













一行Python代碼訓練所有分類或回歸模型
自動化機器學習(自動ML)是指自動化數據科學模型開發管道的組件。Automl減少數據科學家的工作量并加快工作流程。Automl可用于自動化各種流水線組件,包括數據理解,EDA,數據處理,模型訓練,Quand參數調諧等。
對于端到端機器學習項目,每個管道組件的復雜性取決于項目。有各種自動啟用源庫,可加快每個管道組件。閱讀本文知道8個自動列表庫以自動化機器學習管道。
在本文中,我們將討論如何使用開源Python庫LazyPredict自動化模型訓練過程。
什么是lazypredict?
LazyPredict是一個開源Python庫,可自動化模型訓練管道并加快工作流程。LazyPredict在分類數據集中約為30個分類模型,并列出了回歸數據集的40個回歸模型。
LazyPredict與訓練有素的型號一起回到其性能指標,而無需編寫太多代碼。人們可以比較每個模型的性能指標并調整最佳模型,以進一步提高性能。
安裝:
leazepredict可以使用pypl庫安裝:
- pip install lazypredict
安裝后,可以導入庫進行分類和回歸模型的自動訓練。
- from lazypredict.Supervised import LazyRegressor, LazyClassifier
用法:
LazyPredict支持分類和回歸問題,所以我會討論兩個任務的演示
波士頓住房(回歸)和泰坦尼克號(分類)DataSet用于演示LazyPredict庫。
分類任務:
LazyPredict的用法非常直觀,類似于Scikit-learn。首先,為分類任務創建估計器LazyClassifier的實例。一個可以通過定制度量標準進行評估,默認情況下,每種型號將在準確性,ROC AUC分數,F1分數進行評估。
在繼續進行LazyPredict模型訓練之前,必須閱讀數據集并處理它以使其適合訓練。
- import pandas as pd
- from sklearn.model_selection import train_test_split
- # Read the titanic dataset
- df_cls = pd.read_csv("titanic.csv")
