阿里開源自研語音識別模型DFSMN,準確率高達96.04%
近日,阿里巴巴達摩院機器智能實驗室開源了新一代語音識別模型 DFSMN,將全球語音識別準確率紀錄提高至 96.04%(這一數據測試基于世界***的免費語音識別數據庫 LibriSpeech)。
對比目前業界使用最為廣泛的 LSTM 模型,DFSMN 模型訓練速度更快、識別準確率更高。采用全新 DFSMN 模型的智能音響或智能家居設備,相比前代技術深度學習訓練速度提到了 3 倍,語音識別速度提高了 2 倍。
開源地址:https://github.com/tramphero/kaldi
阿里開源語音識別模型DFSMN
在近期舉行的云棲大會武漢峰會上,裝有 DFSMN 語音識別模型的“AI 收銀員”在與真人店員的 PK 中,在嘈雜環境下準確識別了用戶的語音點單,在短短 49 秒內點了 34 杯咖啡。此外,裝備這一語音識別技術的自動售票機也已在上海地鐵“上崗”。
著名語音識別專家,西北工業大學教授謝磊表示:“阿里此次開源的 DFSMN 模型,在語音識別準確率上的穩定提升是突破性的,是近年來深度學習在語音識別領域***代表性的成果之一,對全球學術界和 AI 技術應用都有巨大影響。”
圖:阿里在 GitHub 平臺上開源了自主研發的 DFSMN 語音識別模型
語音識別聲學模型
語音識別技術一直都是人機交互技術的重要組成部分。有了語音識別技術,機器就可以像人類一樣聽懂說話,進而能夠思考、理解和反饋。
近幾年隨著深度學習技術的使用,基于深度神經網絡的語音識別系統性能獲得了極大的提升,開始走向實用化。基于語音識別的語音輸入、語音轉寫、語音檢索和語音翻譯等技術得到了廣泛的應用。
目前主流的語音識別系統普遍采用基于深度神經網絡和隱馬爾可夫(Deep Neural Networks-Hidden Markov Model,DNN-HMM)的聲學模型,其模型結構如圖 1 所示。聲學模型的輸入是傳統的語音波形經過加窗、分幀,然后提取出來的頻譜特征,如 PLP, MFCC 和 FBK 等。而模型的輸出一般采用不同粒度的聲學建模單元,例如單音素 (mono-phone)、單音素狀態、綁定的音素狀態 (tri-phonestate) 等。從輸入到輸出之間可以采用不同的神經網絡結構,將輸入的聲學特征映射得到不同輸出建模單元的后驗概率,然后再結合 HMM 進行解碼得到最終的識別結果。
最早采用的網絡結構是前饋全連接神經網路(Feedforward Fully-connected Neural Networks, FNN)。FNN 實現固定輸入到固定輸出的一對一映射,其存在的缺陷是沒法有效利用語音信號內在的長時相關性信息。一種改進的方案是采用基于長短時記憶單元(Long-Short Term Memory,LSTM)的循環神經網絡(Recurrent Neural Networks,RNN)。LSTM-RNN 通過隱層的循環反饋連接,可以將歷史信息存儲在隱層的節點中,從而可以有效地利用語音信號的長時相關性。
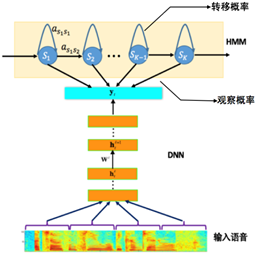
圖 1. 基于 DNN-HMM 的語音識別系統框圖
進一步地通過使用雙向循環神經網絡(BidirectionalRNN),可以有效地利用語音信號歷史以及未來的信息,更有利于語音的聲學建模。基于循環神經網絡的語音聲學模型相比于前饋全連接神經網絡可以獲得顯著的性能提升。但是循環神經網絡相比于前饋全連接神經網絡模型更加復雜,往往包含更多的參數,這會導致模型的訓練以及測試都需要更多的計算資源。
另外基于雙向循環神經網絡的語音聲學模型,會面臨很大的時延問題,對于實時的語音識別任務不適用。現有的一些改進的模型,例如,基于時延可控的雙向長短時記憶單元(Latency Controlled LSTM,LCBLSTM )[1-2],以及前饋序列記憶神經網絡(Feedforward SequentialMemory Networks,FSMN)[3-5]。去年我們在工業界***個上線了基于 LCBLSTM 的語音識別聲學模型。配合阿里的大規模計算平臺和大數據,采用多機多卡、16bit 量化等訓練和優化方法進行聲學模型建模,取得了相比于 FNN 模型約 17-24% 的相對識別錯誤率下降。
