為了下個(gè)項(xiàng)目的質(zhì)量!每個(gè)數(shù)據(jù)科學(xué)家都應(yīng)該學(xué)會(huì)這兩種工具
本文轉(zhuǎn)載自公眾號(hào)“讀芯術(shù)”(ID:AI_Discovery)。
使用機(jī)器學(xué)習(xí)模型越久,就越能意識(shí)到,正確了解模型當(dāng)下的運(yùn)行目的及效果有多重要。在實(shí)踐中,即便是在最佳情況下,跟蹤模型的運(yùn)行情況(尤其是在測(cè)試各種模型參數(shù)組合時(shí))都十分繁瑣。大多數(shù)情況下,我都會(huì)構(gòu)建自己的工具來(lái)調(diào)試和分析機(jī)器學(xué)習(xí)模型。
最近,在為MAFAT的多普勒脈沖雷達(dá)分類(lèi)挑戰(zhàn)設(shè)計(jì)各種模型的時(shí)候,我發(fā)覺(jué)自己手動(dòng)構(gòu)建模型調(diào)試工具就是在浪費(fèi)時(shí)間,而搭建集成(組合大多數(shù)分類(lèi)策略的機(jī)器學(xué)習(xí)模型,搭對(duì)了就會(huì)帶來(lái)極大效用)時(shí)尤為繁瑣。
創(chuàng)建集成的問(wèn)題就是,各種模型及分類(lèi)都需要讓策略奏效。這就意味著要訓(xùn)練更多的模型、進(jìn)行更多的分析、了解更多關(guān)于整體精度及模型性能的參數(shù)。同樣,這就要求我花更多的時(shí)間創(chuàng)建自己的調(diào)試工具和策略。
為了更好地利用時(shí)間和資源,我決定使用一系列可用的在線(xiàn)工具來(lái)調(diào)試和分析機(jī)器學(xué)習(xí)模型。測(cè)試了幾個(gè)工具后,我成功縮減了清單:開(kāi)發(fā)或改進(jìn)機(jī)器學(xué)習(xí)模型時(shí),每個(gè)數(shù)據(jù)科學(xué)家都應(yīng)考慮這兩個(gè)超贊的工具。
Weights & Biases
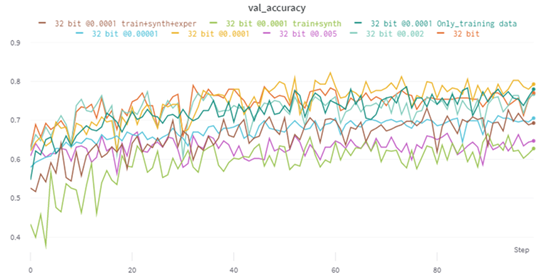
Weights &Biases圖表跟蹤驗(yàn)證集內(nèi)各種具有不同參數(shù)的模型的性能。Y軸表示精度,X軸表示訓(xùn)練回合數(shù)。
Weights & Biases(W&B)是一家總部位于舊金山的公司,提供一系列能無(wú)縫融入現(xiàn)有或新項(xiàng)目的深度學(xué)習(xí)及機(jī)器學(xué)習(xí)工具。它主要是跟蹤項(xiàng)目中模型變化的實(shí)時(shí)性能,簡(jiǎn)直太管用了。
我在做項(xiàng)目時(shí),常常就追蹤問(wèn)題手足無(wú)措:何時(shí)進(jìn)行了哪些更改?這些更改對(duì)項(xiàng)目的各種評(píng)估指標(biāo)是否產(chǎn)生了正面或負(fù)面影響?而W&B能用以多種方式存儲(chǔ)并可視化這些評(píng)估指標(biāo),其中最有效的就是圖表和表格:
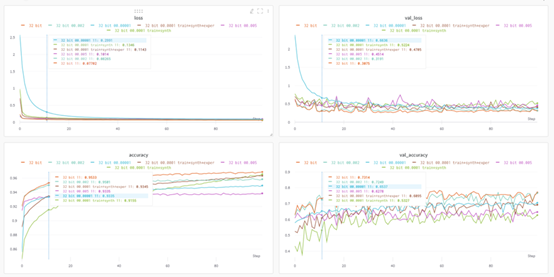
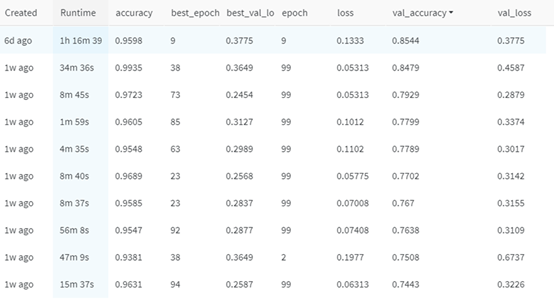
模型數(shù)據(jù)存儲(chǔ)在可導(dǎo)出表格中,以便在W&B網(wǎng)站上進(jìn)行排序和評(píng)估。
如你所見(jiàn),折線(xiàn)圖表示在訓(xùn)練期間使用不同指標(biāo)跟蹤各種模型的性能。這樣便能進(jìn)行無(wú)縫并排比較,以檢查過(guò)擬合或檢查驗(yàn)證集上表現(xiàn)最佳的模型等。
W&B如何與項(xiàng)目關(guān)聯(lián)?
