清華唐杰團隊造了個“中文ai設計師”,效果超Dall·E
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
要說2021年OpenAI最熱最有創意的產品,那么非Dall·E莫屬了,這是一個可以從“AI設計師”,只要給它一段文字,就能按要求生成圖像。但可惜的是Dall·E并不支持中文。
現在好了,最近清華大學唐杰團隊打造了一個“中文版Dall·E”——CogView,它可以將中文文字轉圖像。
CogView可以生成現實中真實存在場景,如“一條小溪在山澗流淌”:

也可以制造不存在的虛擬事物,如“貓豬”:

有時候還有點黑色幽默,如“一個心酸的博士生”:

CogView現在還提供了試玩網頁,你可以在那里輸入任何文字去轉成圖形,不像OpenAI的Dall·E只提供幾個關鍵詞修改選項。
能指定畫風,能設計服裝
CogView的能力可不僅僅是從文字輸入圖像,它還能處理不同微調策略的下游任務,例如風格學習、超分辨率、文本圖像排名和時裝設計。
在使用CogView的時候,可以加入不同風格限定,從而生成不同的繪畫效果。在微調期間,圖像對應的文本也是“XX風格的圖像”。

CogView設計的服裝也像模像樣,看起來就像電商展示頁,沒有虛假痕跡。

原理
CogView是一個帶有VQ-VAE分詞器40億參數的Transfomer,它的總體結構如下:
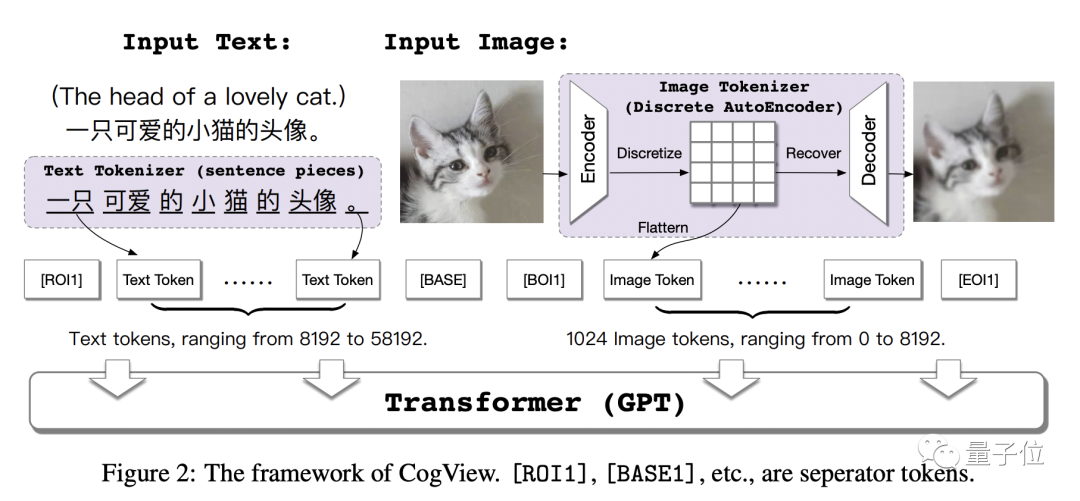
CogView使用GPT模型處理離散字典上的token序列。然后將學習過程分為兩個階段:編碼器和解碼器學習最小化重建損失,單個GPT通過串聯文本優化兩個負對數似然 (NLL) 損失。
