理解數據類型:每個數據科學愛好者都應該知道的數據結構
本文轉載自公眾號“讀芯術”(ID:AI_Discovery)。
技術快速發展,各種學科中積極使用定量分析,產生了更大量的數據,數據分析的作用已經超過了最初的預期。由于基礎設備不斷進步,現在可以擁有多個數據源,如傳感器、CRMs、事件、文本、圖像、音頻和視頻。
現在的大量數據中,大部分是非結構化的,即沒有預定義模型/結構的數據。如圖像,是像素的集合,文本數據是沒有預定義儲存模型的字符序列,以及用戶在Web應用程序上操作的點擊流。非結構化數據所需要處理的地方在于,需要通過預處理等方法轉化為結構化數據,以便對結構化數據應用統計方法獲取原始數據中的重要信息。
論及結構數據,主要是指表格數據(矩形結構數據),即數據庫中的行和列。這種表格數據包含兩種類型的結構化數據:
1. 數值數據
用數字所衡量表述的數據,進一步分為兩種表示形式:
- 連續型——數據可以表示時間間隔中的任何值,例如汽車的速度、心率等。
- 離散型——只能接受整數值的數據,如計數值。例如,投擲一枚硬幣20次,正面朝上的次數。
2. 分類數據
只能表示可能類別中一組特定的數據。也稱為枚舉、因子或名詞性因子。
- 二進制型,這種分類數據是二進制分類的一種特殊情況,即只有0/1或者說真/假兩個值。
- 有序型,有明確前后順序的分類數據。例如對一家餐館的五星評價制。(1、2、3、4、5)。
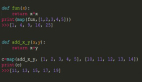
那么問題來了,為什么需要了解這些數據類型呢?因為不知道數據類型,將會不知道如何應用正確的統計方法處理這類數據。舉例來說,如果數據框中有一列有序號數據,就必須要進行預處理,在Python中,scikit-learn包提供了一個序號編碼器來處理序號數據。
下一步是深入研究結構化數據,以及如何使用第三方工具包和庫來操作這些結構。我們主要有兩種類型的結構或數據儲存模型:
- 矩形
- 非矩形
矩形數據
數據科學中大多數的分析對象都是針對二位矩形數據(如數據框、電子表格、CSV文件或是數據庫表格)完成。
矩形數據主要由表示數據類型的行和表示列的變量/特性組成。數據框是一種特殊的數據結構,采用表格格式,提供了高效的數據操作可能。數據框是最常用的數據結構,下方是一些重要的定義:
- 數據框:用于統計和機器學習模型的有效操作和應用的矩形數據結構(如電子表格)。
- 特性:數據框的列值通常被稱為特性。同義詞有(屬性、輸入值、預測值、變量)。
- 結果:許多數據科學項目都涉及到結果預測——通常輸出值yes/no。
- 記錄:數據框中的一行通常被成為記錄。同義詞(實例,模式值,樣本值)。
關系數據庫表將一個或多個指定的列作為索引,本質上是行號查詢。這可以極大程度地提高某些數據庫的查詢效率,在Panda dataframe中,可以根據行的順序自動創建一個整數索引。在Pandas中還可以設置多層次索引提高操作效率。
圖源:unsplash
非矩形數據
除了矩形數據外,還有一些其他的數據結構屬于非矩形數據的范疇。
地理位置分析中使用的空間數據結構更加復雜,不同于矩形數據結構。在地理位置數據中,數據的焦點是一個特定對象(如一個公園)及其空間坐標。相比之下,視場視圖聚焦于小的空間單位和相關的度量值。(如像素強度)。
圖數據結構,這種數據結構通常用來表示數據間的關系——物理關系、社會關系和抽象關系。例如臉書或推特上以社會關系圖的形式表示網絡上人們之間的聯系。圖結構對某些類型的問題特別有用,如網絡優化和系統推薦問題。
每種數據類型在數據科學中都有特殊的處理方法,本文重點講了矩形數據,希望你已經掌握了它。