FSMN 模型的前世今生
1. FSMN 模型
FSMN 是近期被提出的一種網絡結構,通過在 FNN 的隱層添加一些可學習的記憶模塊,從而可以有效地對語音的長時相關性進行建模。FSMN 相比于 LCBLSTM 不僅可以更加方便地控制時延,而且也能獲得更好的性能,需要的計算資源也更少。但是標準的 FSMN 很難訓練非常深的結構,會由于梯度消失問題導致訓練效果不好。而深層結構的模型目前在很多領域被證明具有更強的建模能力。因而針對此我們提出了一種改進的 FSMN 模型,稱之為深層的 FSMN(DeepFSMN, DFSMN)。進一步地我們結合 LFR(lowframe rate)技術構建了一種高效的實時語音識別聲學模型,相比于去年我們上線的 LCBLSTM 聲學模型可以獲得超過 20% 的相對性能提升,同時可以獲得2-3 倍的訓練以及解碼的加速,可以顯著地減少我們的系統實際應用時所需要的計算資源。
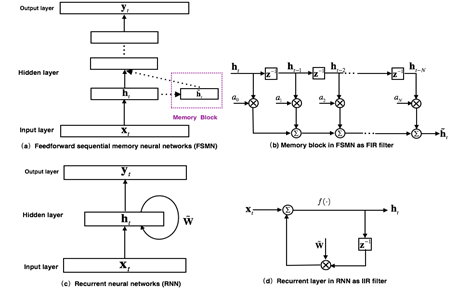
圖 2. FSMN 模型結構以及和 RNN 的對比
2. FSMN 到 cFSMN 的發展歷程
最早提出的 FSMN 的模型[3]結構如圖 2(a)所示,其本質上是一個前饋全連接神經網絡,通過在隱層旁添加一些記憶模塊(memory block)來對周邊的上下文信息進行建模,從而使得模型可以對時序信號的長時相關性進行建模。記憶模塊采用如圖 2(b)所示的抽頭延遲結構將當前時刻以及之前 N 個時刻的隱層輸出通過一組系數編碼得到一個固定的表達。FSMN 的提出是受到數字信號處理中濾波器設計理論的啟發:任何***響應沖擊(Infinite Impulse Response, IIR)濾波器可以采用高階的有限沖擊響應(Finite Impulse Response, FIR)濾波器進行近似。從濾波器的角度出發,如圖 2(c)所示的 RNN 模型的循環層就可以看作如圖 2(d)的一階 IIR 濾波器。而 FSMN 采用的采用如圖 2(b)所示的記憶模塊可以看作是一個高階的 FIR 濾波器。從而 FSMN 也可以像 RNN 一樣有效地對信號的長時相關性進行建模,同時由于 FIR 濾波器相比于 IIR 濾波器更加穩定,因而 FSMN 相比于 RNN 訓練上會更加簡單和穩定。
根據記憶模塊編碼系數的選擇,可以分為:1)標量 FSMN(sFSMN);2)矢量 FSMN(vFSMN)。sFSMN 和 vFSMN 顧名思義就是分別使用標量和矢量作為記憶模塊的編碼系數。sFSMN 和 vFSMN 記憶模塊的表達分別如下公式:
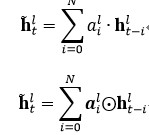
以上的 FSMN 只考慮了歷史信息對當前時刻的影響,我們可以稱之為單向的 FSMN。當我們同時考慮歷史信息以及未來信息對當前時刻的影響時,我們可以將單向的 FSMN 進行擴展得到雙向的 FSMN。雙向的 sFSMN 和 vFSMN 記憶模塊的編碼公式如下:
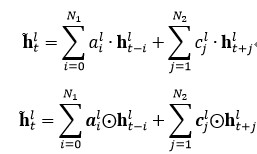
這里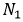 和
和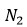
分別代表回看(look-back)的階數和向前看(look-ahead)的階數。我們可以通過增大階數,也可以通過在多個隱層添加記憶模塊來增強 FSMN 對長時相關性的建模能力。
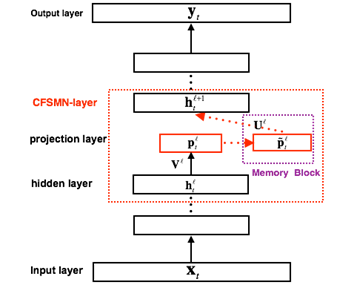
圖 3. cFSMN 結構框圖
