Training和TI Training。
Separate Training:文章首先分別訓練FRN和FFN兩個子網絡,兩個訓練過程分別簡寫為FRN-S和FFN-S。FRN-S訓練過程中所用到的損失函數如下:
身份信息損失:
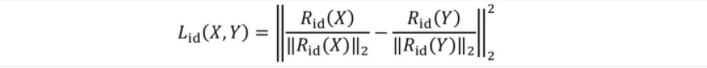
重建像素損失:
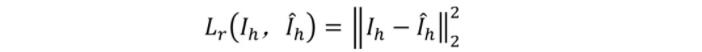
總的損失:
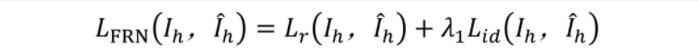
FFN-S訓練過程中所用到的損失函數如下:
轉正損失:
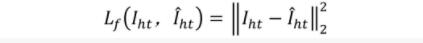
條件對抗損失:
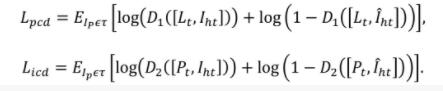
總的損失:
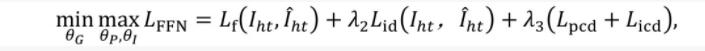
Task-Integrated (TI) training:在FRN和FFN完成了相應的分開訓練后,作者在預訓練模型的基礎上進行整合訓練。在這個階段,作者使用FFN模型的輸出作為ground-truth來訓練FRN。同時,使用PNM歸一化后的真實轉正面部landmarks來引導FFN中人臉的轉正。為了生成更好的人臉效果,在這一階段作者還使用了特征對齊損失(Feature Alignment Loss, FA),具體的定義如下:
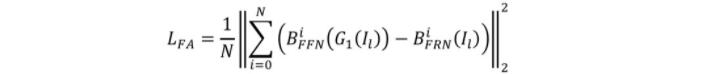
整體的訓練損失函數為:
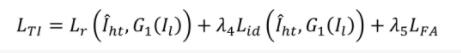
3、實驗結果
作者首先探索了不同的網絡結構和損失函數的組合來觀察FFN-S和FRN-TI相應部分對人臉生成的影響,實驗結果如圖3所示。
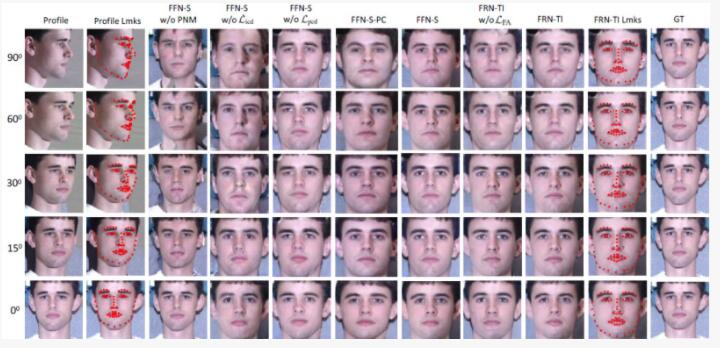
圖3. 消融實驗在Multi-PIE數據庫上的對比結果。
同時,表1展示了 MDFR 的不同變異體對不同姿態人臉的 rank-1 識別率。在所有的實驗模型中,FFN-S 和 FRN-TI 均獲得了最好的精度。
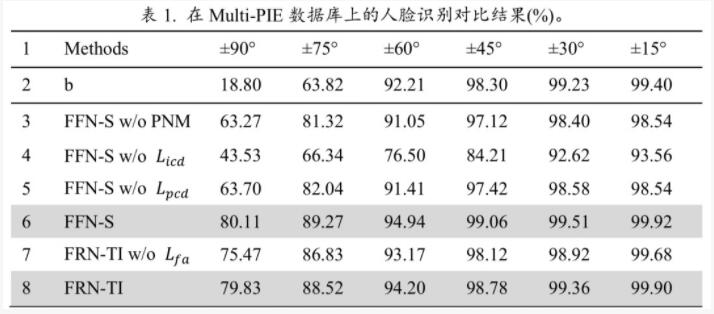
表2列舉了 FFN-S 和 FRN-TI 同其他方法在 Multi-PIE 數據集上人臉識別率的比較。FFN-S 在所有的姿態中獲得了最好的效果,其次是FFN-TI。當姿態角度在±45°以內時,FFN-S 和FFN-TI獲得了同 CAPG-GAN 相似的識別效果。但當姿態角度大于±45°時,FFN-S 和 FFN_TI 的效果要顯著的好于 CAPG-GAN。
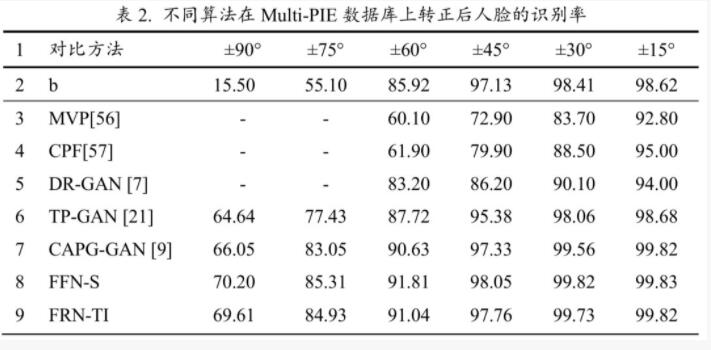
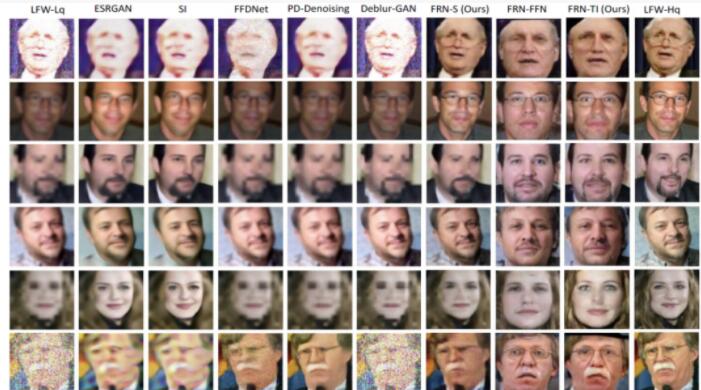
圖4. 不同方法在多重低質量因素影響下的人臉復原效果
作者在多重低質量因素影響的人臉圖像上進行相應的驗證,包括低分辨率、不良光照、噪聲以及模糊。實驗表明,文章提到的方法不僅可以充分應對多種低質量因子,而且都可以生成相應的高質量人臉圖像。圖4展示了不同方法在多重低質量因素影響下的人臉復原效果。可以看出不同于之前只能處理單一的任務的方法,文中所提出的方法既可以對人臉進行轉正也可以進行高質量復原,且取得了最好的視覺效果。