通用爬蟲技術要點: Dom樹的重建
這個問題來自于讀者交流群。原問題如下圖所示:

這個問題在通用爬蟲的開發過程中確實會涉及到。因為網頁的HTML 結構千變萬化,但是,通用爬蟲需要在不預先知道目標網頁結構的情況下對其中的內容進行提取。
這種情況下,通用爬蟲一般會分成幾個不同的部分,如下圖所示:
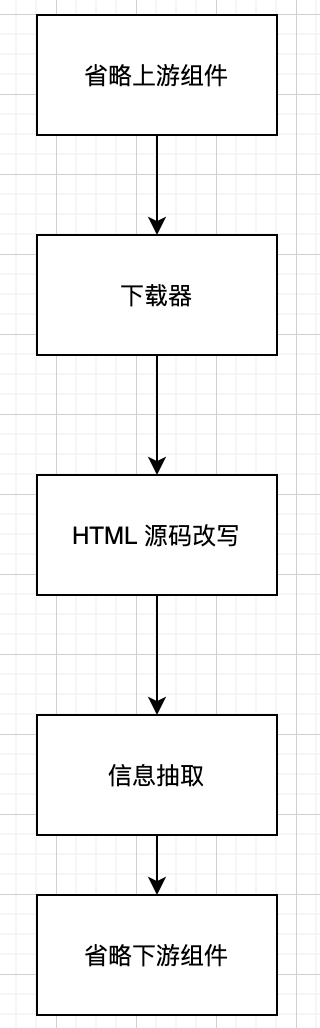
其中,HTML 源碼改寫這一個組件,會根據一定的策略對網頁源代碼進行修改,剔除無關的節點,合并復雜但沒有必要的嵌套節點……改寫以后,輸出相對標準和統一的 HTML,傳給下游的信息抽取組件進行內容抽取。
這位同學的問題,就涉及到對源代碼進行改寫。實際上,使用 lxml 在 DOM 樹中插入一個節點,這本來根本不是什么問題。任何一個會使用 Google 的同學,只要搜索lxml html insert element,自然就能找到大量的解決方法,如下圖所示:
但是,這個問題怪就怪在,它需要在文本節點的前面增加子節點。干講可能不好描述,我用一個例子來說明這個問題。
大家先來看這段代碼:
- from lxml.html import fromstring, Element, etree
- from html import unescape
- html = '''
- <div>
- <p>你好</p>
- </div>
- '''
- node = fromstring(html)
- p_node = node.find('.//p')
- element = Element('span')
- element.text = '青南'
- p_node.insert(0, element)
- new_html = unescape(etree.tostring(node).decode())
- print(new_html)
根據我們使用 Python 列表的經驗,如果一個列表a現在是['你好'],當我們執行a.insert(0, '青南')以后,得到的結果應該是['青南', '你好']。但是我們來看看上面這段代碼的運行效果:
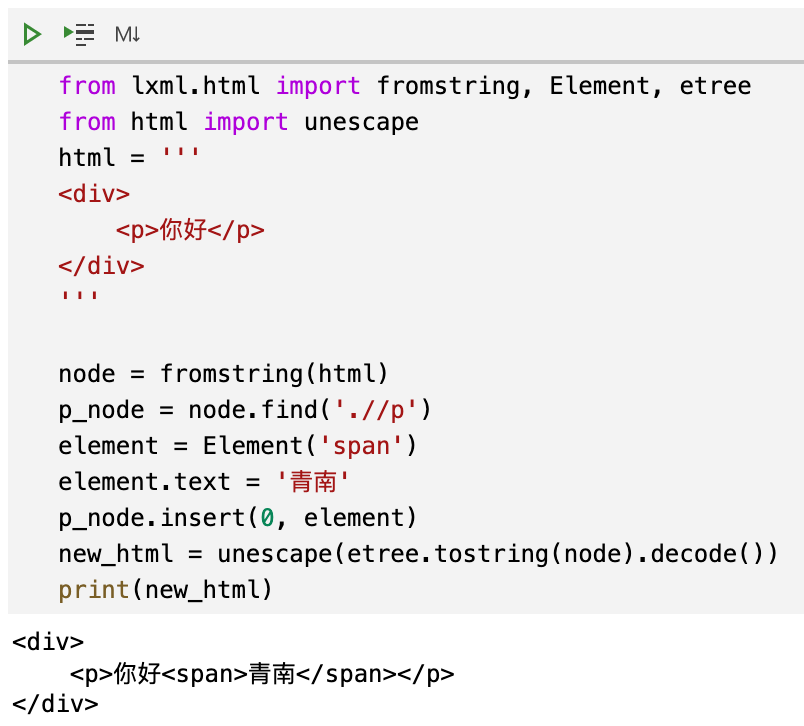
可以看到,青南是在你好后面的。大家再看本文最開頭的圖,提問者舉出的例子中,他希望把子節點插入到文本之前。具體到這個例子中,應該是青南你好。