結果是,第一階段退化為純離散自動編碼器,作為圖像tokenizer將圖像轉換為標記序列;第二階段的GPT承擔了大部分建模任務。
圖像tokenizer的訓練非常重要,方法有最近鄰映射、Gumbel采樣、softmax逼近三種,Dall·E使用的是第三種,而對于CogView來說三者差別不大。
CogView的主干是一個單向Transformer,共有48層、40個注意力頭、40億參數,隱藏層的大小為2560。
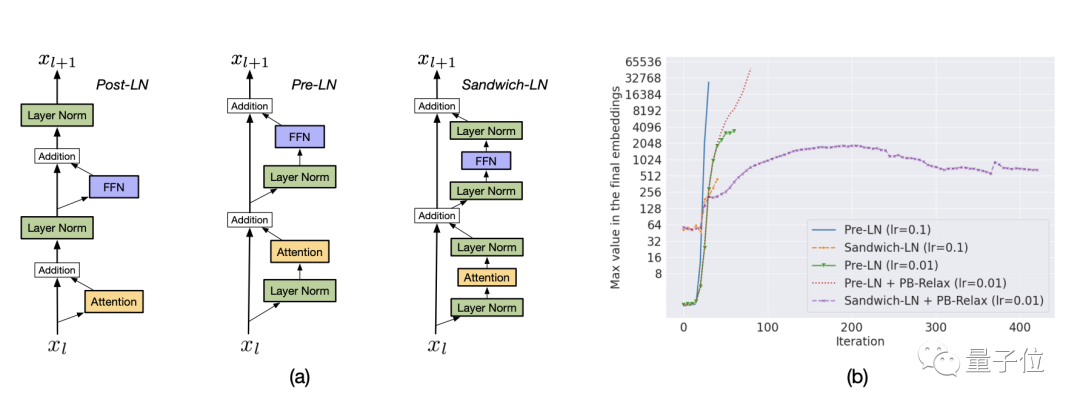
在訓練中,作者發現CogView有兩種不穩定性:溢出(以NaN損失為特征)和下溢(以發散損失為特征),然后他們提出了用PB-Relax、Sandwich-LN來解決它們。
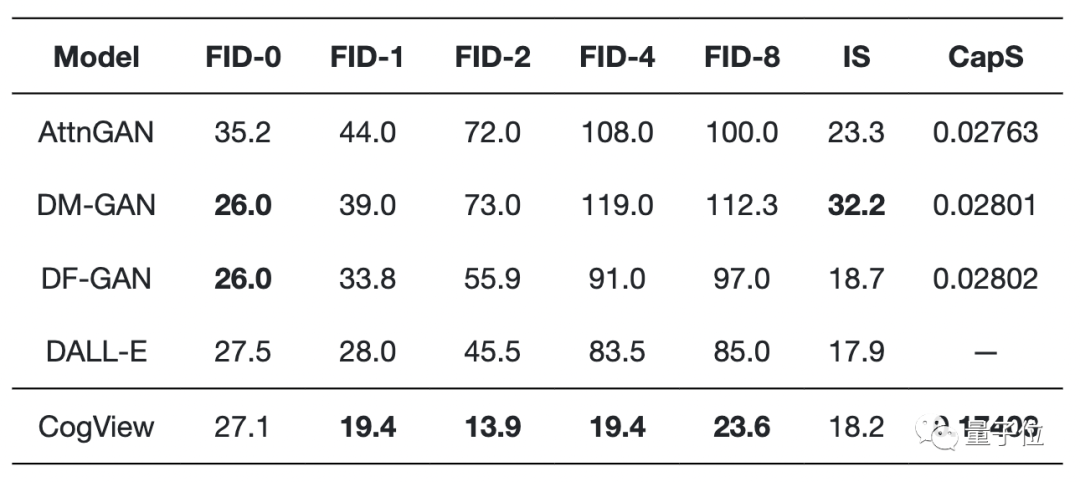
最后,CogView在MS COCO實現了最低的FID,其性能優于以前基于GAN的模型和以及類似的Dall·E。
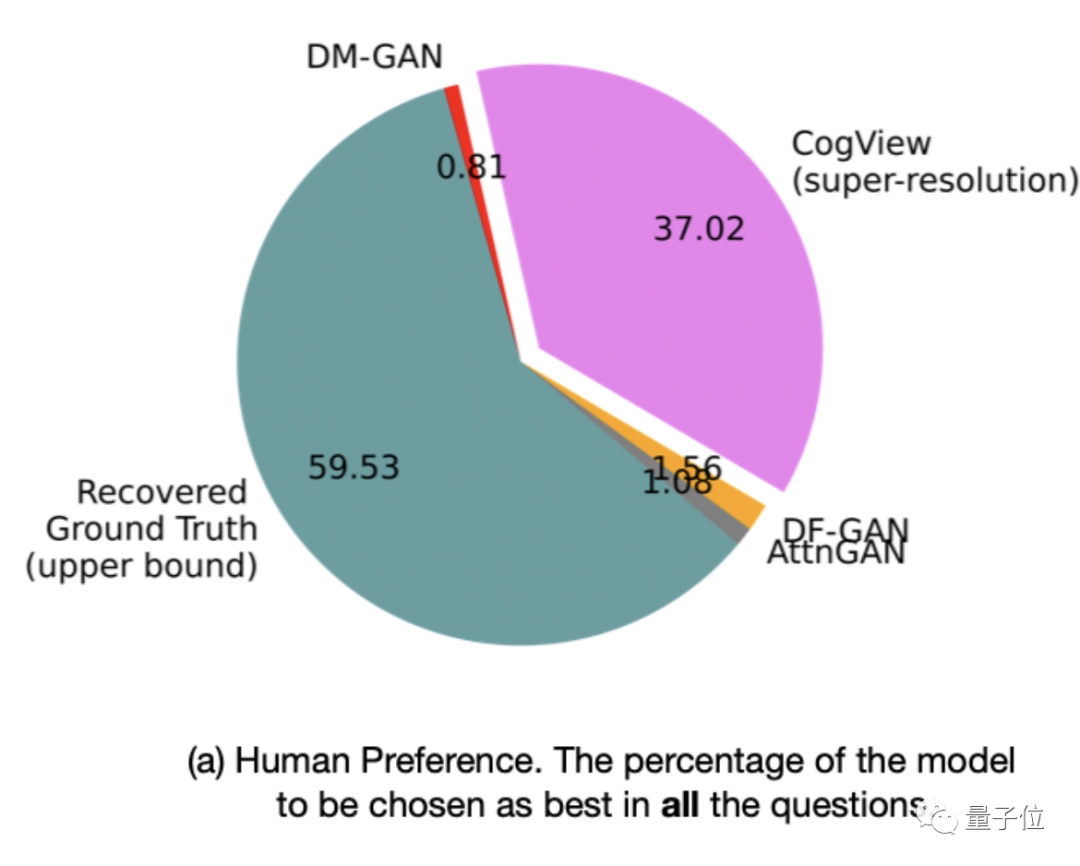
而在人工評估的測試中,CogView被選為最好的概率為37.02%,遠遠超過其他基于GAN的模型,已經可以與Ground Truth(59.53%)競爭。
另外作者已經放出了GitHub項目頁,不過目前還沒有代碼,感興趣的朋友可以關注一下等代碼放出。
論文地址:
https://arxiv.org/abs/2105.13290
試用Demo:
https://lab.aminer.cn/cogview/index.html
GitHub頁:
https://github.com/THUDM/CogView