













一篇文章帶你了解內存中的Slice
因為沒找到一個合適的中文詞來表示slice的確切含義,所以文中將直接使用slice這個單詞。
實際上,slice表示的是數組的一部分,可以稱為數組片段。
內存中的數組一文學習研究了數組及數組類型在內存中的表現形式。
slice是依賴數組而存在的,本文在 數組 基礎上繼續學習slice。
slice內存結構示意圖
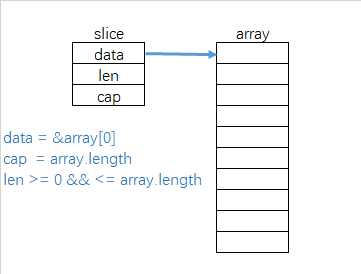
data指針并不一定指向底層數組的起始位置,可以指向數組的任何一個元素地址。
但是對于slice本身來說,data指針指向一個數組的開始。
環境
- OS : Ubuntu 20.04.2 LTS; x86_64
- Go : go version go1.16.2 linux/amd64
聲明
操作系統、處理器架構、Go版本不同,均有可能造成相同的源碼編譯后運行時的內存地址、數據結構不同。
本文僅保證學習過程中的分析數據在當前環境下的準確有效性。
代碼清單
- package main
- import "fmt"
- func main() {
- var a = [10]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
- var s = a[:5]
- PrintInterface(s)
- }
- //go:noinline
- func PrintInterface(v interface{}) {
- fmt.Println("it =", v)
- }
變量a是一個聲明并初始化的數組,變量s是通過數組a創建的slice。
深入內存
動態調試,在 main 函數的入口處設置斷點,查看程序指令:
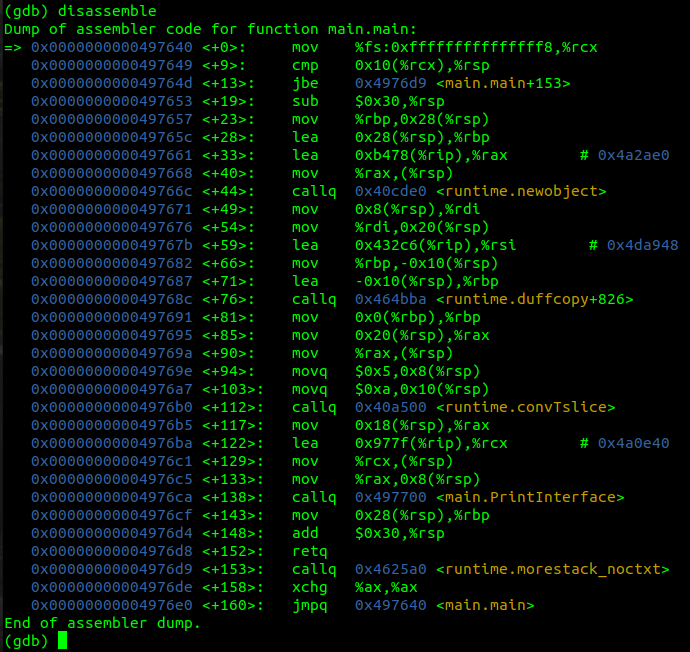
數組初始化
從上圖中指令可以看出,數組的聲明和初始化是分兩步實現的。
- var a = [10]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
數組創建
在分配 main 函數的棧幀之后,立即調用 runtime.newObject 函數分配了一個數組,其參數是0x4a2ae0。
在內存中的數組中我們看到小數組直接分配在棧內存,大數組分配在堆內存。而在這里,小數組也直接通過動態分配的方式創建在堆內存。猜測這應該是與代碼執行上下文有關。
數組類型結構定義在reflect/type.go源碼文件中,如下所示:
- // arrayType represents a fixed array type.
