













可以提高你的圖像識別模型準確率的7個技巧
假定,你已經收集了一個數據集,建立了一個神經網絡,并訓練了您的模型。
但是,盡管你投入了數小時(有時是數天)的工作來創建這個模型,它還是能得到50-70%的準確率。這肯定不是你所期望的。
下面是一些提高模型性能指標的策略或技巧,可以大大提升你的準確率。
得到更多的數據
這無疑是最簡單的解決辦法,深度學習模型的強大程度取決于你帶來的數據。增加驗證準確性的最簡單方法之一是添加更多數據。如果您沒有很多訓練實例,這將特別有用。
如果您正在處理圖像識別模型,您可以考慮通過使用數據增強來增加可用數據集的多樣性。這些技術包括從將圖像翻轉到軸上、添加噪聲到放大圖像。如果您是一個強大的機器學習工程師,您還可以嘗試使用GANs進行數據擴充。

請注意,您使用的增強技術會更改圖像的整個類。例如,在y軸上翻轉的圖像沒有意義!
添加更多的層
向模型中添加更多層可以增強它更深入地學習數據集特性的能力,因此它將能夠識別出作為人類可能沒有注意到的細微差異。
這個技巧圖解決的任務的性質。
對于復雜的任務,比如區分貓和狗的品種,添加更多的層次是有意義的,因為您的模型將能夠學習區分獅子狗和西施犬的微妙特征。
對于簡單的任務,比如對貓和狗進行分類,一個只有很少層的簡單模型就可以了。
更多的層->更微妙的模型
更改圖像大小
當您對圖像進行預處理以進行訓練和評估時,需要做很多關于圖像大小的實驗。
如果您選擇的圖像尺寸太小,您的模型將無法識別有助于圖像識別的顯著特征。
相反,如果您的圖像太大,則會增加計算機所需的計算資源,并且/或者您的模型可能不夠復雜,無法處理它們。
常見的圖像大小包括64x64、128x128、28x28 (MNIST)和224x224 (vgg -16)。
請記住,大多數預處理算法不考慮圖像的高寬比,因此較小尺寸的圖像可能會在某個軸上收縮。

從一個大分辨率的圖像到一個小尺寸的圖像,比如28x28,通常會導致大量的像素化,這往往會對你的模型的性能產生負面影響
增加訓練輪次
epoch基本上就是你將整個數據集通過神經網絡傳遞的次數。以+25、+100的間隔逐步訓練您的模型。
只有當您的數據集中有很多數據時,才有必要增加epoch。然而,你的模型最終將到達一個點,即增加的epoch將不能提高精度。
此時,您應該考慮調整模型的學習速度。這個小超參數決定了你的模型是達到全局最小值(神經網絡的最終目標)還是陷入局部最小值。
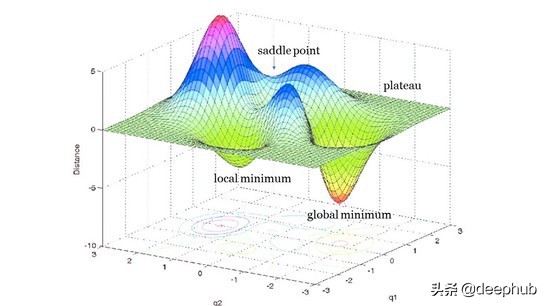
全局最小是神經網絡的最終目標。
減少顏色通道
顏色通道反映圖像數組的維數。大多數彩色(RGB)圖像由三個彩色通道組成,而灰度圖像只有一個通道。
顏色通道越復雜,數據集就越復雜,訓練模型所需的時間也就越長。
如果顏色在你的模型中不是那么重要的因素,你可以繼續將你的彩色圖像轉換為灰度。
你甚至可以考慮其他顏色空間,比如HSV和Lab。

RGB圖像由三種顏色通道組成:紅、綠、藍
轉移學習
遷移學習包括使用預先訓練過的模型,如YOLO和ResNet,作為大多數計算機視覺和自然語言處理任務的起點。
預訓練的模型是最先進的深度學習模型,它們在數百萬個樣本上接受訓練,通常需要數月時間。這些模型在檢測不同圖像的細微差別方面有著驚人的巨大能力。
這些模型可以用作您的模型的基礎。大多數模型都很好,所以您不需要添加卷積和池化
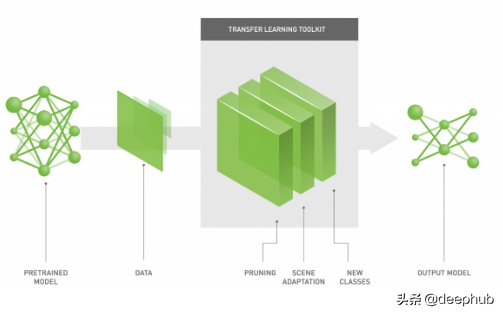
遷移學習可以大大提高你的模型的準確性~50%到90%!(來自英偉達的論文)
超參數
上面的技巧為你提供了一個優化模型的基礎。要真正地調整模型,您需要考慮調整模型中涉及的各種超參數和函數,如學習率(如上所述)、激活函數、損失函數、甚至批大小等都是非常重要的需要調整的參數。
總結
這些技巧是希望大家在不知道如何去做的時候可以快速的找到提高的思路。
還有無數其他方法可以進一步優化你的深度學習,但是上面描述的這些方法只是深度學習優化部分的基礎。
另外:每次改變深度學習模型時都要保存模型。這將幫助您重用先前的模型配置,如果它提供了更大的準確性。





















