PyTorch如何加速數(shù)據(jù)并行訓(xùn)練?分布式秘籍大揭秘
在芯片性能提升有限的今天,分布式訓(xùn)練成為了應(yīng)對超大規(guī)模數(shù)據(jù)集和模型的主要方法。本文將向你介紹流行深度學(xué)習(xí)框架 PyTorch 最新版本( v1.5)的分布式數(shù)據(jù)并行包的設(shè)計、實(shí)現(xiàn)和評估。

PyTorch 是深度學(xué)習(xí)研究和應(yīng)用中廣泛使用的科學(xué)計算包。深度學(xué)習(xí)的最新進(jìn)展證明了大型數(shù)據(jù)集和大型模型的價值,這需要擴(kuò)展模型訓(xùn)練更多計算資源的能力。
同時,由于簡明的原理和廣泛的適用性,數(shù)據(jù)并行已經(jīng)成為了分布式訓(xùn)練的一種熱門方案。通常,分布式數(shù)據(jù)并行技術(shù)會在每個計算資源上復(fù)制模型以獨(dú)立生成梯度,然后在每次迭代時傳遞這些梯度以保持模型副本的一致性。盡管該技術(shù)在概念上很簡單,但計算和通信之間的細(xì)微依賴關(guān)系使優(yōu)化分布式訓(xùn)練的效率變得不簡單。
因此,在這篇論文中,來自 Facebook AI 和華沙大學(xué)的研究者介紹了 PyTorch 分布式數(shù)據(jù)并行模型的設(shè)計、實(shí)現(xiàn)以及評估。
從 v1.5 開始,PyTorch 自身提供了幾種加速分布數(shù)據(jù)并行的技術(shù),包括分桶梯度(bucketing gradients)、通信重疊計算(overlapping computation with communication)以及跳過梯度同步(skipping gradient synchronization)。相關(guān)評估結(jié)果顯示,在配置正確的情況下,PyTorch 分布式數(shù)據(jù)并行模型可以用 256 個 GPU 達(dá)到接近線性的可擴(kuò)展性。
接下來,我們來看 PyTorch 分布式數(shù)據(jù)并行訓(xùn)練的模型設(shè)計、具體實(shí)現(xiàn)和效果評估。
系統(tǒng)設(shè)計
PyTorch 提供了一個數(shù)據(jù)分布式并行(DistributedDataParalle, DDP)模型來幫助實(shí)現(xiàn)在多個進(jìn)程和機(jī)器的并行訓(xùn)練。在分布訓(xùn)練期間,每個模型都有自己的本地模型副本和本地優(yōu)化器。就糾錯而言,分布式數(shù)據(jù)并行訓(xùn)練和本地訓(xùn)練在數(shù)學(xué)上必須是等價的。
