PyTorch開發(fā)新藥?哈佛出品,10行代碼訓(xùn)練“藥神”模型
本文經(jīng)AI新媒體量子位(公眾號ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
最近,來自哈佛大學(xué)等機(jī)構(gòu)的研究人員,開發(fā)出了一個(gè)AI“藥神”工具包,為加速新冠疫情下的新藥研發(fā)助力。
這款名為DeepPurpose的工具包,不僅包含COVID-19的生物測定數(shù)據(jù)集,還有56種前沿的AI模型。
作為一個(gè)基于PyTorch的工具包,DeepPurpose只需要不到10行代碼,就能訓(xùn)練出AI“藥神”模型。
這些模型不僅能完成虛擬篩選,還能挖掘出已有藥物的新功能(例如,高血壓藥物可治療阿爾茲海默癥)。
下面來看看它實(shí)現(xiàn)的原理。
56種前沿模型,功能齊全
DeepPurpose由兩個(gè)編碼器組成,分別用來生成藥物分子和蛋白質(zhì)的嵌入(Embedding),也就是深度學(xué)習(xí)過程中的映射。
隨后,將這兩個(gè)編碼器串聯(lián)到解碼器中,用于預(yù)測二者的結(jié)合親和力,如下圖所示。
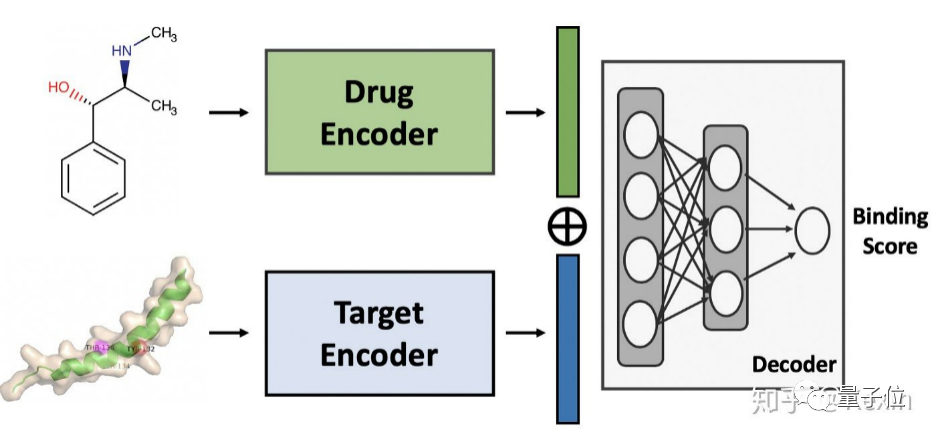
在這期間,模型的輸入是藥物靶標(biāo)對(drug-target pair),輸出則是指示藥物-靶對的結(jié)合活性的分?jǐn)?shù)。
當(dāng)然,DeepPurpose畢竟是一個(gè)工具包,所以無論是藥物分子、還是蛋白質(zhì),它們的編碼器都不止一種類型。
對于藥物分子,DeepPurpose提供了8種編碼器。
在這些編碼器中,有用于構(gòu)造分子結(jié)構(gòu)圖的、有將繪制的分子轉(zhuǎn)換成二進(jìn)制數(shù)的、也有用于獲取序列順序信息的等……模型各有不同。
而對于靶蛋白,DeepPurpose也提供了7種編碼器,相較于藥物的化學(xué)和信息學(xué), 編碼器對靶蛋白的轉(zhuǎn)換更多地側(cè)重于生物學(xué)信息。
也就是說,DeepPurpose一共能提供7*8=56種模型,其中許多模型非常新穎前沿,值得入手。
那么,DeepPurpose究竟該怎么上手呢?
