圖靈獎得主Bengio又出新論文,Reddit崩潰:idea撞車了
機器學習的一個重要研究就是提升模型的泛化性,并且在訓練模型的時候一個假設,即訓練集數據的分布和測試集相同。
然而,模型面對的輸入數據來自于真實世界,也就是不穩定的、會進化的、數據分布會隨環境發生變化。
雖然對人類來說,這個問題十分好解決,例如網絡用語層出不窮,但每個人都能很快地接受,并熟練地運用起來,但對機器來說卻很難。
人類可以通過重用相關的先前知識來迅速適應和學習新知識,如果把這個思路用在機器學習模型上,首先需要弄清楚如何將知識分離成易于重新組合的模塊,以及如何修改或組合這些模塊,以實現對新任務或數據分布的建模。
基于這個問題,圖靈獎得主Yoshua Bengio最近在arxiv上公開了一篇論文,提出了一個模塊化的架構,由一組獨立的模塊組成,這些模塊相互對抗,利用key-value注意力機制找到相關的知識。研究人員在模塊和注意力機制參數上采用元學習方法,以強化學習的方式實現快速適應分布的變化或新任務。

這個團隊研究這樣的模塊化架構是否可以幫助將知識分解成不可更改和可重用的部分,以便得到的模型不僅更具樣本效率,而且還可以在各種任務分布之間進行泛化。
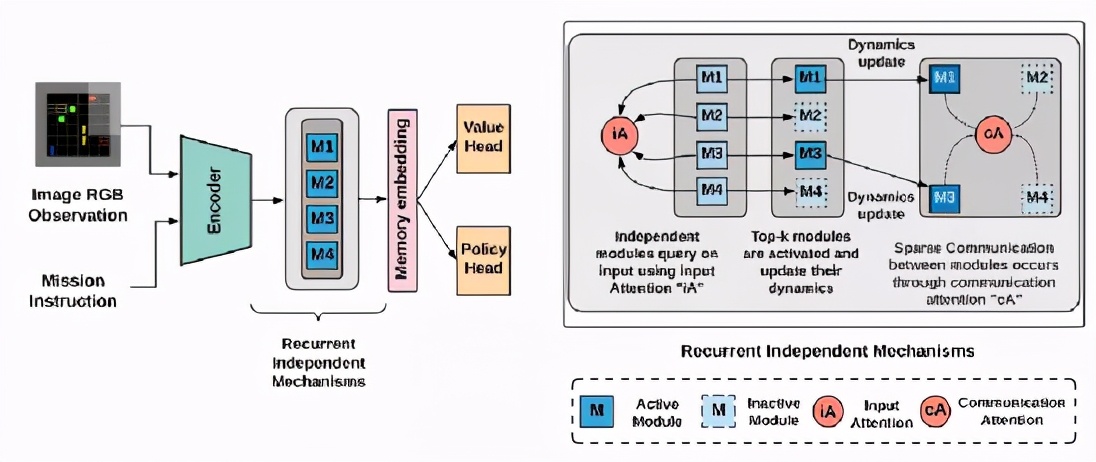
該模型基于一個包含一組獨立模塊和競爭模塊的循環獨立機制(RIMs)體系結構。在這種設置中,每個模塊通過注意力獨立行動,并與其他模塊交互。不同的模塊通過輸入注意力處理輸入的不同部分,而模塊之間的上下文關系通過交流注意力建立。
