每個人都應該知道的3種機器學習算法
假設有一些跟數據相關的難題需要你去解決。之前你已經聽過機器學習算法的厲害之處了,因此你自己也想借此機會嘗試一番——但是你在這個領域并沒有經驗或知識。于是你開始用谷歌搜索一些術語,比如“機器學習模型”和“機器學習方法”,但一段時間后,你發現自己在不同算法之間已經完全迷失了,所以便開始放棄了。
堅持才能勝利!
幸運的是,我將在本文介紹三個主要的機器學習算法,了解了這些內容后,我相信針對于大多數的數據科學難題,你都可以滿懷自信去解決。
在下面的文章中,我們將討論決策樹、聚類算法和回歸,指出它們之間的差異,并找出如何根據不同的案例選擇最合適的模型。
有監督學習 VS 無監督學習
理解機器學習的基礎就是如何對有監督學習和無監督學習這兩個大類進行分類的問題,因為機器學習問題中的任何一個問題最終都是這兩個大類中的某一個。
在有監督學習的情況下,我們有數據集,某些算法會將這些數據集作為輸入。前提是我們已經知道正確的輸出格式應該是什么樣子(假設輸入和輸出之間存在某種關系)。
稍后我們看到的回歸和分類問題都是屬于這一類。
另一方面,無監督學習適用于我們不確定或者不知道正確的輸出應該是什么樣子的情況。事實上,我們需要根據數據推導出正確的結構應該是什么樣。聚類問題是該類的主要代表。
為了使上述分類更加清晰,我將列舉一些現實世界的問題,并嘗試對它們進行相應的分類。
實例1
假設你在經營一家房地產公司。考慮到新房子的特點,你想基于之前記錄的其他房子的銷售情況,從而預測這間房屋的銷售價格應該在什么價位。輸入的數據集包含多個房子的特征,比如浴室的數量和大小,而你想要預測的變量,通常稱為目標變量,在本例子中也就是價格。因為已經知道了數據集中房子的出售價格,因此這是一個有監督學習的問題,說的更具體一點,這是一個關于回歸的問題。
實例2
假設你做了一項實驗,根據某些物理測量結果以及遺傳因素,來推斷某人是否會發展成為近視眼。在這種情況下,輸入的數據集是由人體醫學特征組成的,目標變量是雙重的:1表示那些可能發展近視的人,0表示沒有成為近視眼的人。由于已經提前知道了參與實驗者的目標變量的值(即你已經知道如果他們是否是近視),這又是一個有監督學習的問題——更具體地說,這是一個分類的問題。
實例3
假設你負責的公司有很多的客戶。根據他們最近與公司的互動結果,最近購買的產品,以及他們的人口統計資料,你想要把相似的客戶組成一個群體,以不同的方式來對待他們——比如給他們提供獨家折扣券。在這種情況下,將會使用上面提到的某些特性作為算法的輸入,而算法將決定應該客戶群的數量或類型。這是無監督學習最典型的一個例子,因為我們事先根本就不知道輸出結果應該是怎樣的。
話雖如此,現在是實現我的承諾的時候了,來介紹一些更具體的算法……
回歸
首先,回歸不是單一的有監督學習的技術,而是許多技術所屬的整個類別。
回歸的主要思想是給定一些輸入變量,我們想要預測目標變量的值是什么樣的。在回歸的情況下,目標變量是連續的——這意味著它可以在指定范圍內取任意的值。另一方面,輸入變量既可以是離散的,也可以是連續的。
在回歸技術中,最廣為人知的就是線性回歸和邏輯回歸了。讓我們仔細研究研究。
線性回歸
在線性回歸中,我們試圖建立輸入變量與目標變量之間的關系,這種關系是由一條直線表示的,通常稱為回歸線。
例如,假設我們有兩個輸入變量X1和X2以及一個目標變量Y,這種關系可以用數學形式表示:
- Y = a * X1 + b*X2 +c
假設已經提供了X1和X2的值,我們的目標是對a、b、c三個參數進行調整,從而使Y盡可能接近實際值。
花點時間講個例子吧!
假設我們已經有了Iris數據集,它已經包含了不同類型的花朵的萼片和花瓣的大小數據,例如:Setosa,Versicolor和Virginica。
使用R軟件,假設已經提供了花瓣的寬度和長度,我們需要實現一個線性回歸來預測萼片的長度。
在數學上,我們將通過如下關系是獲取a、b的值:
- SepalLength = a * PetalWidth + b* PetalLength +c
相應的代碼如下:
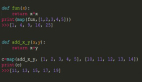
- # Load required packages
- library(ggplot2)
- # Load iris dataset
- data(iris)
- # Have a look at the first 10 observations of the dataset
- head(iris)
- # Fit the regression line
- fitted_model <- lm(Sepal.Length ~ Petal.Width + Petal.Length, data = iris)
- # Get details about the parameters of the selected model
- summary(fitted_model)
- # Plot the data points along with the regression line
- ggplot(iris, aes(x = Petal.Width, y = Petal.Length, color = Species)) +
- geom_point(alpha = 6/10) +
- stat_smooth(method = "lm", fill="blue", colour="grey50", size=0.5, alpha = 0.1)
線性回歸的結果如下圖所示,黑點表示初始數據點在藍線擬合回歸直線,于是便有了估算結果,a= -0.31955,b = 0.54178,和c = 4.19058,這個結果可能最接近實際情況,即花萼的長度。
從現在開始,通過將花瓣長度和花瓣寬度的值應用到定義的線性關系中來,新出現的數據點我們也可以預測它的長度了。

