Python爬蟲抓取技術(shù)的門道
web是一個(gè)開放的平臺(tái),這也奠定了web從90年代初誕生直至今日將近30年來(lái)蓬勃的發(fā)展。然而,正所謂成也蕭何敗也蕭何,開放的特性、搜索引擎以及簡(jiǎn)單易學(xué)的html、css技術(shù)使得web成為了互聯(lián)網(wǎng)領(lǐng)域里最為流行和成熟的信息傳播媒介;但如今作為商業(yè)化軟件,web這個(gè)平臺(tái)上的內(nèi)容信息的版權(quán)卻毫無(wú)保證,因?yàn)橄啾溶浖蛻舳硕裕愕木W(wǎng)頁(yè)中的內(nèi)容可以被很低成本、很低的技術(shù)門檻實(shí)現(xiàn)出的一些抓取程序獲取到,這也就是這一系列文章將要探討的話題—— 網(wǎng)絡(luò)爬蟲 。
有很多人認(rèn)為web應(yīng)當(dāng)始終遵循開放的精神,呈現(xiàn)在頁(yè)面中的信息應(yīng)當(dāng)毫無(wú)保留地分享給整個(gè)互聯(lián)網(wǎng)。然而我認(rèn)為,在IT行業(yè)發(fā)展至今天,web已經(jīng)不再是當(dāng)年那個(gè)和pdf一爭(zhēng)高下的所謂 “超文本”信息載體 了,它已經(jīng)是以一種 輕量級(jí)客戶端軟件 的意識(shí)形態(tài)的存在了。而商業(yè)軟件發(fā)展到今天,web也不得不面對(duì)知識(shí)產(chǎn)權(quán)保護(hù)的問(wèn)題,試想如果原創(chuàng)的高質(zhì)量?jī)?nèi)容得不到保護(hù),抄襲和盜版橫行網(wǎng)絡(luò)世界,這其實(shí)對(duì)web生態(tài)的良性發(fā)展是不利的,也很難鼓勵(lì)更多的優(yōu)質(zhì)原創(chuàng)內(nèi)容的生產(chǎn)。
未授權(quán)的爬蟲抓取程序是危害web原創(chuàng)內(nèi)容生態(tài)的一大元兇,因此要保護(hù)網(wǎng)站的內(nèi)容,首先就要考慮如何反爬蟲。
從爬蟲的攻防角度來(lái)講
最簡(jiǎn)單的爬蟲,是幾乎所有服務(wù)端、客戶端編程語(yǔ)言都支持的http請(qǐng)求,只要向目標(biāo)頁(yè)面的url發(fā)起一個(gè)http get請(qǐng)求,即可獲得到瀏覽器加載這個(gè)頁(yè)面時(shí)的完整html文檔,這被我們稱之為“同步頁(yè)”。
作為防守的一方,服務(wù)端可以根據(jù)http請(qǐng)求頭中的User-Agent來(lái)檢查客戶端是否是一個(gè)合法的瀏覽器程序,亦或是一個(gè)腳本編寫的抓取程序,從而決定是否將真實(shí)的頁(yè)面信息內(nèi)容下發(fā)給你。
這當(dāng)然是最小兒科的防御手段,爬蟲作為進(jìn)攻的一方,完全可以偽造User-Agent字段,甚至,只要你愿意,http的get方法里, request header的 Referrer 、 Cookie 等等所有字段爬蟲都可以輕而易舉的偽造。
此時(shí)服務(wù)端可以利用瀏覽器http頭指紋,根據(jù)你聲明的自己的瀏覽器廠商和版本(來(lái)自 User-Agent ),來(lái)鑒別你的http header中的各個(gè)字段是否符合該瀏覽器的特征,如不符合則作為爬蟲程序?qū)Υ_@個(gè)技術(shù)有一個(gè)典型的應(yīng)用,就是 PhantomJS 1.x版本中,由于其底層調(diào)用了Qt框架的網(wǎng)絡(luò)庫(kù),因此http頭里有明顯的Qt框架網(wǎng)絡(luò)請(qǐng)求的特征,可以被服務(wù)端直接識(shí)別并攔截。
除此之外,還有一種更加變態(tài)的服務(wù)端爬蟲檢測(cè)機(jī)制,就是對(duì)所有訪問(wèn)頁(yè)面的http請(qǐng)求,在 http response 中種下一個(gè) cookie token ,然后在這個(gè)頁(yè)面內(nèi)異步執(zhí)行的一些ajax接口里去校驗(yàn)來(lái)訪請(qǐng)求是否含有cookie token,將token回傳回來(lái)則表明這是一個(gè)合法的瀏覽器來(lái)訪,否則說(shuō)明剛剛被下發(fā)了那個(gè)token的用戶訪問(wèn)了頁(yè)面html卻沒有訪問(wèn)html內(nèi)執(zhí)行js后調(diào)用的ajax請(qǐng)求,很有可能是一個(gè)爬蟲程序。