- df_clsdf_cls = df_cls.drop(['PassengerId','Name','Ticket', 'Cabin'], axis=1)
- # Drop instances with null records
- df_clsdf_cls = df_cls.dropna()
- # feature processing
- df_cls['Sex'] = df_cls['Sex'].replace({'male':1, 'female':0})
- df_cls['Embarked'] = df_cls['Embarked'].replace({'S':0, 'C':1, 'Q':2})
- # Creating train test split
- y = df_cls['Survived']
- X = df_cls.drop(columns=['Survived'], axis=1)
- # Call train test split on the data and capture the results
- X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42, test_size=0.2)
在特征工程和將數據分成訓練測試數據之后,我們可以使用LazyPredict進行模型訓練。
- # LazyClassifier Instance and fiting data
- cls= LazyClassifier(ignore_warnings=False, custom_metric=None)
- models, predictions = cls.fit(X_train, X_test, y_train, y_test)
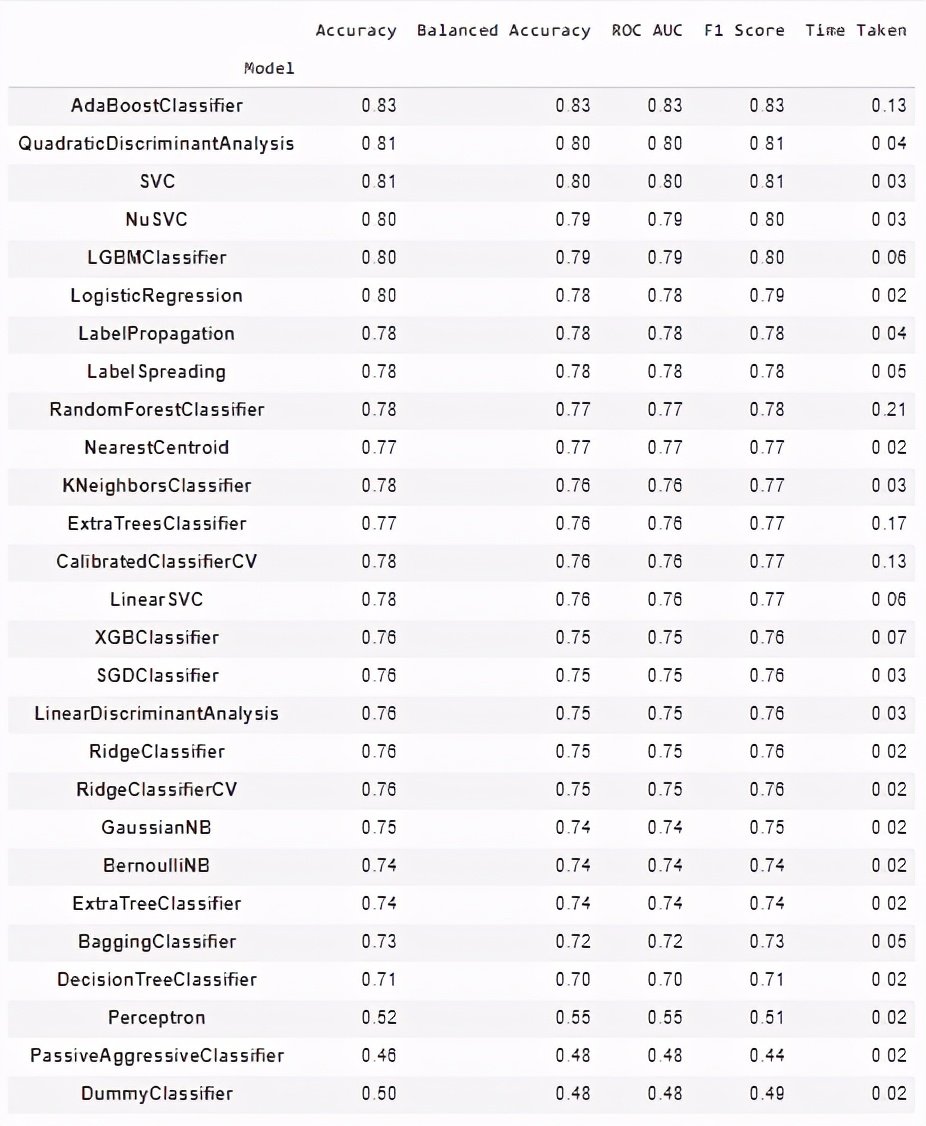
回歸任務:
類似于分類模型訓練,LazyPredict附帶了回歸數據集的自動模型訓練。實現類似于分類任務,在實例LazyRegressor中的更改。
- import pandas as pd
- from sklearn.model_selection import train_test_split
- # read the data
- column_names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