邏輯回歸
這里的主要思想和線性回歸完全一樣。最大的不同就是回歸線不再是直的的。
相反,我們試圖建立的數學關系是類似于以下形式:
- Y=g(a*X1+b*X2)
這里的g()就是邏輯函數。
由于logistic函數的性質,Y是連續的,在[0,1]范圍內,可以理解為事件發生的概率。
我知道你喜歡例子,所以我再給你看一個!
這次,我們將對mtcars數據集進行實驗,該數據集包括燃料消耗和汽車設計的10個方面,以及1973 - 1974年生產的32輛汽車的性能。
使用R,我們將根據V/S和Miles/(US)加侖的測量值,預測自動變速器(am = 0)或手動(am = 1)汽車的概率。
am = g(a * mpg + b* vs +c):
- # Load required packages
- library(ggplot2)
- # Load data
- data(mtcars)
- # Keep a subset of the data features that includes on the measurement we are interested in
- cars <- subset(mtcars, select=c(mpg, am, vs))
- # Fit the logistic regression line
- fitted_model <- glm(am ~ mpg+vs, data=cars, family=binomial(link="logit"))
- # Plot the results
- ggplot(cars, aes(x=mpg, y=vs, colour = am)) + geom_point(alpha = 6/10) +
- stat_smooth(method="glm",fill="blue", colour="grey50", size=0.5, alpha = 0.1, method.args=list(family="binomial"))
結果如下圖所示,其中黑點代表數據集的初始點,藍色線代表a = 0.5359,b = - 2.7957,c = - 9.9183的擬合邏輯回歸線。

正如前面所提到的,我們可以觀察到由于回歸線的形式,logistic回歸輸出值只在范圍[0,1]中。
對于任何以V/S和Miles/(US)加侖為標準的新車,我們現在可以預測這輛車自動變速器的概率。
決策樹
決策樹是我們將要研究的第二種機器學習算法。決策樹最終分裂成了回歸和分類樹,因此可以用于有監督學習問題。
誠然,決策樹是最直觀的算法之一,它們可以模仿人們在大多數情況下的決定方式。他們所做的基本上就是繪制出所有可能路徑的“地圖”,并在每種情況下畫出相應的結果。
圖形表示將有助于更好地理解我們正在討論的內容。