大家可以試一試,你在 Google 上面無論怎么搜索,都找不到如何把節點插入到文本前面的方法。
但實際上,只要回歸官方文檔,你就會發現整個問題的解決方法并不困難。我們需要使用的,是lxml.html.builder[1]。
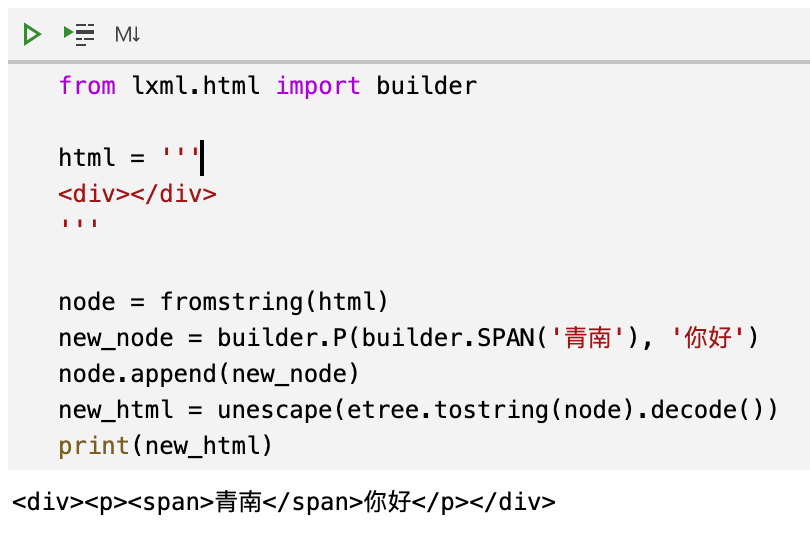
還是上面的例子,如何把 span 標簽弄到文本前面呢?我們用 builder來實現:
- from lxml.html import builder
- from html import unescape
- html = '''
- <div></div>
- '''
- node = fromstring(html)
- new_node = builder.P(builder.SPAN('青南'), '你好')
- node.append(new_node)
- new_html = unescape(etree.tostring(node).decode())
- print(new_html)
運行效果如下圖所示:
看到這里,可能有同學會覺得我在耍無賴。這就像是讓我寫一個程序,計算斐波那契數列前5項的值,于是我5秒鐘寫出了答案print(1, 1, 2, 3, 5)。上面的代碼中,我直接使用builder.P(builder.SPAN('青南'), '你好'),這跟直接寫<p><span>青南</span>你好</p>有什么區別?這不是在作弊嗎?
我知道你很不服氣,但是,這就是真實的情況。通用爬蟲在做 HTML源碼改寫的時候,就是這樣做的。因為直接對網頁的 Dom 樹進行改寫是非常麻煩的事情。如果直接修改 Dom 樹,經常會出現需要找一個節點的父節點,然后再找父節點的兄弟節點的子節點進行修改。或者要判斷某個節點是否有子節點,有和沒有,需要兩種邏輯來處理,才能防止破壞 Dom 樹。
所以,我們一般不會直接修改 Dom 樹,而是一邊掃描原始的 Dom 樹,一邊使用 builder 重建一個新的 Dom 樹。重建 Dom 樹的過程比修改 Dom 樹的過程要簡單很多,畢竟寫過代碼的人都知道,寫新代碼比改別人的代碼容易很多。
參考資料
[1]lxml.html.builder: https://lxml.de/api/lxml.html.builder-module.html
本文轉載自微信公眾號「未聞Code」,可以通過以下二維碼關注。轉載本文請聯系未聞Code公眾號。