Tiedemann 發(fā)布的數(shù)據(jù)集讓非洲語(yǔ)言也能「機(jī)翻」
孩童時(shí)候,看哆啦A夢(mèng)印象比較深的一集就是「翻譯年糕」,那時(shí)候就希望自己能吃一塊能讀懂各種外語(yǔ),次次考滿分......如今來(lái)看,實(shí)現(xiàn)這個(gè)「小目標(biāo)」有希望了!
赫爾辛基大學(xué)語(yǔ)言技術(shù)教授Jörg Tiedemann于2021年3月3號(hào)宣布,他已經(jīng)發(fā)布了188種語(yǔ)言的5億多個(gè)翻譯句子。
這是一個(gè)自動(dòng)翻譯數(shù)據(jù)集,可用于數(shù)據(jù)增強(qiáng)翻譯。
機(jī)器翻譯(MT)屬于計(jì)算機(jī)語(yǔ)言的范疇,其研究借由計(jì)算機(jī)程序?qū)⑽淖只蜓菡f(shuō)從一種自然語(yǔ)言翻譯成另一種自然語(yǔ)言。
研究機(jī)器翻譯的研究人員經(jīng)常依靠反向翻譯來(lái)增加訓(xùn)練數(shù)據(jù)。
反向翻譯是指,給定源語(yǔ)言句子x,目標(biāo)語(yǔ)言句子y, 用訓(xùn)練好的目標(biāo)語(yǔ)言到源語(yǔ)言的翻譯模型得到偽句對(duì)(x’, y),加入到平行句對(duì)中一起訓(xùn)練。
這種訓(xùn)練方式也能起到去噪的作用,即不完美的機(jī)翻模型的輸出包含了噪聲。
在有噪聲的情況下,訓(xùn)練(x', y)和(x, y)的翻譯模型如果都能得到y(tǒng)的輸出,則提升了泛化性能。
當(dāng)更多的單語(yǔ)目標(biāo)語(yǔ)言數(shù)據(jù)被翻譯成源語(yǔ)言時(shí),反向翻譯使得深度學(xué)習(xí)系統(tǒng) CUBITT 能夠“超越人工翻譯”。
反向翻譯的有用性取決于目標(biāo)語(yǔ)言數(shù)據(jù)的廣泛可獲得性,這對(duì)于使用人數(shù)少的小語(yǔ)種來(lái)說(shuō)比較麻煩。
反向翻譯對(duì)于檢測(cè)機(jī)器翻譯內(nèi)容的方法也很關(guān)鍵,尤其是現(xiàn)在初創(chuàng)公司將人工智能驅(qū)動(dòng)的「文本生成」技術(shù)逐漸商業(yè)化。
目前,Tiedemann的論文和數(shù)據(jù)集已經(jīng)發(fā)布在了GitHub上。
這并不是Tiedemann第一次試圖通過(guò)MT為各種語(yǔ)言創(chuàng)造一個(gè)「地球村」。自2018年以來(lái),Masakhane項(xiàng)目一直在專門針對(duì)NLP中代表不足的非洲語(yǔ)言收集語(yǔ)言數(shù)據(jù)并微調(diào)語(yǔ)言模型。

這個(gè)語(yǔ)言模型取得了不錯(cuò)的效果,這位德國(guó)在讀博士就對(duì)這個(gè)模型給予了肯定。
Tatoeba 是一個(gè)龐大的句子和翻譯數(shù)據(jù)庫(kù)。Tatoeba 提供了一個(gè)工具,可以讓你看到你所需要的單詞在句子上下文中是如何使用的。
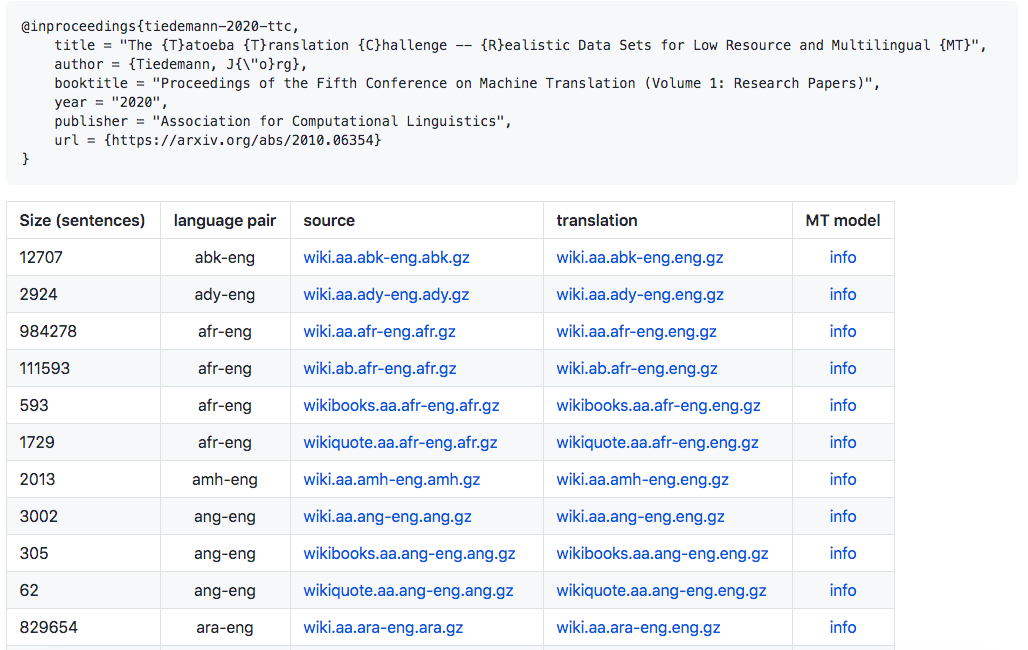
在2020年10月關(guān)于Tatoeba翻譯挑戰(zhàn)的相關(guān)論文中,Tiedemann寫(xiě)道,“我們的主要目標(biāo)是促進(jìn)開(kāi)放翻譯工具和模型的開(kāi)發(fā),從而更廣泛地覆蓋世界各種語(yǔ)言。”
有多寬泛?訓(xùn)練和測(cè)試數(shù)據(jù)涵蓋500種語(yǔ)言和語(yǔ)言變體,以及大約3000種語(yǔ)言對(duì)。忍不住唱一句「你看這個(gè)數(shù)據(jù)集它又大又寬」。
根據(jù) Tiedemann 的說(shuō)法,還有很多工作要做。他在推特上寫(xiě)道: “無(wú)論如何,這不會(huì)是我將要發(fā)布的最后一套翻譯版本”。“很快還會(huì)有更多語(yǔ)言從英語(yǔ)轉(zhuǎn)向其它語(yǔ)言... ...”