- df_reg = pd.read_csv("housing.csv", header=None, delimiter=r"\s+", names=column_names)
- # Creating train test split
- y = df_reg['MEDV']
- X = df_reg.drop(columns=['MEDV'], axis=1)
- # Call train_test_split on the data and capture the results
- X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42, test_size=0.2)
- reg = LazyRegressor(ignore_warnings=False, custom_metric=None)
- models, predictions = reg.fit(X_train, X_test, y_train, y_test)
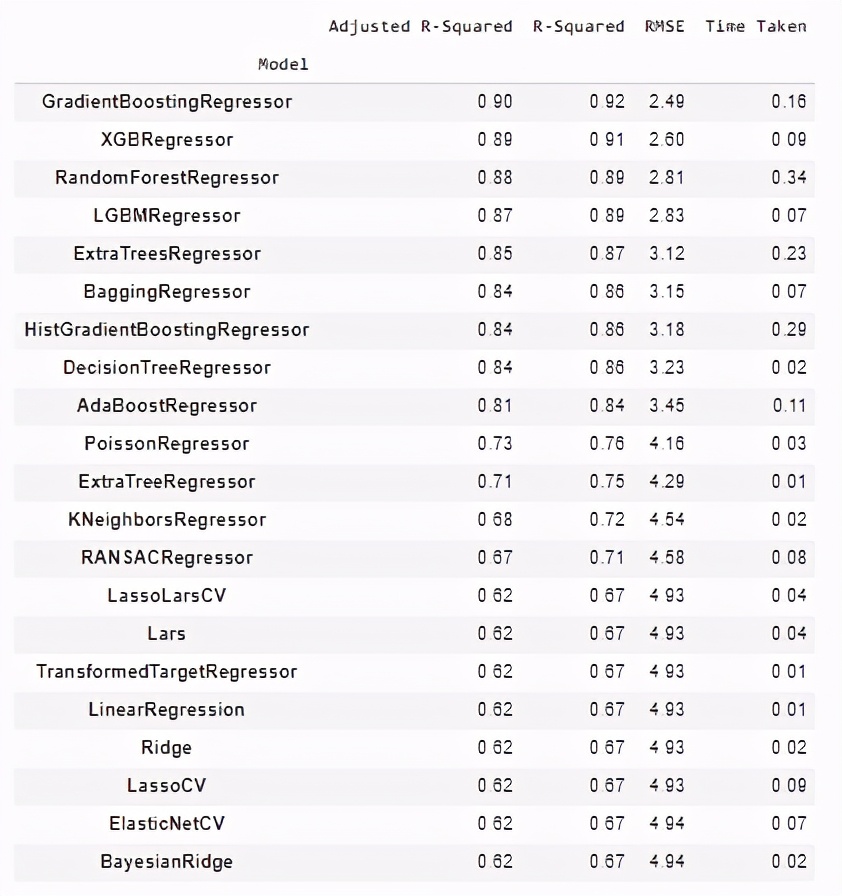
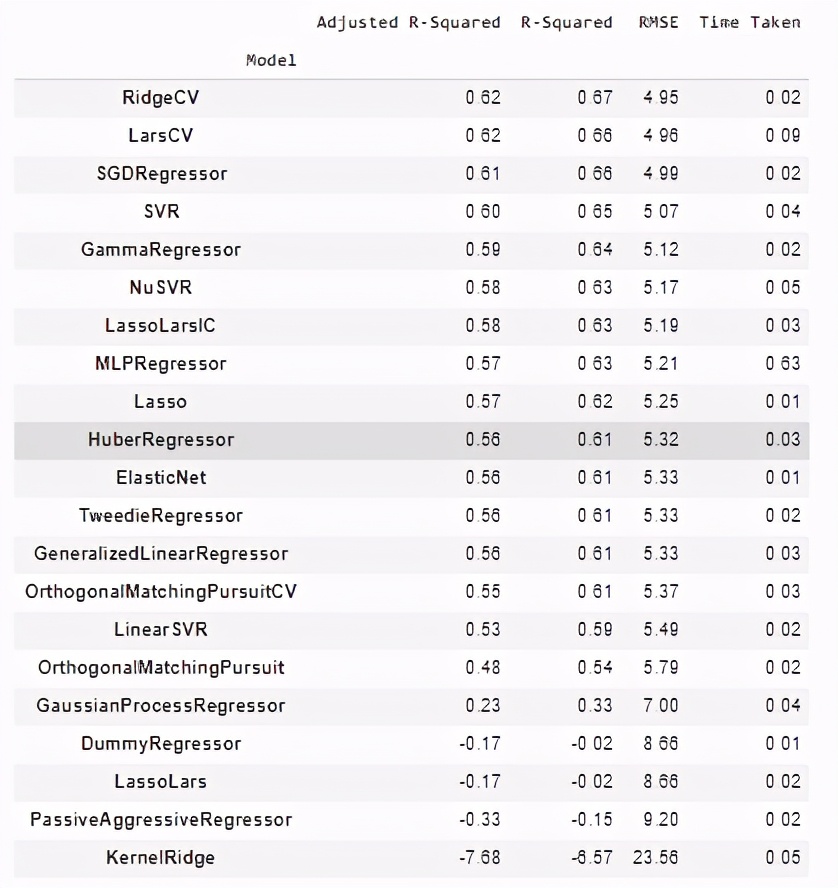
> (Image by Author), Performance metrics of 42 regression models for the Boston Housing dataset
觀察上述性能指標,Adaboost分類器是分類任務的最佳性能模型,漸變增強的替換機策略模型是回歸任務的最佳表現模型。
結論:
在本文中,我們已經討論了LazyPredict庫的實施,這些庫可以在幾行Python代碼中訓練大約70個分類和回歸模型。它是一個非常方便的工具,因為它給出了模型執行的整體情況,并且可以比較每個模型的性能。
每個模型都訓練,默認參數,因為它不執行HyperParameter調整。選擇最佳執行模型后,開發人員可以調整模型以進一步提高性能。
謝謝你的閱讀!
本文翻譯自Christopher Tao的文章《Train all Classification or Regression models in one line of Python Code》。





