FSMN 相比于 FNN,需要將記憶模塊的輸出作為下一個隱層的額外輸入,這樣就會引入額外的模型參數。隱層包含的節點越多,則引入的參數越多。研究[4]結合矩陣低秩分解(Low-rank matrix factorization)的思路,提出了一種改進的 FSMN 結構,稱之為簡潔的 FSMN(CompactFSMN,cFSMN),是一個第l 個隱層包含記憶模塊的 cFSMN 的結構框圖。
對于 cFSMN,通過在網絡的隱層后添加一個低維度的線性投影層,并且將記憶模塊添加在這些線性投影層上。進一步的,cFSMN 對記憶模塊的編碼公式進行了一些改變,通過將當前時刻的輸出顯式地添加到記憶模塊的表達中,從而只需要將記憶模塊的表達作為下一層的輸入。這樣可以有效得減少模型的參數量,加快網絡的訓練。具體單向和雙向的 cFSMN 記憶模塊的公式表達分別如下:
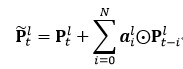
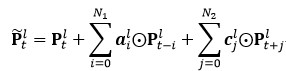
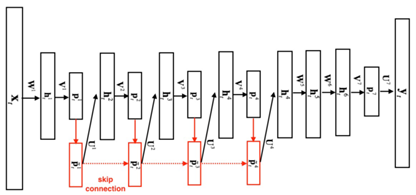
圖 4. Deep-FSMN (DFSMN)模型結構框圖
LFR-DFSMN 聲學模型
1. Deep-FSMN (DFSMN)網絡結構
如圖 4 是我們進一步提出的 Deep-FSMN(DFSMN)的網絡結構框圖,其中左邊***個方框代表輸入層,右邊***一個方框代表輸出層。我們通過在 cFSMN 的記憶模塊(紅色框框表示)之間添加跳轉連接(skip connection),從而使得低層記憶模塊的輸出會被直接累加到高層記憶模塊里。這樣在訓練過程中,高層記憶模塊的梯度會直接賦值給低層的記憶模塊,從而可以克服由于網絡的深度造成的梯度消失問題,使得可以穩定地訓練深層的網絡。我們對記憶模塊的表達也進行了一些修改,通過借鑒擴張(dilation)卷積[6]的思路,在記憶模塊中引入一些步幅(stride)因子,具體的計算公式如下:
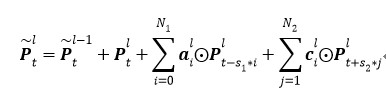
其中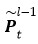 表示第
表示第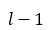
層記憶模塊第t個時刻的輸出。S1 和 S2 分別表示歷史和未來時刻的編碼步幅因子,例如 S1=2 則表示對歷史信息進行編碼時每隔一個時刻取一個值作為輸入。這樣在相同的階數的情況下可以看到更遠的歷史,從而可以更加有效的對長時相關性進行建模。
對于實時的語音識別系統我們可以通過靈活的設置未來階數來控制模型的時延,在極端情況下,當我們將每個記憶模塊的未來階數都設置為0,則我們可以實現無時延的一個聲學模型。對于一些任務,我們可以忍受一定的時延,我們可以設置小一些的未來階數。
相比于之前的 cFSMN,我們提出的 DFSMN 優勢在于,通過跳轉連接可以訓練很深的網絡。對于原來的 cFSMN,由于每個隱層已經通過矩陣的低秩分解拆分成了兩層的結構,這樣對于一個包含 4 層 cFSMN 層以及兩個 DNN 層的網絡,總共包含的層數將達到 13 層,從而采用更多的 cFSMN 層,會使得層數更多而使得訓練出現梯度消失問題,導致訓練的不穩定性。我們提出的 DFSMN 通過跳轉連接避免了深層網絡的梯度消失問題,使得訓練深層的網絡變得穩定。需要說明的是,這里的跳轉連接不僅可以加到相鄰層之間,也可以加到不相鄰層之間。跳轉連接本身可以是線性變換,也可以是非線性變換。具體的實驗我們可以實現訓練包含數十層的 DFSMN 網絡,并且相比于 cFSMN 可以獲得顯著的性能提升。
從最初的 FSMN 到 cFSMN 不僅可以有效地減少模型的參數,而且可以獲得更好的性能[4]。進一步的在 cFSMN 的基礎上,我們提出的 DFSMN,可以更加顯著地提升模型的性能。如下表是在一個 2000 小時的英文任務上基于 BLSTM,cFSMN,DFSMN 的聲學模型性能對比。