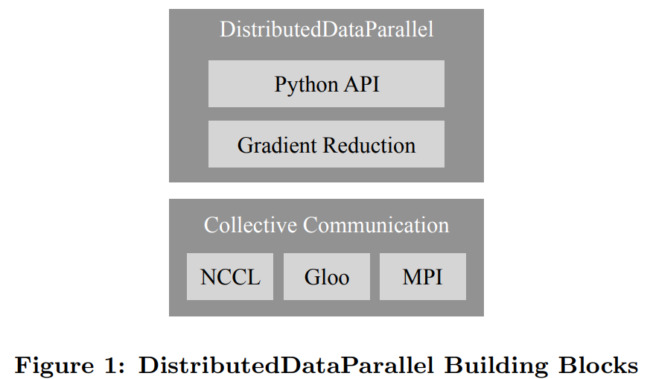
下圖 1 描述了 DDP 構(gòu)造塊的組成,其中包含一個 Python API 前端和 C++ 梯度下降核心算法,并采用了 c10d 聚合通信庫。
Python API 前端
在設(shè)計 API 時,研究者制定了以下兩個設(shè)計目標(biāo)來達(dá)到必要的功能:
非侵入式:對應(yīng)用提供的 API 必須是非侵入式的;
攔截式:API 需要允許攔截各種信號并立即觸發(fā)適當(dāng)?shù)乃惴ā?/p>
分布式數(shù)據(jù)并行化旨在使用更多的計算資源來加速訓(xùn)練。
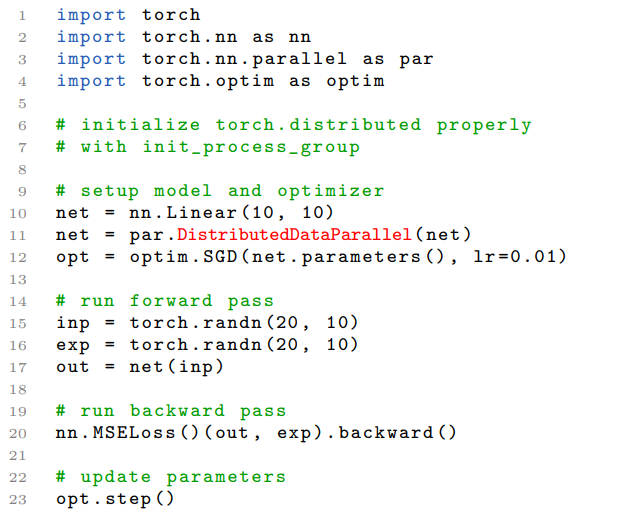
根據(jù)以上需求,研究者用 nn.Module 實(shí)現(xiàn)了分布式數(shù)據(jù)并行。nn.Module 采用本地模型作為構(gòu)造函數(shù)的參數(shù),并在反向傳播中透明地同步梯度。下面的代碼是使用 DDP 模型的示例:
梯度下降
研究者闡述了在 PyTorch 上進(jìn)行分布式數(shù)據(jù)并行訓(xùn)練的幾種梯度降低技術(shù)。DDP 中的梯度下降算法已經(jīng)有了新的改進(jìn)。為了介紹當(dāng)前實(shí)現(xiàn)的結(jié)構(gòu),研究者從一個簡單的初始方案(naive solution)開始,逐步介紹更多復(fù)雜的版本,最終在 PyTorch v1.5.0 上使用當(dāng)前版本。
初始方案
DDP 首先校正了所有的訓(xùn)練進(jìn)程,以保證各個進(jìn)程:
- 從相同的模型狀態(tài)開始;
- 每次迭代花費(fèi)同樣多的梯度。
為了完成第二點(diǎn),初始方案在進(jìn)行本地反向傳播之后、更新本地參數(shù)之前插入了一個梯度同步環(huán)節(jié)。幸運(yùn)的是,PyTorch 的 autograd 引擎能夠接受定制的 backward 鉤子(hook)。DDP 可以注冊 autograd 鉤子來觸發(fā)每次反向傳播之后的計算。然后,它會使用 AllReduce 聚合通信來號召計算所有進(jìn)程中每個參數(shù)的平均梯度,并且把結(jié)果寫回梯度 tensor。
