













通用爬蟲技術:如何正確從 URL 中移除無效參數

我們知道,URL 由下面幾個部分組成:

其中Query部分,中文叫做查詢參數。它在 URL 中,是由等號連接的鍵值對。這些鍵值對有一些是有效的,例如:
- https://open.163.com/newview/movie/courseintro?newurl=MDAPTVFE8
這個網址中的newurl=MDAPTVFE8是不能修改的,一旦你改了,那就不再是這個頁面了。
但還有一些網址,他們的查詢參數對網頁的顯示沒有任何影響,例如下面兩個網址:
- https://www.163.com/dy/article/G7NINAJS0514HDK6.html?from=nav
- https://www.163.com/dy/article/G7NINAJS0514HDK6.html
當你訪問這兩個網址,你會發現它們打開的是同一個頁面。因為這些參數是給網站用的。網站使用這些參數來統計用戶是從哪個頁面跳轉到這個頁面的。
在我們開發新聞通用爬蟲的時候,這種可有可無的查詢參數會對基于 URL 的去重導致嚴重干擾。同一篇新聞,可能因為從不同的頁面跳轉過來,就有不同的查詢參數,那么就可能會被當做多篇不同的新聞。
我們在對新聞進行去重的時候,一般會有一個三級去重邏輯:基于 URL 去重,基于新聞正文文字去重,基于正文語義去重。他們對資源的消耗逐漸增加,因此,如果能通過 URL 確認是重復的新聞,就沒有必要經過文本去重;能夠經過文本確認是重復的新聞,就沒有必要使用語義去重。這種無效的參數,會導致進入第二級的新聞數量增加,從而消耗更多的服務器資源。
為了防止這種無效的參數干擾基于 URL 去重的邏輯,因此我們需要提前移除無效的 URL 參數。
假設現在有一個網址:https://www.kingname.info/article?docid=123&from=nav&output=json&ts=1849304323。我們通過人工標注,已經知道,對于https://www.kingname.info這個網站,docid和output參數是有效參數,必須保留;from和ts參數是無效參數,可以移除。那么,我們如何正確移除這些不需要的參數字段呢?
肯定有同學會說使用正則表達式來移除。那么你可以試一試,正則表達式應該怎么寫。提示一下,有一些參數值里面也會有=符號、有一些必要字段的值,可能恰好包含無效字段的名字。
今天,我們不使用正則表達式,而使用 Python 自帶的 urllib 模塊中的幾個函數來實現安全完美的移除無效字段的方法。
這個方法,需要使用到urlparse parse_qs urlencode和urlunparse。我們來看一段代碼:
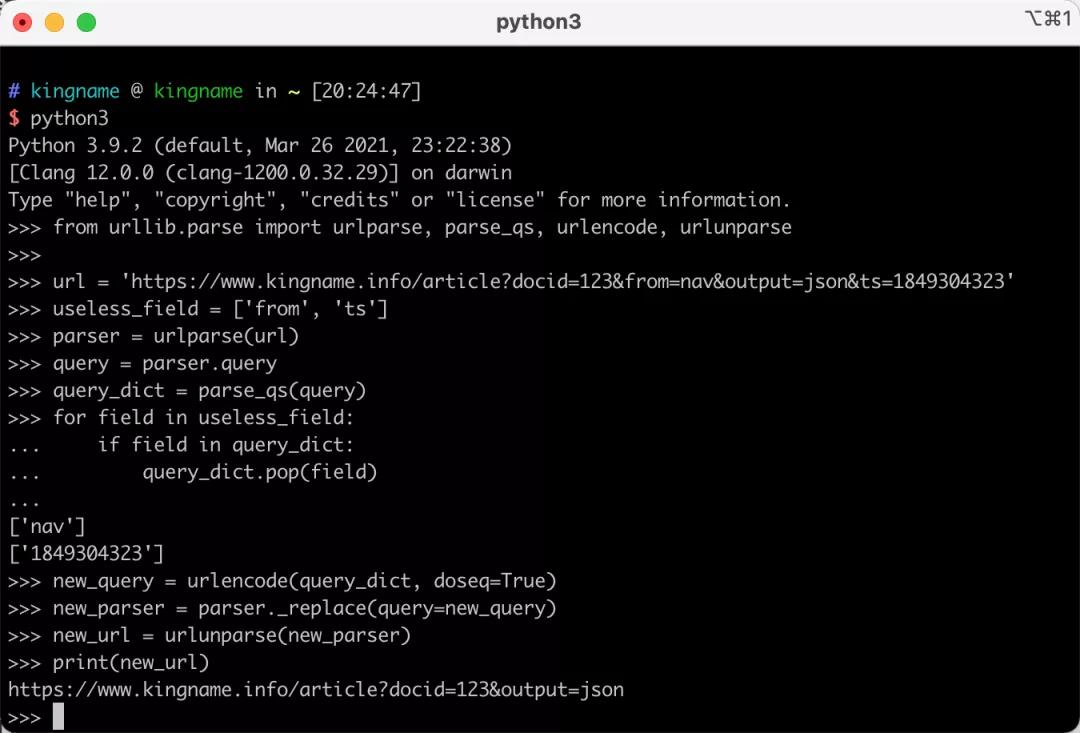
- from urllib.parse import urlparse, parse_qs, urlencode, urlunparse
- url = 'https://www.kingname.info/article?docid=123&from=nav&output=json&ts=1849304323'
- useless_field = ['from', 'ts']
- parser = urlparse(url)
- query = parser.query
- query_dict = parse_qs(query)
- for field in useless_field:
- if field in query_dict:
- query_dict.pop(field)
- new_query = urlencode(query_dict, doseq=True)
- new_parser = parser._replace(query=new_query)
- new_url = urlunparse(new_parser)
- print(new_url)
運行效果如下圖所示:
其中urlparse和urlunparse是一對相反的函數,其中前者把網址轉成ParseResult對象,后者把ParseResult對象轉回網址字符串。
ParseResult對象的.query屬性,是一個字符串,格式如下:

parse_qs與urlencode也是一對相反的方法。其中前者把 .query輸出的字符串轉成字典,而后者把字段轉成.query形式的字符串:
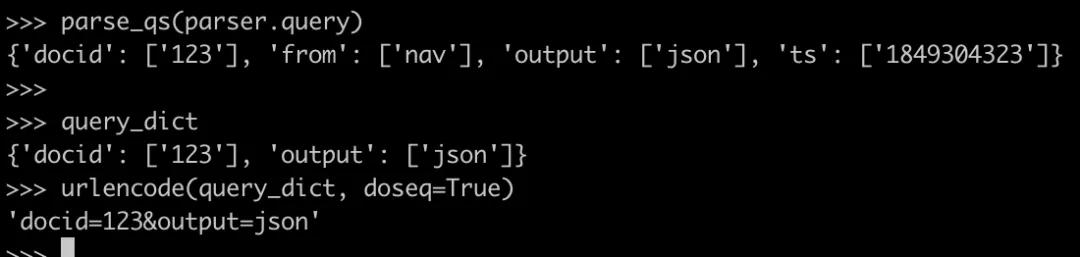
當我們使用parse_qs把 query轉成字典以后,就可以使用字典的.pop方法,把無效的字段都移除,然后重新生成新的.query字符串。
由于ParseResult對象的.query屬性是只讀屬性,不能覆蓋,因此我們需要調用一個內部方法parser._replace把新的.query字段替換上去,生成新的 ParseResult對象。最后再把它轉回網址。
使用這個方法,我們就可以安全地從 URL 中移除無效字段,而不用去寫復雜的正則表達式了。
本文轉載自微信公眾號「未聞Code」,可以通過以下二維碼關注。轉載本文請聯系未聞Code公眾號。



