|
Model |
BLSTM |
cFSMN |
DFSMN |
|
WER% |
10. 9 |
10. 8 |
9. 4 |
從上表中可以看到,在 2000 小時這樣的任務上,DFSMN 模型可以獲得比 BLSTM 聲學模型相對 14% 的錯誤率降低,顯著提高了聲學模型的性能。
2. 基于 LFR-DFSMN 的語音識別聲學模型
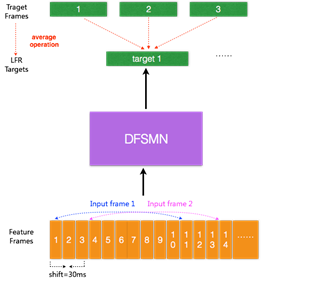
圖 5. LFR-DFSMN 聲學模型結構框圖
目前的聲學模型,輸入的是每幀語音信號提取的聲學特征,每幀語音的時長通常為 10ms,對于每個輸入的語音幀信號會有相對應的一個輸出目標。最近有研究提出一種低幀率(LowFrame Rate,LFR)[7]建模方案:通過將相鄰時刻的語音幀進行綁定作為輸入,去預測這些語音幀的目標輸出得到的一個平均輸出目標。具體實驗中可以實現三幀(或更多幀)拼接而不損失模型的性能。從而可以將輸入和輸出減少到原來的三分之一甚至更多,可以極大地提升語音識別系統服務時聲學得分的計算以及解碼的效率。我們結合 LFR 和以上提出的 DFSMN,構建了如圖 5 的基于 LFR-DFSMN 的語音識別聲學模型,經過多組實驗我們最終確定了采用一個包含 10 層 cFSMN 層 +2 層 DNN 的 DFSMN 作為聲學模型,輸入輸出則采用 LFR,將幀率降低到原來的三分之一。識別結果和去年我們上線的***的 LCBLSTM 基線比較如下表所示。
|
CER% |
產品線A |
產品線B |
|
LFR-LCBLSTM |
18. 92 |
10. 21 |
|
LFR-DFSMN |
15. 00(+20.72%) |
8. 04(21.25%) |
通過結合 LFR 技術,我們可以獲得三倍的識別加速。從上表中可以看到,在實際工業規模應用上,LFR-DFSMN 模型比 LFR-LCBLSTM 模型可以獲得 20% 的錯誤率下降,展示了對大規模數據更好的建模特性。
基于多機多卡的大數據聲學模型訓練
實際的語音識別服務通常會面對非常復雜的語音數據,語音識別聲學模型一定要盡可能地覆蓋各種可能的場景,包括各種對話、各種聲道、各種噪音甚至各種口音,這就意味著海量的數據。而如何應用海量數據快速訓練聲學模型并上線服務,就直接關系到業務相應速度。
我們利用阿里的 Max-Compute 計算平臺和多機多卡并行訓練工具,在使用 8 機 16GPU 卡、訓練數據為 5000 小時的情況下,關于 LFR-DFSMN 聲學模型和 LFR-LCBLSTM 的訓練速度如下表:
|
處理一個 epoch 需要的時間 |
|
|
LFR-LCBLSTM |
10. 8 小時 |
|
LFR-DFSMN |
3. 4 小時 |
相比于基線 LCBLSTM 模型,每個 epoch DFSMN 可以獲得 3 倍的訓練速度提升。在 2 萬小時的數據量上訓練 LFR-DFSMN,模型收斂一般只需要3-4 個 epoch,因此在 16GPU 卡的情況下,我們可以在 2 天左右完成 2 萬小時數據量的 LFR-DFSMN 聲學模型的訓練。
解碼延時、識別速度和模型大小
設計更為實用化的語音識別系統,我們不僅需要盡可能地提升系統的識別性能,而且需要考慮系統的實時性,這樣才能給用戶提供更好的體驗。此外在實際應用中我們還需要考慮服務成本,因而對于語音識別系統的功耗也有一定的要求。傳統的 FNN 系統,需要使用拼幀技術,解碼延遲通常在5-10 幀,大約 50-100ms。而去年上線的 LCBLSTM 系統,解決了 BLSTM 的整句延遲的問題,最終可以將延時控制在 20 幀左右,大約 200ms。對于一些對延時有更高要求的線上任務,還可以在少量損失識別性能的情況下(0.2%-0.3% 絕對值左右),將延遲控制在 100ms,完全可以滿足各類任務的需求。LCBLSTM 相比于***的 FNN 可以獲得超過 20% 的相對性能提升,但是相同 CPU 上識別速度變慢(即功耗高),這主要是由模型的復雜度導致。