10步以內(nèi),上手AI“藥神”
事實(shí)上,訓(xùn)練一個(gè)新藥研發(fā)模型,需要通過以下幾個(gè)步驟,每一步都只需要用1行代碼實(shí)現(xiàn),所有這些步驟加起來,也不超過10步。
來看看這個(gè)模型要經(jīng)過的步驟:
1、數(shù)據(jù)加載
2、指定編碼器
3、分割數(shù)據(jù)集、編碼
4、生成模型配置文件
5、初始化模型
6、訓(xùn)練模型
7、舊藥新用/虛擬篩選
8、模型保存/加載
其中,DeepPurpose最關(guān)鍵的兩個(gè)功能,舊藥新用和虛擬篩選可以在訓(xùn)練后實(shí)現(xiàn)。可以看見,DeepPurpose會自動生成藥物的親和度,并由低到高進(jìn)行排序。

這樣,就能快速縮小高通量分子的篩選范圍(如果親和度為0,那真的不必考慮了)。
至于虛擬篩選,也是類似的工作,會生成一個(gè)與上圖相似的排名列表。
不僅如此,這個(gè)AI模型還包含另外幾種案例,例如SARS-CoV2 3CLPro的舊藥新用方法、預(yù)訓(xùn)練模型等。
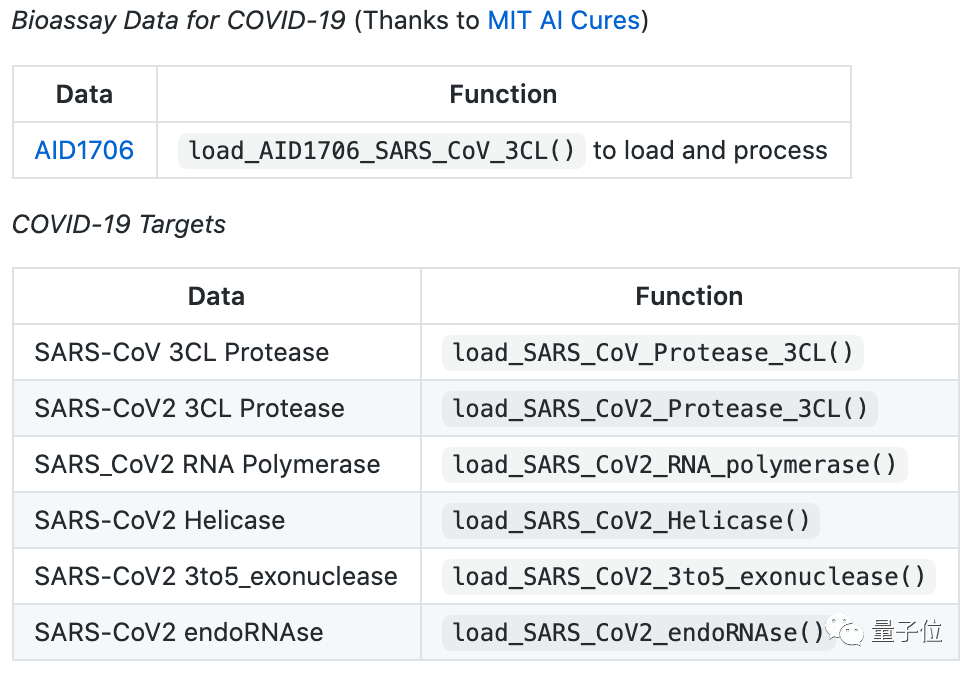
此外,針對近期引發(fā)關(guān)注的新冠疫情,DeepPurpose也包含了MIT收集的COVID-19開源數(shù)據(jù)集。
針對這些數(shù)據(jù),工具包中有相應(yīng)的函數(shù),可以直接引用。
而這個(gè)工具包的框架,正是基于藥物研發(fā)的原理制作的。
靶蛋白:藥物作用對象
藥物篩選最根本的原理,通常是判斷藥物分子與靶蛋白(藥物作用的目標(biāo))的親和性。
為什么是蛋白質(zhì)?
事實(shí)上,這是因?yàn)椴糠旨膊。ɡ绨┌Y、腫瘤)產(chǎn)生的原因,通常與某一類蛋白質(zhì)有關(guān),如果能找到、并用藥物“調(diào)節(jié)”這種蛋白質(zhì),就能治愈疾病。
△ 圖片來源于flickr
例如,細(xì)胞與細(xì)胞之間的交流,依靠的就是細(xì)胞膜上的糖蛋白。而某種疾病發(fā)生的原因,可能就是因?yàn)橐活惣?xì)胞上的糖蛋白過度表達(dá)。
而這個(gè)糖蛋白,就被稱之為疾病過程中的靶蛋白。
但能用來調(diào)節(jié)某種靶蛋白的藥物,并不好找,畢竟不是每種化合物都能很好地與靶蛋白“貼貼”。
在這樣的基礎(chǔ)上,研究人員開發(fā)了DeepPurpose,這個(gè)工具包能用于預(yù)測藥物分子與靶蛋白的親和度,專業(yè)學(xué)術(shù)名詞叫藥物-靶標(biāo)相互作用(Drug-Target Interaction, DTI),簡稱DTI。
之所以選擇用AI助力新藥研發(fā),也有其背后的原因。
AI助新藥研發(fā)一臂之力
事實(shí)上,藥廠研發(fā)出一種新藥,需要15年左右,甚至更久。
而在這期間,光是研究開發(fā)的階段,就要花掉2-10年。
研究開發(fā)的階段,目的是篩選出有治療潛力的新化合物,也就是說,每一種化合物都需要做實(shí)驗(yàn),去不斷試錯(cuò)。
這一過程不僅枯燥無味,而且工程量巨大,人力財(cái)力都得砸。
如果用AI完成藥物篩選這一過程,對于新藥研發(fā)的加速將會起到不小的作用。
作者介紹
論文的第一作者黃柯鑫,本科于紐約大學(xué)獲得數(shù)學(xué)和計(jì)算機(jī)雙學(xué)位,目前在哈佛大學(xué)讀碩士,專業(yè)與醫(yī)療大數(shù)據(jù)有關(guān)。
黃柯鑫的研究方向,主要是圖神經(jīng)網(wǎng)絡(luò)(GNN)在新藥研發(fā)和醫(yī)療文本(如電子病歷等)上的應(yīng)用。
此外,Tianfan Fu、Lucas Glass、Marinka Zitnik、Cao Xiao和Jimeng Sun也共同參與了研究工作。
傳送門
論文鏈接:
https://arxiv.org/abs/2004.08919
項(xiàng)目鏈接:
https://github.com/kexinhuang12345/DeepPurpose
黃柯鑫主頁:
https://www.kexinhuang.com/