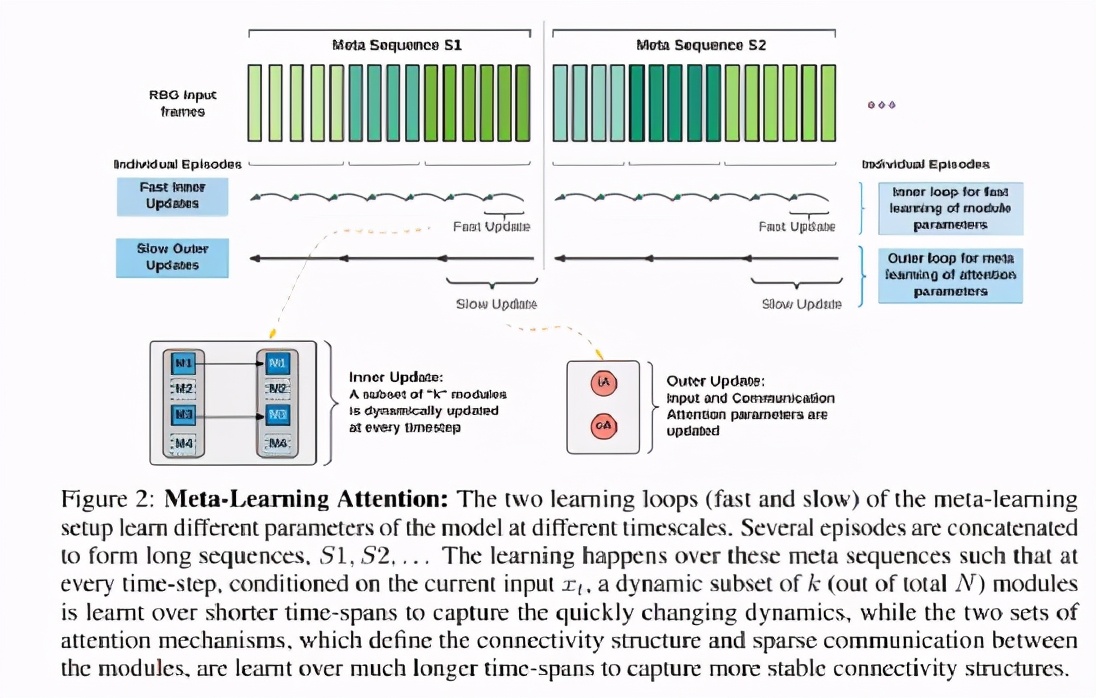
研究人員還展示了如何利用元學習在不同的時間尺度上以不同的速度訓練網絡的不同組成部分,從而捕捉到底層分布的快速變化和緩慢變化的方面。
因此,該模型既有快速學習階段,也有慢速學習階段。
在快速fast學習中,快速更新激活的模塊參數以捕獲任務分布中的變化。
在緩慢slow學習中,這兩套注意力機制的參數更新頻率較低,以捕捉任務分布中更穩定的方面。
該團隊評估了他們提出的 Meta-RIMs 網絡在從 MiniGrid 和 BabyAI 套件的各種環境。他們選擇平均回報率和平均成功率作為衡量標準,并用兩個基準模型對 Meta-RIMs 網絡進行比較: Vanilla LSTM 模型和模塊化網絡(modular network)。
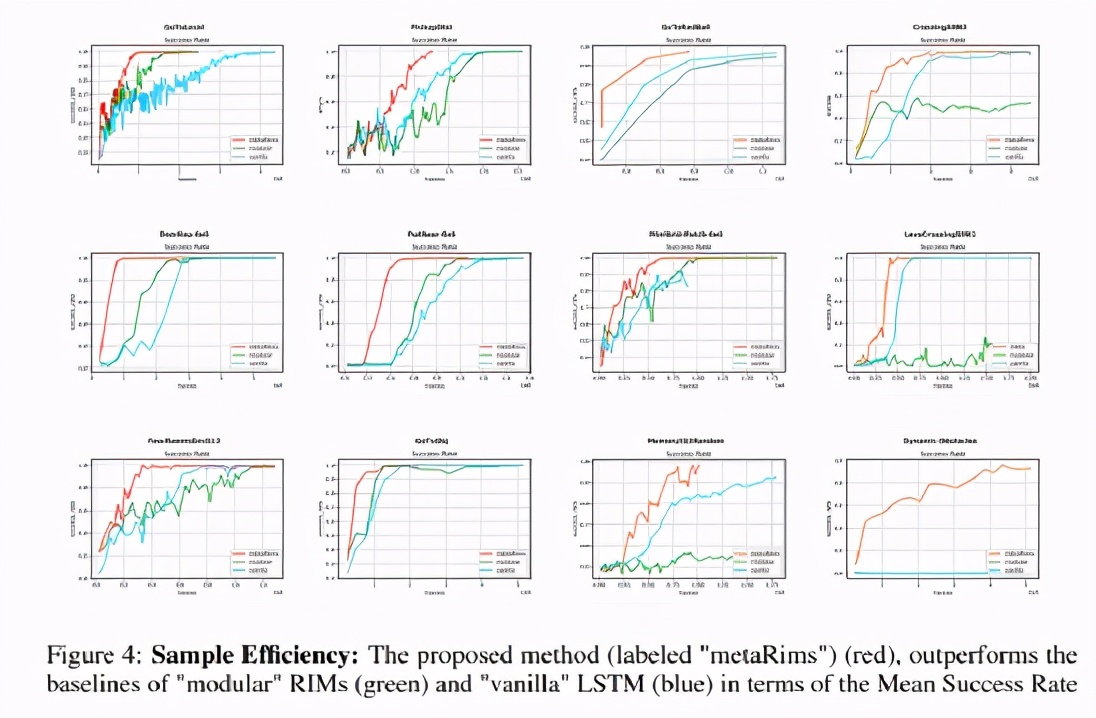
結果表明,所提出的方法能夠提高樣本效率,導致更好地推廣到訓練分布的系統性變化的策略。
此外,這種方法能夠更快地適應新的發行版本,并且通過重復利用從類似的以前學過的任務中獲得的知識,以漸進的方式訓練強化學習的學習體,形成更好的知識學習方法。
該研究成功地利用模塊化結構上的元學習和稀疏通信來捕捉潛在機制的短期和長期方面,證實了元學習和基于注意力的模塊化可以導致更好的樣本效率、分布外的泛化和遷移學習。
Reddit網友idea撞車?