如果你不攜帶token直接訪問(wèn)一個(gè)接口,這也就意味著你沒請(qǐng)求過(guò)html頁(yè)面直接向本應(yīng)由頁(yè)面內(nèi)ajax訪問(wèn)的接口發(fā)起了網(wǎng)絡(luò)請(qǐng)求,這也顯然證明了你是一個(gè)可疑的爬蟲。知名電商網(wǎng)站Amazon就是采用的這種防御策略。
以上則是基于服務(wù)端校驗(yàn)爬蟲程序,可以玩出的一些套路手段。
基于客戶端js運(yùn)行時(shí)的檢測(cè)
現(xiàn)代瀏覽器賦予了JavaScript強(qiáng)大的能力,因此我們可以把頁(yè)面的所有核心內(nèi)容都做成js異步請(qǐng)求 ajax 獲取數(shù)據(jù)后渲染在頁(yè)面中的,這顯然提高了爬蟲抓取內(nèi)容的門檻。依靠這種方式,我們把對(duì)抓取與反抓取的對(duì)抗戰(zhàn)場(chǎng)從服務(wù)端轉(zhuǎn)移到了客戶端瀏覽器中的js運(yùn)行時(shí),接下來(lái)說(shuō)一說(shuō)結(jié)合客戶端js運(yùn)行時(shí)的爬蟲抓取技術(shù)。
剛剛談到的各種服務(wù)端校驗(yàn),對(duì)于普通的python、java語(yǔ)言編寫的http抓取程序而言,具有一定的技術(shù)門檻,畢竟一個(gè)web應(yīng)用對(duì)于未授權(quán)抓取者而言是黑盒的,很多東西需要一點(diǎn)一點(diǎn)去嘗試,而花費(fèi)大量人力物力開發(fā)好的一套抓取程序,web站作為防守一方只要輕易調(diào)整一些策略,攻擊者就需要再次花費(fèi)同等的時(shí)間去修改爬蟲抓取邏輯。
此時(shí)就需要使用headless browser了,這是什么技術(shù)呢?其實(shí)說(shuō)白了就是,讓程序可以操作瀏覽器去訪問(wèn)網(wǎng)頁(yè),這樣編寫爬蟲的人可以通過(guò)調(diào)用瀏覽器暴露出來(lái)給程序調(diào)用的api去實(shí)現(xiàn)復(fù)雜的抓取業(yè)務(wù)邏輯。
其實(shí)近年來(lái)這已經(jīng)不算是什么新鮮的技術(shù)了,從前有基于webkit內(nèi)核的PhantomJS,基于Firefox瀏覽器內(nèi)核的SlimerJS,甚至基于IE內(nèi)核的trifleJS,有興趣可以看看這里和這里 是兩個(gè)headless browser的收集列表。
這些headless browser程序?qū)崿F(xiàn)的原理其實(shí)是把開源的一些瀏覽器內(nèi)核C++代碼加以改造和封裝,實(shí)現(xiàn)一個(gè)簡(jiǎn)易的無(wú)GUI界面渲染的browser程序。但這些項(xiàng)目普遍存在的問(wèn)題是,由于他們的代碼基于fork官方webkit等內(nèi)核的某一個(gè)版本的主干代碼,因此無(wú)法跟進(jìn)一些新的css屬性和js語(yǔ)法,并且存在一些兼容性的問(wèn)題,不如真正的release版GUI瀏覽器運(yùn)行得穩(wěn)定。
這其中最為成熟、使用率高的應(yīng)該當(dāng)屬 PhantonJS 了,對(duì)這種爬蟲的識(shí)別我之前曾寫過(guò)一篇博客,這里不再贅述。PhantomJS存在諸多問(wèn)題,因?yàn)槭菃芜M(jìn)程模型,沒有必要的沙箱保護(hù),瀏覽器內(nèi)核的安全性較差。另外,該項(xiàng)目作者已經(jīng)聲明停止維護(hù)此項(xiàng)目了。
如今Google Chrome團(tuán)隊(duì)在Chrome 59 release版本中開放了headless mode api,并開源了一個(gè)基于Node.js調(diào)用的headless chromium dirver庫(kù),我也為這個(gè)庫(kù)貢獻(xiàn)了一個(gè)centos環(huán)境的部署依賴安裝列表。