基于這樣一棵樹,算法可以根據相應的標準值決定在每個步驟中遵循哪條路徑。算法選擇分割標準的方式和每個級別的相應閾值,取決于候選變量對目標變量的信息量,以及哪個設置最小化了所產生的預測錯誤。
這里還有一個例子!
這一次討論的數據集是readingSkills。它包括了學生的考試成績和分數。
我們將基于多種指標把學生分為母語為英語的人(nativeSpeaker = 1)或外國人(nativeSpeaker = 0),包括他們在測試中的得分,他們的鞋碼,以及他們的年齡。
對于R中的實現,我們首先需要安裝party包。
- # Include required packages
- library(party)
- library(partykit)
- # Have a look at the first ten observations of the dataset
- print(head(readingSkills))
- input.dat <- readingSkills[c(1:105),]
- # Grow the decision tree
- output.tree <- ctree(
- nativeSpeaker ~ age + shoeSize + score,
- data = input.dat)
- # Plot the results
- plot(as.simpleparty(output.tree))
我們可以看到,使用的第一個分裂標準是分數,因為它在預測目標變量時非常重要,而鞋子的大小并沒有被考慮在內,因為它沒有提供任何關于語言的有用信息。

現在,如果我們有了一個新學生,知道他們的年齡和分數,我們就可以預測他們是不是一個以英語為母語的人!
聚類算法
到目前為止,我們只討論了一些關于有監督學習的問題。現在,我們繼續研究聚類算法,而它則是無監督學習方法的子集。
所以,只是稍微修改了一點…
對于集群,如果有一些初始數據進行支配,我們想要形成一個組,這樣一些組的數據點是相似的,并且不同于其他組的數據點。
我們將要學習的算法叫做k-means,k表示產生的簇的數量,這是最流行的聚類方法之一。
還記得我們之前用過的Iris數據集嗎?我們將再次使用它。
為了研究,我們用他們的花瓣測量方法繪制了數據集的所有數據點,如下圖所示:

基于花瓣的度量值,我們將使用3-means clustering方法將數據點聚集成3組。
那么3-means,或者說是k-means算法是如何工作的呢?整個過程可以用幾個簡單的步驟來概括:
- 初始化步驟:對于k = 3簇,算法隨機選取3個點作為每個集群的中心點。
- 集群分配步驟:算法通過其余的數據點,并將每個數據點分配給最近的集群。
- Centroid移動步驟:在集群分配之后,每個集群的中心點移動到屬于集群的所有點的平均值。
步驟2和步驟3重復多次,直到對集群分配沒有更改。R中k-means算法的實現很簡單,可以用以下代碼實現:
- # Load required packages
- library(ggplot2)
- library(datasets)
- # Load data
- data(iris)
- # Set seed to make results reproducible
- set.seed(20)
- # Implement k-means with 3 clusters
- iris_cl <- kmeans(iris[, 3:4], 3, nstart = 20)
- iris_cl$cluster <- as.factor(iris_cl$cluster)
- # Plot points colored by predicted cluster
- ggplot(iris, aes(Petal.Length, Petal.Width, color = iris_cl$cluster)) + geom_point()
從結果中可以看出,該算法將數據分成三組,分別用三種不同的顏色表示。我們也可以觀察到這些簇是根據花瓣的大小形成的。更具體地說,紅色表示花瓣小的花,綠色表示花瓣相對較大的蝴蝶花,而藍色則表示中等大小的花瓣。

值得注意的是,在任何聚類中,對形成群體的解釋都需要在該領域有一些專家知識。在我們的例子中,如果你不是一個植物學家,你可能不會意識到k - means所做的是把iris聚集到他們不同的類型,例如Setosa,Versicolor和Virginica,而沒有任何關于它們的知識!
因此,如果我們再次繪制數據,這個時間被它們的物種著色,我們將看到集群中的相似性。

總結
我們從一開始就走了很長一段路。我們討論了回歸(線性和邏輯)和決策樹,最后討論了k - means集群。我們還在R中實現了一些簡單但強大的方法。
那么,每種算法的優點是什么呢?在現實生活中,你應該選擇哪一個?
- 首先,所呈現的方法并不是一些不適用的算法——它們在世界各地的生產系統中被廣泛使用,因此需要根據不同的任務進行選擇,選擇恰當的話可以變得相當強大。
- 其次,為了回答上述問題,你必須清楚你所說的優點究竟是什么意思,因為每種方法在不同環境中展現出來的優點是不同的,例如解釋性、穩健性、計算時間等。
現在,我們終于可以自信地將這些知識應用于一些實際的問題了!