清華唐杰團隊:一文看懂NLP預訓練模型前世今生
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
搞出了全球超大預訓練模型的悟道團隊,現在來手把手地教你怎么弄懂預訓練這一概念了。
剛剛,清華唐杰教授聯合悟道團隊發布了一篇有關預訓練模型的綜述:

整篇論文超過40頁,從發展歷史、最新突破和未來研究三個方向,完整地梳理了大規模預訓練模型(PTM)的前世今生。

現在就一起來看看這篇論文的主要內容吧。
預訓練的歷史
論文首先從預訓練的發展過程開始講起。
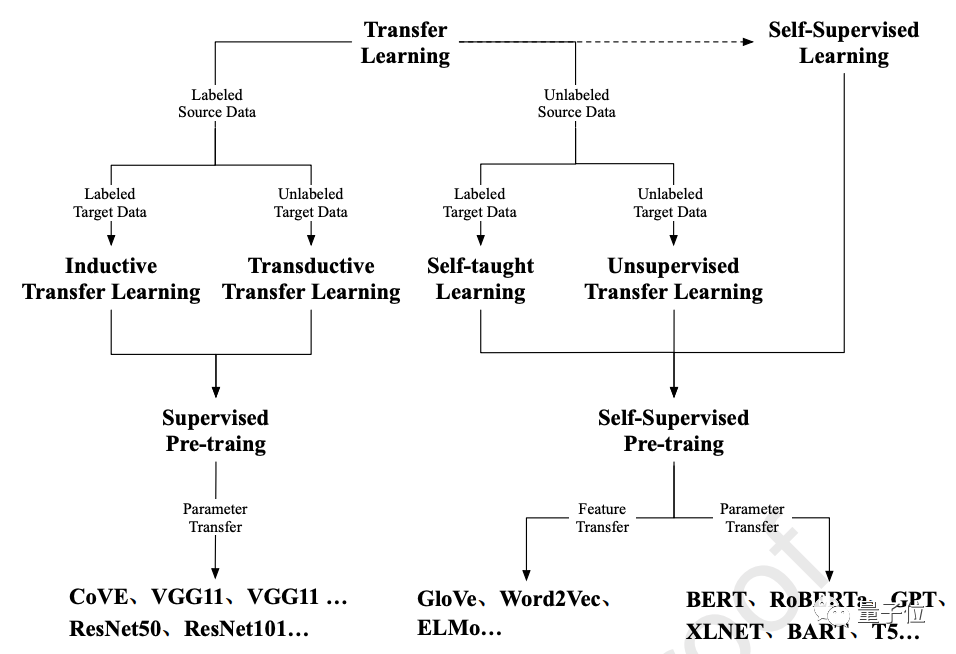
早期預訓練的工作主要集中在遷移學習上,其中特征遷移和參數遷移是兩種最為廣泛的預訓練方法。
從早期的有監督預訓練到當前的自監督預訓練,將基于Transformer的PTM作用于NLP任務已經成為了一種標準流程。
可以說,最近PTM在多種工作上的成功,就得益于自監督預訓練和Transformer的結合。
這也就是論文第3節的主要內容:
神經架構Transformer,以及兩個基于Transformer的里程碑式的預訓練模型:BERT和GPT。
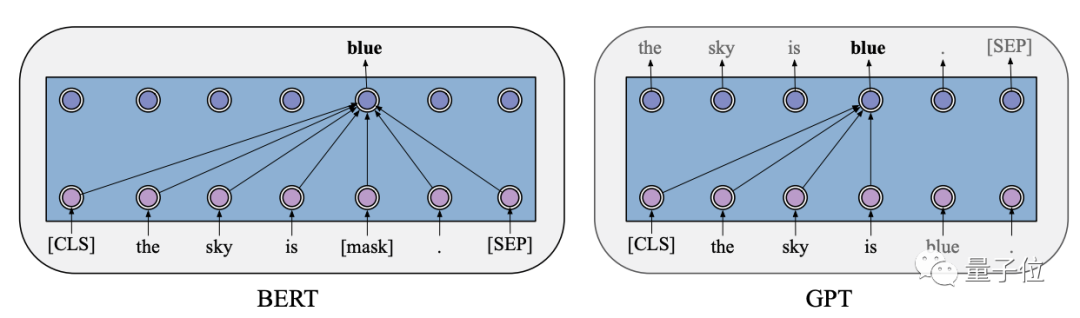
兩個模型分別使用自回歸語言建模和自編碼語言建模作為預訓練目標。
后續所有的預訓練模型可以說都是這兩個模型的變種。
例如論文中展示的這張圖,就列出了近年修改了模型架構,并探索了新的預訓練任務的諸多PTM:
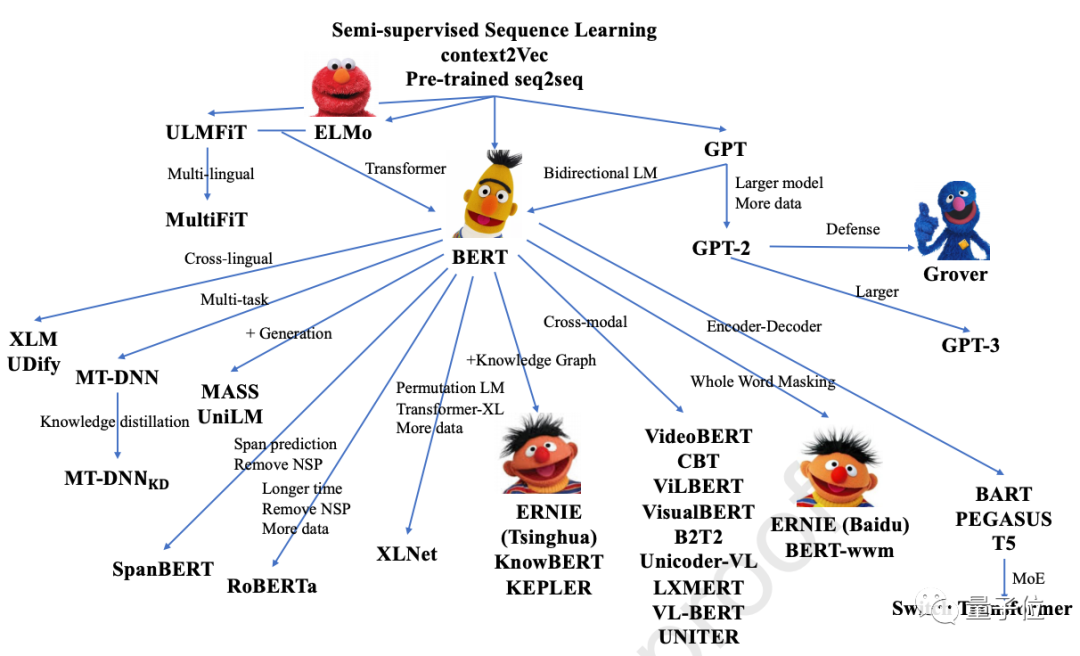
大規模預訓練模型的最新突破
論文的4-7節則全面地回顧了PTM的最新突破。
這些突破主要由激增的算力和越來越多的數據驅動,朝著以下四個方向發展:
設計有效架構
在第4節中,論文深入地探究了BERT家族及其變體PTM,并提到,所有用于語言預訓練的基于Transformer的BERT架構都可被歸類為兩個動機:
- 統一序列建模
- 認知啟發架構
除此以外,當前大多數研究都專注于優化BERT架構,以提高語言模型在自然語言理解方面的性能。
利用多源數據
很多典型PTM都利用了數據持有方、類型、特征各不相同的多源異構數據。
比如多語言PTM、多模態PTM和知識(Knowledge)增強型PTM。
提高計算效率
第6節從三個方面介紹了如何提升計算效率。
第一種方法是系統級優化,包括單設備優化和多設備優化。
比如說像是ZeRO-Offload,就設計了精細的策略來安排CPU內存和GPU內存之間的交換,以便內存交換和設備計算能夠盡可能多地重疊。
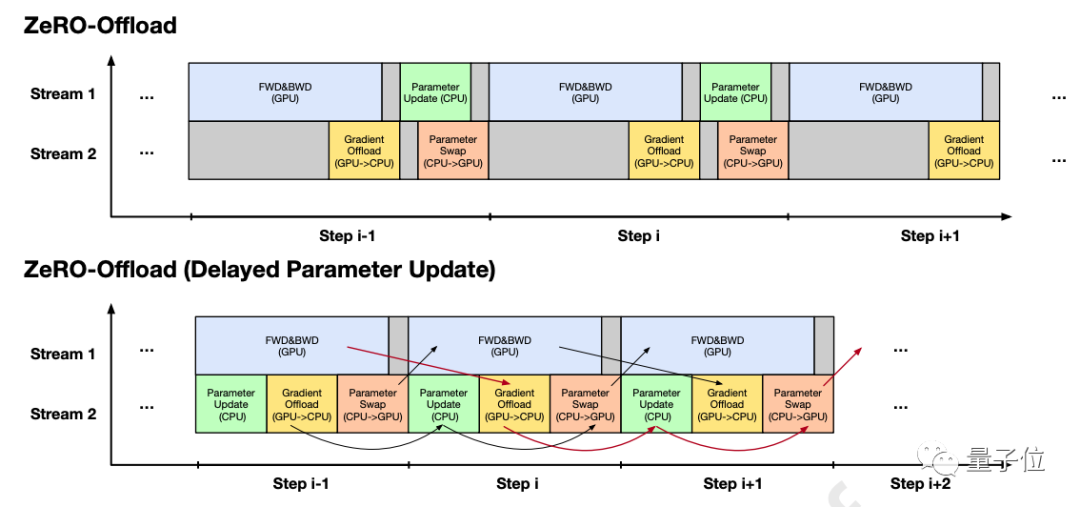
第二種方法是探索更高效的預訓練方法和模型架構,以降低方案的成本。
第三種則是模型壓縮策略,包括參數共享、模型剪枝、知識蒸餾和模型量化。
解釋和理論分析
對于PTM的工作原理和特性,論文在第7節做了詳細的解讀。
首先是PTM所捕獲的兩類隱性知識:
一種是語言知識,一般通過表征探測、表示分析、注意力分析、生成分析四種方法進行研究。
另一種是包括常識和事實在內的世界知識。