- type arrayType struct {
- rtype
- elem *rtype // array element type
- slice *rtype // slice type
- len uintptr
- }
我們來看看該數組的類型:
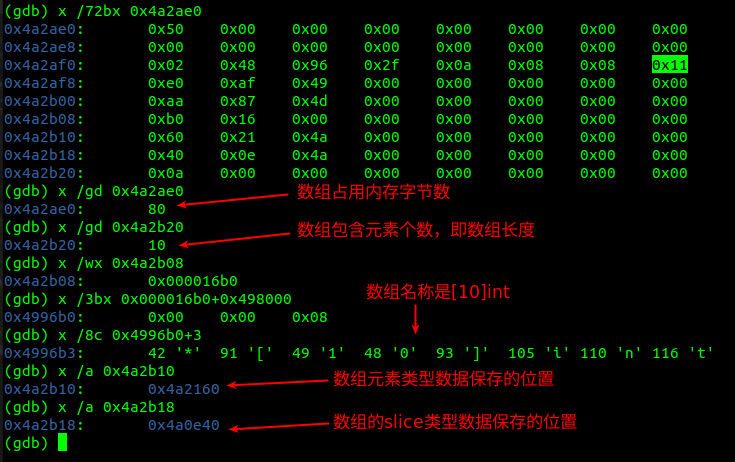
剛剛創建的數組長度是10,占用80個字節的內存,名稱是[10]int,與代碼清單一致。
數組賦值
代碼清單中聲明的數組數據,在代碼編譯之后保存在可執行文件的 .rodata section。程序運行時,數組數據的內存地址是:0x4da948。

在數組創建之后,數組元素的值全部都是零。初始化賦值操作是通過調用 runtime.duffcopy 函數復制0x4da948地址處的數據實現的。
關于達夫設備,稍后詳細介紹。
slice結構體
slice的創建是通過 runtime.convTslice 函數實現的。
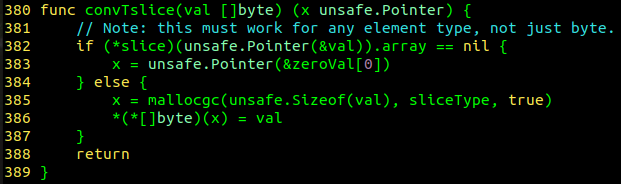
通過源碼可以看出,該函數和之前看到的其他 runtime.convTx 函數類似,復制棧內存一個slice對象到堆內存;不同的是,把slice對象作為[]byte類型的數據進行復制。
同時,源碼中可以看到一個 *slice 類型,這很令人興奮。在 runtime/slice.go 源碼文件中,找到了runtime.slice結構體的定義:
- type slice struct {
- array unsafe.Pointer
- len int
- cap int
- }
slice結構體由三部分組成:
- 指向數組的指針:該數組保存著具體的數據
- 長度:也就是slice包含元素的數量
- 容量:也就是數組的長度
從其結構來看,與Java中的java.util.ArrayList非常類似。
在調用 runtime.convTslice 函數的指令處下斷點,觀察其參數。
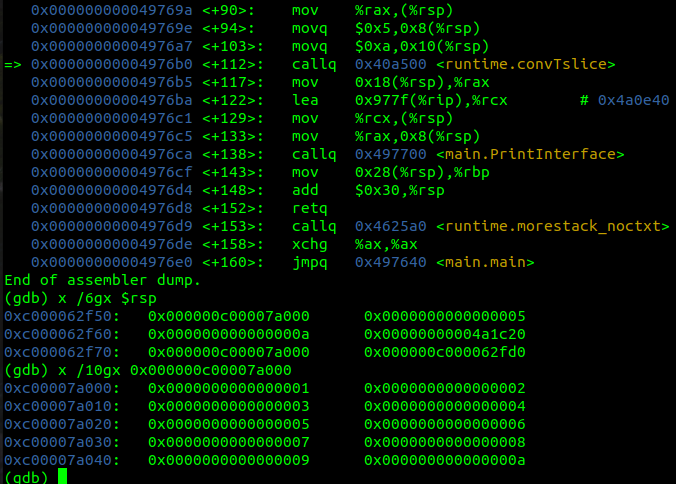
從上圖可以看出,runtime.convTslice函數的參數,本身就是位于棧頂的一個runtime.slice結構體,該函數會把這個結構體數據復制到堆內存:
- 0x000000c00007a000 // 數組的地址
- 0x0000000000000005 // slice的長度
- 0x000000000000000a // slice的容量(數組的長度)
我們再看runtime.convTslice函數的返回值。

返回值是通過棧內存傳遞的,保存在緊挨參數的位置,值是0x000000c00000c030;這是一個指針,指向的數據與參數完全相同,最終作為PrintInterface函數的參數,用于打印輸出數據。
通過查看Golang源代碼,發現有多處定義了slice結構體,它們在內存中是等價的(雖然有細微差別):
- 在 reflect/value.go 源碼文件中的SliceHeader結構體
- type SliceHeader struct {
- Data uintptr
- Len int
- Cap int
- }
- 在internal/unsafeheader/unsafeheader.go 源碼文件中的Slice結構體
- type Slice struct {
- Data unsafe.Pointer
- Len int
- Cap int
- }
slice類型
slice類型的定義在Golang源碼 reflect/type.go 文件中。
- // sliceType represents a slice type.
