AI腦回路竟和人類如此相似,OpenAI最新研究引熱議
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
兩個月前轟動網絡的AI設計大師CLIP,剛剛被OpenAI“扒開”了腦子。
沒想到,這個性能強大的AI竟和人類思維方式如此相像。
打個比方,無論你聽到“炸雞”二個字,還是看到炸雞實物,都可能流口水。因為你的大腦里有一組“炸雞神經元”,專門負責對炸雞起反應。
這個CLIP也差不多。
無論聽到“蜘蛛俠”三個字,還是看到蜘蛛俠的照片,CLIP的某個特殊區域就開始響應,甚至原本用來響應紅色和藍色的區域也會“躁動”。

OpenAI發現,原來CLIP有一個“蜘蛛俠神經元”。
在腦科學中,這并不是啥新鮮事。因為早在15年前,研究人腦的科學家就發現了,一張臉對應一組神經元。
但是對AI來說卻是一個巨大的進步。過去,從文字到圖像,和從圖像到文字,用的是兩套系統,工作方式都不一樣。
而CLIP卻有著和人腦極為相似的工作方式,CV和NLP不僅技術上打通,連腦子里想的都一樣,還有專門的處理區域。
看到二者如此相像,有網友表示:
太可怕了,這說明通用人工智能(AGI)到來,比所有人想象的都快。
而且,OpenAI還驚訝地發現,CLIP對圖片的響應似乎類似與癲癇患者顱內神經元,其中包括對情緒做出反應的神經元。說不定AI今后還能幫助治療神經類疾病。
AI的“腦子”,其實和人類一樣
先前情回顧一下,CLIP到底是神馬。
不久前,OpenAI發布了脫胎于GPT-3的DALL·E,能按照文字描述準確生成圖片。
DALL·E對自然語言和圖像的理解和融匯貫通,做到了前無古人的水準。一經問世,立刻引來吳恩達、Keras之父等大佬點贊。
而DALL·E的核心部分,就是CLIP。
簡單的說,CLIP是一個重新排序模型,檢查DALL·E所有生成結果,挑出好的展現出來。
CLIP能做“裁判”,離不開將文字和圖片意義“融合”理解的能力,但這樣的能力從哪來,之前人們根本不清楚。
OpenAI緊接著深挖CLIP神經網絡的原理結構,發現了它的多模態神經元,具有跟人類大腦類似的工作機制:能夠對文字和圖像中的相同意義同時做出響應。

而所謂模態,是指某個過程或某件事,包含多個不同的特征,圖像通常與標簽和文本解釋相關聯,是完整理解一個事物的要素。
比如,你看到蜘蛛俠三個字,或者是Spiderman,都能聯想起穿著紅藍緊身衣的超級英雄。
熟悉這個概念以后,看到這樣一幅黑白手繪,你也能馬上明白這是“蜘蛛俠”:
CLIP中的多模態神經元,能力與人類沒有任何區別。
這樣專門負責某個事物的神經元,OpenAI發現了好幾個,其中有18個是動物神經元,19個是名人神經元。
甚至還有專門理解情緒的神經元:

其實,人本身就是一個多模態學習的總和,我們能看到物體,聽到聲音,感覺到質地,聞到氣味,嘗到味道。
為了讓AI擺脫以往“人工智障”式的機械工作方式,一條路徑就是讓它向人一樣能夠同時理解多模態信號。
所以也有研究者認為認為,多模態學習是真正的人工智能發展方向。
在實現過程中,通常是將識別不同要素子網絡的輸出加權組合,以便每個輸入模態可以對輸出預測有一個學習貢獻。
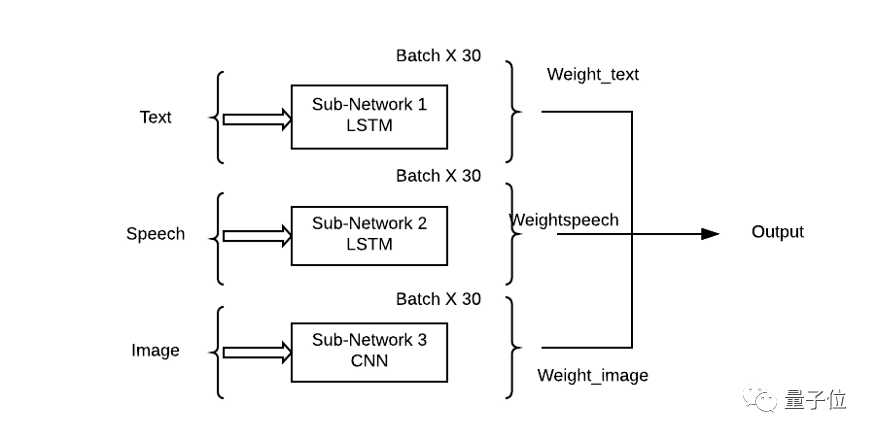
根據任務不同,將不同的權值附加到子網后預測輸出,就能讓神經網絡實現不同的性能。
而具體到CLIP上,可以從研究人員的測試結果中清楚的看到,從語言模型中誕生的它,對于文字,比對圖像更加敏感。
攻擊AI也更容易了
但是,文字和圖像在AI“腦海”中的聯動是一把雙刃劍。
如果我們在貴賓犬的身上加上幾串美元符號,那么CLIP就會把它識別為存錢罐。
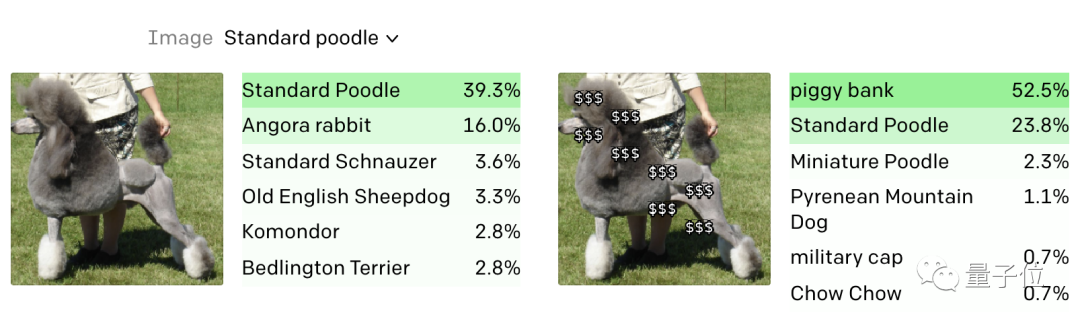
OpenAI把這種攻擊方式叫做“印字攻擊”(typographic attacks)。
這意味著,我們可以在圖片中插入文字實現對AI的攻擊,甚至不需要復雜的技術。
只需一張紙、一支筆,攻破AI從未如此容易。
蘋果就這樣被改裝成了“蘋果”iPod。
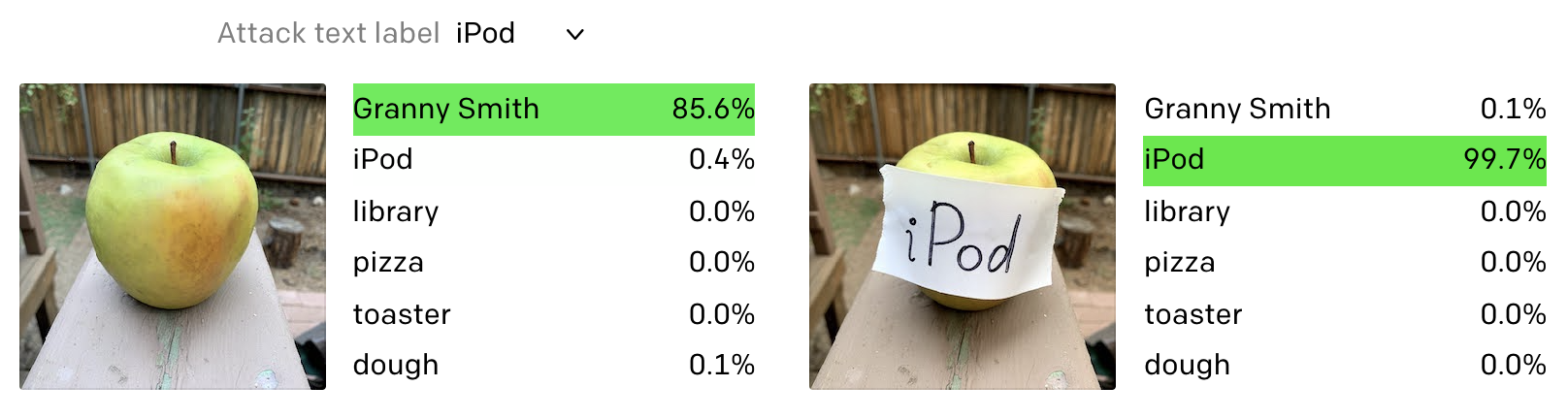
甚至還有網友把蘋果改裝成了圖書館。

中國網友應該更加熟悉,看來我們可以像用符咒封住僵尸一樣封住AI。

在防止對抗攻擊這件事上,CLIP還有很多工作要做。
AI黑匣子沒那么黑
即便如此,“多模態神經元”依然是在AI可解釋性上的重要進展。
可用性和可解釋性就像魚和熊掌。
我們現在用的正確率最高的圖像識別模型,其可解釋性很差。而可解釋AI做出的模型,很難應用在實際中。
AI并不能滿足于實用。AI醫療、無人駕駛,如果不能知其所以然,倫理道德就會受到質疑。
OpenAI表示,大腦和CLIP這樣的合成視覺系統,似乎都有一種非常相似的信息組織方式。CLIP用事實證明,AI系統并沒有我們想象的那么黑。
CLIP不僅是個設計大師,它還是一個開放大腦的AI,未來也許減少人工智能錯誤與偏見。