Headless Chrome可謂是Headless Browser中獨(dú)樹一幟的大殺器,由于其自身就是一個(gè)chrome瀏覽器,因此支持各種新的css渲染特性和js運(yùn)行時(shí)語(yǔ)法。
基于這樣的手段,爬蟲作為進(jìn)攻的一方可以繞過(guò)幾乎所有服務(wù)端校驗(yàn)邏輯,但是這些爬蟲在客戶端的js運(yùn)行時(shí)中依然存在著一些破綻,諸如:
基于plugin對(duì)象的檢查
- if(navigator.plugins.length === 0) {
- console.log('It may be Chrome headless');
- }
基于language的檢查
- if(navigator.languages === '') {
- console.log('Chrome headless detected');
- }
基于webgl的檢查
- var canvas = document.createElement('canvas');
- var gl = canvas.getContext('webgl');
- var debugInfo = gl.getExtension('WEBGL_debug_renderer_info');
- var vendor = gl.getParameter(debugInfo.UNMASKED_VENDOR_WEBGL);
- var renderer = gl.getParameter(debugInfo.UNMASKED_RENDERER_WEBGL);
- if(vendor == 'Brian Paul' && renderer == 'Mesa OffScreen') {
- console.log('Chrome headless detected');
- }
基于瀏覽器hairline特性的檢查
- if(!Modernizr['hairline']) {
- console.log('It may be Chrome headless');
- }
基于錯(cuò)誤img src屬性生成的img對(duì)象的檢查
- var body = document.getElementsByTagName('body')[0];
- var image = document.createElement('img');
- image.src = 'http://iloveponeydotcom32188.jg';
- image.setAttribute('id', 'fakeimage');
- body.appendChild(image);
- image.onerror = function(){
- if(image.width == 0 && image.height == 0) {
- console.log('Chrome headless detected');
- }
- }
基于以上的一些瀏覽器特性的判斷,基本可以通殺市面上大多數(shù) Headless Browser 程序。在這一層面上,實(shí)際上是將網(wǎng)頁(yè)抓取的門檻提高,要求編寫爬蟲程序的開發(fā)者不得不修改瀏覽器內(nèi)核的C++代碼,重新編譯一個(gè)瀏覽器,并且,以上幾點(diǎn)特征是對(duì)瀏覽器內(nèi)核的改動(dòng)其實(shí)并不小,如果你曾嘗試過(guò)編譯Blink內(nèi)核或Gecko內(nèi)核你會(huì)明白這對(duì)于一個(gè)“腳本小子”來(lái)說(shuō)有多難~
更進(jìn)一步,我們還可以基于瀏覽器的 UserAgent 字段描述的瀏覽器品牌、版本型號(hào)信息,對(duì)js運(yùn)行時(shí)、DOM和BOM的各個(gè)原生對(duì)象的屬性及方法進(jìn)行檢驗(yàn),觀察其特征是否符合該版本的瀏覽器所應(yīng)具備的特征。
這種方式被稱為 瀏覽器指紋檢查 技術(shù),依托于大型web站對(duì)各型號(hào)瀏覽器api信息的收集。而作為編寫爬蟲程序的進(jìn)攻一方,則可以在 Headless Browser 運(yùn)行時(shí)里預(yù)注入一些js邏輯,偽造瀏覽器的特征。