初始方案足以完成想要的目標(biāo),但存在兩項性能缺陷。聚合通信在小型 tensor 上性能表現(xiàn)很差,這種缺陷在帶有大量小參數(shù)的大型模型上尤為突出。由于兩者之間存在界限,分別進(jìn)行梯度計算和同步化會造成通信重疊計算機(jī)會的缺失。
梯度分桶(bucketing )
梯度分桶的觀點(diǎn)是受聚合通信在大型 tensor 上更加高效的啟發(fā)而提出的。
下圖 2(a)和 (b) 給出的定量視圖展示了在每個 AllReduce 中參數(shù)數(shù)目不同的情況下,AllReduce 60M torch 的 float32 參數(shù)的完整執(zhí)行時間:
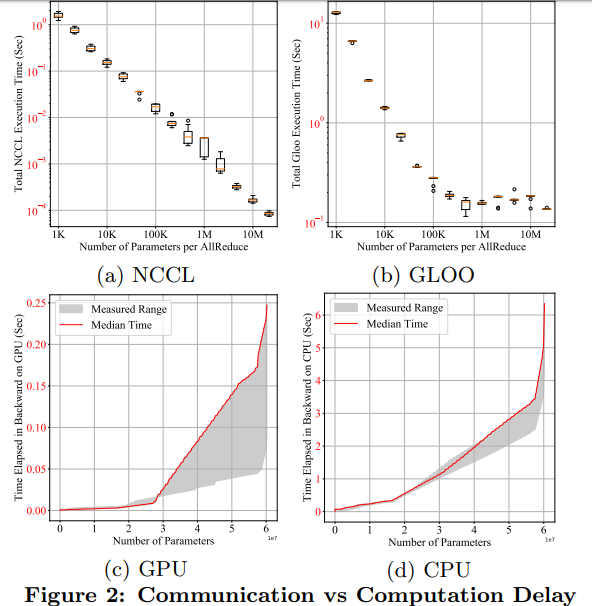
這些實(shí)驗表明,不用等到每個梯度 tensor 都可用時再啟動 AllReduce,DDP 在等待較短的時間并將多個梯度存儲到一個 AllReduce 操作中時,就可以實(shí)現(xiàn)更高的吞吐量和更短的延遲。
通信重疊計算
在使用分桶的情況下,DDP 只需在啟動通信之前在同一個 bucket 中等待所有的內(nèi)容。在這樣的設(shè)置下,在反向傳播的最后觸發(fā) AllReduce 就顯得不足了。因此需要對更加頻繁的信號做出相應(yīng),并且更加迅速地啟動 AllReduce。因此,DDP 為每個梯度累加器都注冊了 autograd 鉤子。
下圖 3(a)的示例中,兩個豎直軸表示時間,虛線代表梯度準(zhǔn)備就緒的時間。進(jìn)程 1 中,4 個梯度按順序計算。進(jìn)程 2 中,g_2 在 g_3 和 g_4 之后計算;圖 3(b)的示例中,梯度 g_3 對應(yīng)的參數(shù)在一次迭代中被跳過了,導(dǎo)致 g_3 的就緒信號缺失。
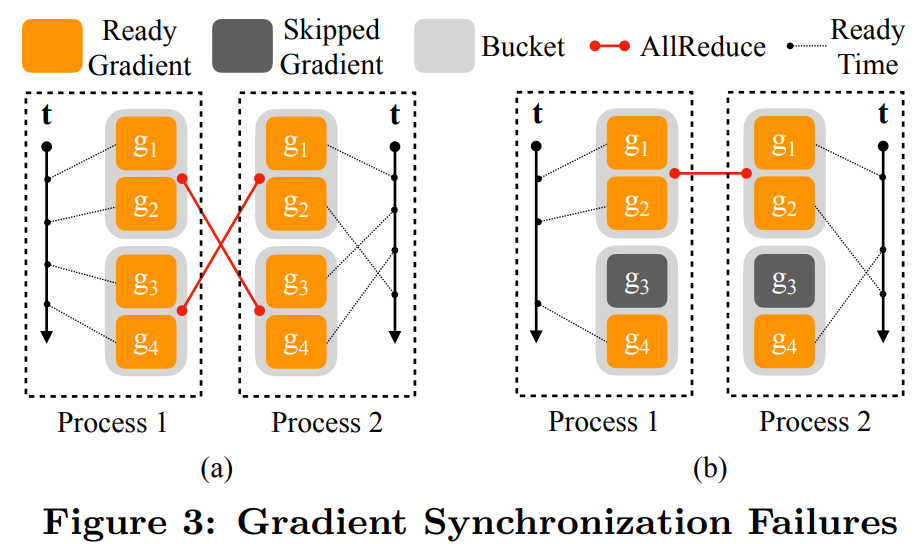
為了解決這個問題,DDP 遍歷了前向傳播的輸出 tensor 中的 autograd 圖以找到涉及到的所有參數(shù)。涉及到 tensor 的就緒狀態(tài)足以充當(dāng)反向傳播完成的信號。
以下算法 1 給出了 DDP 的偽代碼:

下圖 4 展示了 DDP 在前向傳播和反向傳播過程中如何與本地模型交互:
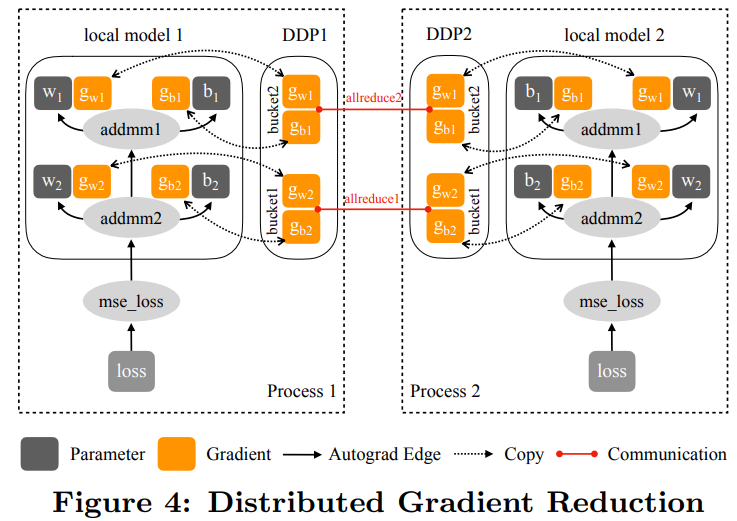
梯度累加