- type sliceType struct {
- rtype
- elem *rtype // slice element type
- }
在調用PrintInterface函數的指令處下斷點,觀察slice類型信息。
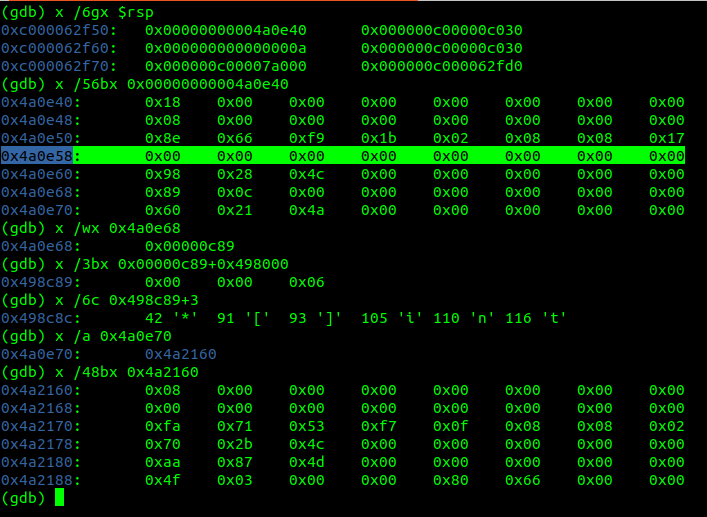
rtype.size
slice對象占0x18(24)個字節。
- 指針:8字節
- 長度:8字節
- 容量:8字節
rtype.ptrdata
8字節(number of bytes in the type that can contain pointers)。
slice結構體的第一個字段是指針類型,長度和容量字段不是指針類型,所以只有8字節包含指針。
在前面的學習中,研究的都簡單數據類型,不包含指針,所以其類型的ptrdata都是零。
rtype.hash
值為 0x1bf9668e 。
rtype.tflag
0x02 = reflect.tflagExtraStar
請看 rtype.str 字段值。
rtype.align
8字節對齊。
rtype.fieldAlign
作為結構體字段時8字節對齊。
rtype.kind
值為0x17(23)。
rtype.equal
值為零。說明slice對象不進行相等性比較。
reflect.Type 接口中聲明了一個 Comparable() bool 方法,用于檢測判斷該類型的數據是否可以進行比較。具體實現如下,二者個關系便一目了然了。
- func (t *rtype) Comparable() bool {
- return t.equal != nil
- }
rtype.str
表示的值為:*[]int。
rtype.ptrToThis
值為零。
sliceType.elem
該指針指向的數據類型是 int 類型(rtype.kind=reflect.Int)。
達夫設備
在計算機科學領域,達夫設備(英文:Duff's device)是串行復制(serial copy)的一種優化實現,通過匯編語言編程時一種常用方法,實現展開循環,進而提高執行效率。
How does Duff's device work?
在Golang中,runtime.duffcopy函數聲明如下,實際是通過Golang匯編實現的。
x86_64的具體實現位于源碼的 runtime/duff_amd64.s 文件中。
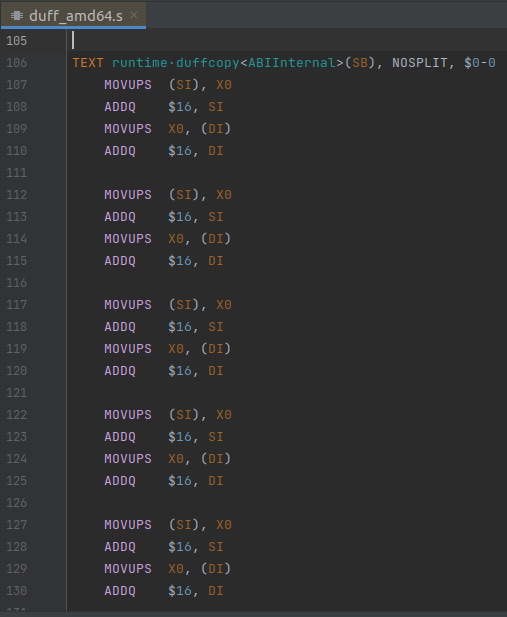
該函數的實現共322行,實在是太長了,我們在這里截取一部分,以便了解其實現細節和學習其優秀的設計思想。
在不了解達夫設備的情況下,看到該函數代碼的第一眼,可能會產生兩種錯覺:
- 實現這個函數的程序員估計是很懶,寫個循環不香嗎?