論文一出,Reddit上立馬引發熱議。
一個小哥發評論說感覺相當難受了,我做這個4年了,今年就要發表,但還是被領先了。后來又補充說并不是一模一樣的工作,但是非常接近。
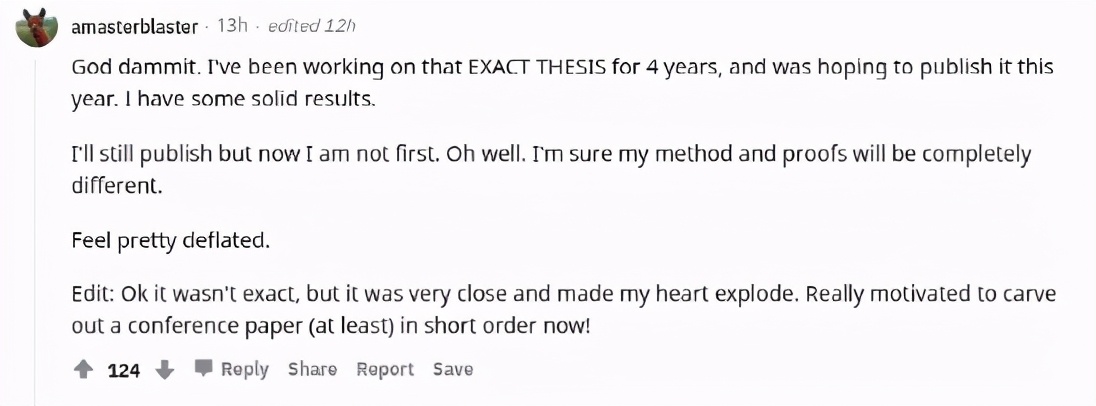
這也引來了無數安慰,相似的結論可能來源于不同的方法,每個方法都是有價值的。
還有網友認為,你的實力已經可以和Bengio及他的團隊匹敵了,這是一件好事!并且有其他人和你面對同一件事有不同的想法,也許也能給你啟發,促進工作。
知乎上也有網友對此提出問題。
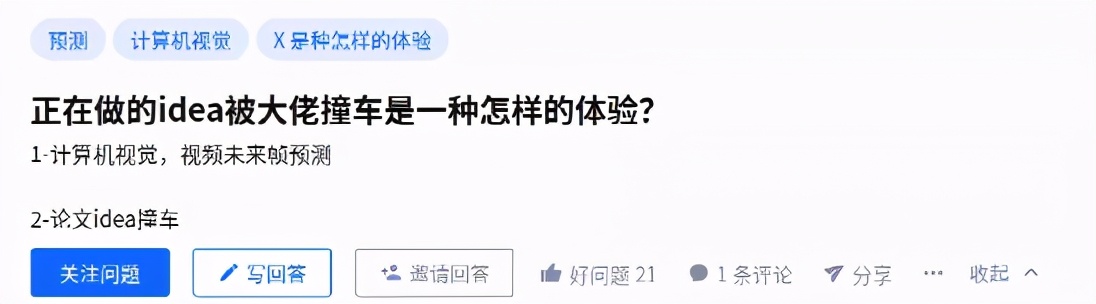
有網友表示,兩篇論文全撞車,CV太卷了,當做的論文和大佬撞車時候,完全沒有反抗的余地,因為別人的工作是無懈可擊的。有機會一定要挖坑,不去填坑。
目前深度學習的一些工作已經到了拼手速的地步,當BERT一出,各種基于BERT的工作層出不窮,只是一個驗證的工作,而不能對同行有一定的啟發。
畢竟牛頓和萊布尼茨還在爭奪微積分,普通人撞車也是很正常的。
你有論文撞車過嗎?