我們***的 LFR-DFSMN,通過 LFR 技術可以將識別速度加速 3 倍以上,進一步的 DFSMN 相比于 LCBLSTM 在模型復雜度上可以再降低 3 倍左右。如下表是我們在一個測試集上統計的不同的模型需要的識別時間,時間越短則表示我們所需要的計算功耗越低:
|
模型 |
整個測試集識別所需要的時間 |
|
LCBLSTM |
956 秒 |
|
DFSMN |
377 秒 |
|
LFR-LCBLSTM |
339 秒 |
|
LFR-DFSMN |
142 秒 |
關于 LFR-DFSMN 的解碼時延問題,我們可以通過減小記憶模塊濾波器向未來看的階數來減小時延。具體實驗中我們驗證了不同的配置,當我們將 LFR-DFSMN 的延時控制在5-10 幀時,大致只損失相對3% 的性能。
此外,相對于復雜的 LFR-LCBLSTM 模型,LFR-DFSMN 模型具有模型精簡的特點,雖然有 10 層 DFSMN,但整體模型大小只有 LFR-LCBLSTM 模型的一半,模型大小壓縮了 50%。
參考文獻:
1.YuZhang, Guoguo Chen, Dong Yu, and Kaisheng Yao, ng Yao, long short term memory RNNs for distantspeech recognition,, in IEEE International Conference of Acoustics,Speech andSignal Processing (ICASSP), 2016, pp. 5755-5759.
2.XueS, Yan Z. Improving latency-controlled BLSTM acoustic models for online speech recognition[C]//Acoustics,Speech and Signal Processing (ICASSP), 2016 IEEE International Conference on.IEEE. 2017.
3.Zhang S, Liu C, Jiang H, et al. Feedforwardsequential memory networks: A new structure to learn long-term dependency[J].arXiv preprint arXiv:1512.08301, 2015.
4.Zhang S, Jiang H, Xiong S, et al. CompactFeedforward Sequential Memory Networks for Large Vocabulary Continuous SpeechRecognition[C]//INTERSPEECH. 2016: 3389-3393.
5.Zhang S, Liu C, Jiang H, et al. Non-recurrentNeural Structure for Long-Term Dependency[J]. IEEE/ACM Transactions on Audio,Speech, and Language Processing, 2017, 25(4): 871-884.
6.Oord A, Dieleman S, Zen H, et al. Wavenet:A generative model for raw audio[J]. arXiv preprint arXiv:1609.03499, 2016.
7.Pundak G, Sainath T N. Lower Frame Rate NeuralNetwork Acoustic Models[C]//INTERSPEECH. 2016: 22-26.