隨后論文也指出,在最近相關工作的對抗性示例中,PTM展現出了嚴重的魯棒性問題,即容易被同義詞所誤導,從而做出錯誤預測。
最后,論文總結了PTM的結構稀疏性/模塊性,以及PTM理論分析方面的開創性工作。
未來的研究方向
到現在,論文已經回顧了PTM的過去與現在,最后一節則基于上文提到的各種工作,指出了PTM未來可以進一步發展的7個方向:
- 架構和預訓練方法
包括新架構、新的預訓練任務、Prompt Tuning、可靠性
- 多語言和多模態訓練
包括更多的模態、解釋、下游任務,以及遷移學習
- 計算效率
包括數據遷移、并行策略、大規模訓練、封裝和插件
- 理論基礎
包括不確定性、泛化和魯棒性
- 模識(Modeledge)學習
包括基于知識感知的任務、模識的儲存和管理
- 認知和知識學習
包括知識增強、知識支持、知識監督、認知架構、知識的互相作用
- 應用
包括自然語言生成、對話系統、特定領域的PTM、領域自適應和任務自適應
論文最后也提到,和以自然語言形式,即離散符號表現的人類知識不同,儲存在PTM中的知識是一種對機器友好的,連續的實值向量。
團隊將這種知識命名為模識,希望未來能以一種更有效的方式捕捉模識,為特定任務尋找更好的解決方案。
更多細節可點擊直達原論文:
http://keg.cs.tsinghua.edu.cn/jietang/publications/AIOPEN21-Han-et-al-Pre-Trained%20Models-%20Past,%20Present%20and%20Future.pdf