- 實現這個函數的程序員這么喜歡復制粘貼代碼,是按代碼行數領工資的嗎?
實際情況是,該函數實現是經過精心設計的,用于優化內存中的數據復制操作。
不過,該函數很可能就是通過復制粘貼實現的,共包含64個這樣的代碼塊:
- MOVUPS (SI), X0
- ADDQ $16, SI
- MOVUPS X0, (DI)
- ADDQ $16, DI
該代碼塊(以下稱為“復制單元”)的作用是:從源地址復制16字節的數據到目的地址。也就是說這四條指令,一次可以復制2個int值。
那么意味著,如果runtime.duffcopy函數從頭到尾完整執行下來:
- 一共可以復制1024(64*16)個字節
- 一共可以復制128(64*2)個 int 值
在本文示例中,我們的數組只包含10個 int 元素,共80個字節。
于是一個個疑問冒出來:
- 調用runtime.duffcopy函數豈不是多復制了944個字節?
- 多復制的數據覆蓋了附近區域的正常數據豈不是要導致程序混亂?
- 為什么程序沒有異常崩潰(segmentation fault)?
- 寫個 "for" 循環不像嗎?
- 像在內存中的數組遇到的那樣使用rep movsq機器指令不香嗎?
實際上,在本文示例中,復制數組數據時,并不是從runtime.duffcopy函數的第一行代碼開始執行的,而是跳過了59個復制單元,直接從第60個復制單元開始執行,共執行了5個復制單元,復制了10個 int 數組元素,然后返回到 main 函數中。
如果創建一個[20]int數組,復制數據時就會從runtime.duffcopy函數的第55個復制單元開始執行。
如果創建一個[128]int數組,復制數據時就會從runtime.duffcopy函數的第1個復制單元開始執行,也就是從第一行代碼開始執行。
當然,到底該從那條指令開始執行,是Golang編譯器決定的,并不是調用方自己決定的,也不是runtime.duffcopy函數決定的。
所以,runtime.duffcopy函數在整個的數據復制過程中,沒有一處條件判斷,沒有一處內存跳轉,完全是順序執行。這是非常高效的操作,是很棒的指令優化。
另外還有三處細節優化:
1.在調用runtime.duffcopy函數時,直接使用rdi、rsi寄存器保存兩個地址參數;在數據復制過程中,使用ADD指令修改兩個寄存器的值實現內存地址遞增。
- 這是我在Golang中遇到的第一個完全使用寄存器保存參數的函數。
- 按照常規的編程約定:第一個參數保存在rdi寄存器,第一個參數保存在rsi寄存器。
- 所以可以這樣理解其函數聲明:func duffcopy(dst [1024]byte, src [1024]byte)。
2.調用方為runtime.duffcopy函數分配8字節的棧幀內存用于保存rbp寄存器的值,并負責銷毀該棧幀,使其能夠專注于數據復制,不做其他任何事情。(實際也可以不分配該棧幀。)(這讓我想起了 red zone。)
3.使用 movups指令和 xmm0寄存器,有效壓縮了指令數量,從而提高執行效率。
總而言之,runtime.duffcopy函數是一個高度優化的“達夫設備”。
最后,還有兩個問題:
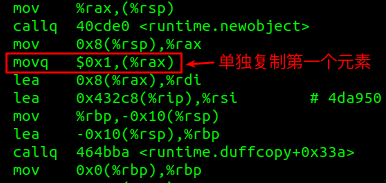
1.如果 int 數組長度是奇數會怎么樣?
答案是:先使用movq指令復制第一個元素,剩下偶數個數組元素使用runtime.duffcopy函數復制。
當數組長度為11時,var a = [11]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10},機器指令如下:
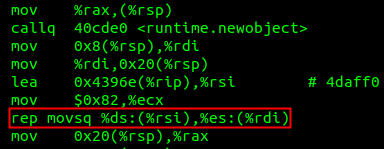
2.如果 int 數組長度超過128會怎么樣?
答案是:使用rep movsq指令代替runtime.duffcopy函數。這個在意料之中。
在本文中,仔細研究了slice類型和slice對象在內存中的存儲結構。
本文轉載自微信公眾號「Golang In Memory」


