在W&B網(wǎng)站上創(chuàng)建賬戶(hù)后,必須在本地環(huán)境下安裝并登錄到個(gè)人頁(yè)面。
- !pip install --upgrade wandb
- !wandb login <Your login code>
深度學(xué)習(xí)或者機(jī)器學(xué)習(xí)工具不同,情況也可能不同。我用Keras,但其它項(xiàng)目的文檔會(huì)更清晰,也易于執(zhí)行:
- #Import the package
- import wandb
- from wandb.keras import WandbCallback#Initialize the W&B object
- wandb.init(project="tester")#Link the model with W&B’stracking metrics
- model.fit(X_train, y_train, validationData=(X_test, y_test) epochs=config.epochs, callbacks=[WandbCallback()])model.save(os.path.join(wandb.run.dir,"model.h5"))
訓(xùn)練模型時(shí),W&B帳戶(hù)會(huì)實(shí)時(shí)跟蹤和更新進(jìn)度,在賬戶(hù)內(nèi)能輕松分析和評(píng)估模型的性能。在這里,你可以選擇創(chuàng)建報(bào)告,提供更專(zhuān)業(yè)、更易理解的結(jié)果視圖,可以在其中覆蓋文本和其他視覺(jué)效果。
W&B十分有助于跟蹤模型的性能,在更改參數(shù)并嘗試各種技術(shù)時(shí)更是如此。實(shí)際上,這個(gè)說(shuō)法絕不夸張。它確實(shí)能幫上大忙:OpenAI和Toyota Research這樣的大公司定期使用它,稱(chēng)贊它是靈活且有效用的項(xiàng)目工具。
Uber的Manifold
圖源:unsplash
我正在項(xiàng)目中創(chuàng)建集成。一個(gè)集成是不同算法的集合,每個(gè)算法就同一數(shù)據(jù)進(jìn)行訓(xùn)練并提供預(yù)測(cè)。集成的優(yōu)勢(shì)在于,它提供了一系列不同的策略來(lái)尋找解決方案,并利用多數(shù)票使所有模型的分類(lèi)民主化。這很有用,因?yàn)楸M管單個(gè)模型可以很好地預(yù)測(cè)部分?jǐn)?shù)據(jù),但它可能會(huì)在其他部分不知所措。
在機(jī)器學(xué)習(xí)中,“集成就是數(shù)字力量”。為了讓集成表現(xiàn)良好,組成集成的各個(gè)模型必須能進(jìn)行多樣化預(yù)測(cè)。多樣化預(yù)測(cè),即不能所有模型都對(duì)某數(shù)據(jù)進(jìn)行一模一樣的預(yù)測(cè);它們應(yīng)該能對(duì)不同數(shù)據(jù)進(jìn)行準(zhǔn)確預(yù)測(cè)。然而這也帶來(lái)了問(wèn)題:你怎么知道集成進(jìn)行的是多樣化預(yù)測(cè)呢?看看交通科技巨頭Uber的Manifold吧。
Uber的Manifold是個(gè)開(kāi)源長(zhǎng)期項(xiàng)目,旨在為機(jī)器學(xué)習(xí)提供調(diào)試的可視化工具(模型是什么樣子的都無(wú)所謂)。通俗地講,Manifold讓你能看見(jiàn)哪個(gè)模型在數(shù)據(jù)子集中表現(xiàn)不佳、哪些特性導(dǎo)致了表現(xiàn)不佳。
集成能幫大忙。它創(chuàng)建了一個(gè)Widget輸出,在Notebook就能交互以進(jìn)行快速分析。注意,該工具目前僅在經(jīng)典的Jupyter Notebook電腦上可用。它在Jupyter Lab或Google的Colab上不能運(yùn)行。
Manifold使用k均值聚類(lèi)——一種鄰近分組技術(shù),將預(yù)測(cè)數(shù)據(jù)分為性能相似的片段。想象一下,這是將數(shù)據(jù)分成相似的子類(lèi),然后沿著每個(gè)分段繪制模型,其中模型越靠左,則在該分段上表現(xiàn)越好。隨機(jī)生成的示例中可以看到這一點(diǎn):
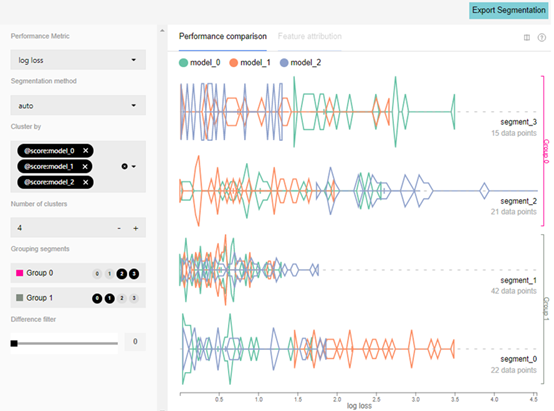