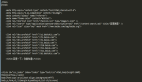
另外,在研究瀏覽器端利用js api進(jìn)行 Robots Browser Detect 時(shí),我們發(fā)現(xiàn)了一個(gè)有趣的小技巧,你可以把一個(gè)預(yù)注入的js函數(shù),偽裝成一個(gè)Native Function,來(lái)看看下面代碼:
- var fakeAlert = (function(){}).bind(null);
- console.log(window.alert.toString()); // function alert() { [native code] }
- console.log(fakeAlert.toString()); // function () { [native code] }
爬蟲進(jìn)攻方可能會(huì)預(yù)注入一些js方法,把原生的一些api外面包裝一層proxy function作為hook,然后再用這個(gè)假的js api去覆蓋原生api。如果防御者在對(duì)此做檢查判斷時(shí)是基于把函數(shù)toString之后對(duì)[native code]的檢查,那么就會(huì)被繞過(guò)。所以需要更嚴(yán)格的檢查,因?yàn)閎ind(null)偽造的方法,在toString之后是不帶函數(shù)名的,因此你需要在toString之后檢查函數(shù)名是否為空。
這個(gè)技巧有什么用呢?這里延伸一下,反抓取的防御者有一種Robot Detect的辦法是在js運(yùn)行時(shí)主動(dòng)拋出一個(gè)alert,文案可以寫一些與業(yè)務(wù)邏輯相關(guān)的,正常的用戶點(diǎn)確定按鈕時(shí)必定會(huì)有一個(gè)1s甚至更長(zhǎng)的延時(shí),由于瀏覽器里alert會(huì)阻塞js代碼運(yùn)行(實(shí)際上在v8里他會(huì)把這個(gè)isolate上下文以類似進(jìn)程掛起的方式暫停執(zhí)行),所以爬蟲程序作為攻擊者可以選擇以上面的技巧在頁(yè)面所有js運(yùn)行以前預(yù)注入一段js代碼,把a(bǔ)lert、prompt、confirm等彈窗方法全部hook偽造。如果防御者在彈窗代碼之前先檢驗(yàn)下自己調(diào)用的alert方法還是不是原生的,這條路就被封死了。
反爬蟲的銀彈
目前的反抓取、機(jī)器人檢查手段,最可靠的還是驗(yàn)證碼技術(shù)。但驗(yàn)證碼并不意味著一定要強(qiáng)迫用戶輸入一連串字母數(shù)字,也有很多基于用戶鼠標(biāo)、觸屏(移動(dòng)端)等行為的行為驗(yàn)證技術(shù),這其中最為成熟的當(dāng)屬Google reCAPTCHA,基于機(jī)器學(xué)習(xí)的方式對(duì)用戶與爬蟲進(jìn)行區(qū)分。
基于以上諸多對(duì)用戶與爬蟲的識(shí)別區(qū)分技術(shù),網(wǎng)站的防御方最終要做的是封禁ip地址或是對(duì)這個(gè)ip的來(lái)訪用戶施以高強(qiáng)度的驗(yàn)證碼策略。這樣一來(lái),進(jìn)攻方不得不購(gòu)買ip代理池來(lái)抓取網(wǎng)站信息內(nèi)容,否則單個(gè)ip地址很容易被封導(dǎo)致無(wú)法抓取。抓取與反抓取的門檻被提高到了ip代理池經(jīng)濟(jì)費(fèi)用的層面。
機(jī)器人協(xié)議
除此之外,在爬蟲抓取技術(shù)領(lǐng)域還有一個(gè)“白道”的手段,叫做robots協(xié)議。Allow和Disallow聲明了對(duì)各個(gè)UA爬蟲的抓取授權(quán)。
不過(guò),這只是一個(gè)君子協(xié)議,雖具有法律效益,但只能夠限制那些商業(yè)搜索引擎的蜘蛛程序,你無(wú)法對(duì)那些“野爬愛好者”加以限制。
寫在最后
對(duì)網(wǎng)頁(yè)內(nèi)容的抓取與反制,注定是一個(gè)魔高一尺道高一丈的貓鼠游戲,你永遠(yuǎn)不可能以某一種技術(shù)徹底封死爬蟲程序的路,你能做的只是提高攻擊者的抓取成本,并對(duì)于未授權(quán)的抓取行為做到較為精確的獲悉。