上述例子中有三個(gè)模型,輸入數(shù)據(jù)被分成四段。把對(duì)數(shù)損失(log-loss)作為性能指標(biāo),可以看到model_1在segment_0上的表現(xiàn)不佳,而model_2在segment_2上的表現(xiàn)不佳。線(xiàn)的形狀表示性能分布,線(xiàn)的高度表示對(duì)數(shù)損失下的相對(duì)數(shù)據(jù)點(diǎn)計(jì)數(shù)。例如,在segment_1的model_1上,對(duì)數(shù)損失為1.5,點(diǎn)的均值低,但十分密集。
Manifold還提供了功能歸因視圖:
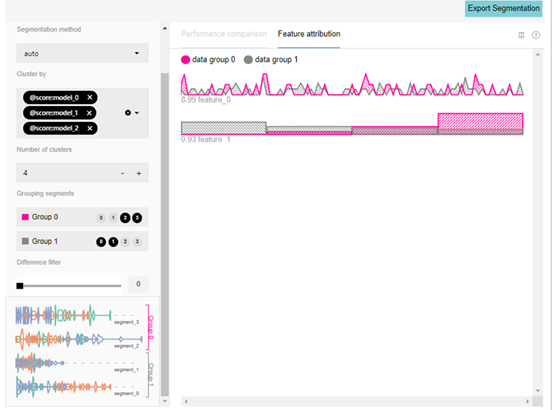
功能歸因視圖強(qiáng)調(diào)每個(gè)片段的功能分布。在上面的示例中,數(shù)據(jù)組0包含聚類(lèi)2和3,將其與包含聚類(lèi)0和1的數(shù)據(jù)組1進(jìn)行比較。x軸是特征值,而y軸是原因的強(qiáng)度。Feature_0高亮顯示這些差異,而Feature_1高亮顯示特征值的直方圖。
那么,如何把Manifold融入項(xiàng)目?
Manifold還處在早期研發(fā)階段,還得繼續(xù)調(diào)bug。但是,這不該妨礙你在項(xiàng)目中使用它。就個(gè)人情況來(lái)說(shuō),我需要弄幾個(gè)安裝包才能在Jupyter Notebook上運(yùn)行它。
- !jupyter nbextension install --py --sys-prefix widgetsnbextension
- !jupyter nbextension enable --py --sys-prefix widgetsnbextension
- !pip install mlvis!jupyter nbextension install --py --symlink --sys-prefix mlvis
- !jupyter nbextension enable --py --sys-prefix mlvis
僅僅安裝nbextention包是不夠的,我還必須啟用這些軟件包。可以在這里導(dǎo)入一些demo工具:
- from mlvis import Manifold
- import sys, json, mathfrom random import uniform
要使用Manifold框架,數(shù)據(jù)需要分成三組特定格式。第一組是所有必須在字典列表中的x值:
- #Example of x-values
- x = [
- {'feature_0': 21, 'feature_1': 'B'},
- {'feature_0': 36, 'feature_1': 'A'}
- ]
第二組是不同的模型預(yù)測(cè),它必須是列表的列表,每個(gè)列表都是不同模型的預(yù)測(cè):
- #Example of model predictions
- yPred = [
- [{'false': 0.1, 'true': 0.9}, {'false':0.8, 'true': 0.2}],
- [{'false': 0.3, 'true': 0.7}, {'false':0.9, 'true': 0.1}],
- [{'false': 0.6, 'true': 0.4}, {'false':0.4, 'true': 0.6}]
- ]
最后一組是ground truth值或?qū)嶋H正確的y值,它們?cè)诹斜碇抵校?/p>
- #Example of ground truth
- yTrue = [
- 'true', 'false'
- ]
數(shù)據(jù)一旦采用這種格式,值就可以輸入到Manifold對(duì)象中,操作進(jìn)行Widget,有些類(lèi)似于上面的例子:
- Manifold(props={'data': {
- 'x': x,
- 'yPred': yPred,
- 'yTrue': yTrue
- }})
然后使用Manifold就能直觀(guān)地評(píng)估不同模型對(duì)相同數(shù)據(jù)的表現(xiàn)了。這對(duì)于構(gòu)建集成非常有幫助,因?yàn)樗刮夷軌蛄私饽男┠P驮谀睦飯?zhí)行,哪些數(shù)據(jù)集群是模型最難分類(lèi)的。Manifold同樣幫我評(píng)估了集成中每個(gè)模型的預(yù)測(cè)多樣性,使我能構(gòu)建一個(gè)更強(qiáng)大、能分類(lèi)一系列不同輸入數(shù)據(jù)的設(shè)備。
圖源:unsplash
對(duì)我來(lái)說(shuō),上述兩種工具真的是越來(lái)越有用了。它們可以幫我應(yīng)對(duì)這一挑戰(zhàn)并切實(shí)改善設(shè)備的性能,希望讀者也能用這些工具來(lái)創(chuàng)建更好的模型。