此外,DDP 無法分辨應(yīng)用程序是計劃在反向傳播之后立即調(diào)用 optimizer.step()還是通過多次迭代累加梯度。因此,研究者需要為這個用例再引入一個接口(即 no sync)。以下是樣例代碼片段:

聚合通信
DDP 是在集合通信庫基礎(chǔ)上建立的,包括 3 個選項 NCCL、Gloo 和 MPI。DDP 采用了來自這三個庫的 API,并將它們封裝進(jìn)同一個 ProcessGroup API 中。
由于所有的通信都是聚合操作,因此所有的 ProcessGroup 實(shí)例上的后續(xù)操作必須和其類型匹配并遵循相同的順序。對所有的庫使用同一個 ProcessGroup API 允許研究者在相同的 DDP 實(shí)現(xiàn)上試驗不同的通信算法。
如果單一 NCCL、Gloo 或 MPI 的 ProcessGroup 無法使鏈路容量達(dá)到飽和,通過使用循環(huán)的 ProcessGroups,DDP 可以獲得更高的帶寬利用率。
具體實(shí)現(xiàn)
DDP 的實(shí)現(xiàn)在之前的幾個版本中已經(jīng)改進(jìn)了多次。研究者介紹了當(dāng)前 PyTorch v1.5.0 的狀態(tài)。DDP 同時在 Python 和 C++ 上都可以實(shí)現(xiàn),Python 開放了 API 并組成了非性能關(guān)鍵因素組件,而 C++ 提供了核心梯度下降算法。Python API 通過 Pybind11 的 API 調(diào)用了 C++ 內(nèi)核。
Python 前端
Python 前端中的實(shí)現(xiàn)細(xì)節(jié)決定了 DDP 的行為。可配置的 Knobs 在 DDP 構(gòu)造函數(shù) API 中開放。具體包括:
- 分組處理以找出 DDP 中運(yùn)行 AllReduce 的進(jìn)程組實(shí)例,它能夠幫助避免與默認(rèn)進(jìn)程組混淆;
- bucket_cap_mb 控制 AllReduce 的 bucket 大小,其中的應(yīng)用應(yīng)調(diào)整 knob 來優(yōu)化訓(xùn)練速度;
- 找出沒有用到的參數(shù)以驗證 DDP 是否應(yīng)該通過遍歷 autograd 圖來檢測未用到的參數(shù)。
本地模型中的 Model Device Affinity 也能控制 DDP 的行為,尤其是當(dāng)模型因為太大而需要跨越多個設(shè)備運(yùn)行時,更是如此。對于大型模型,模型的每一層可以放在不同的設(shè)備上,使用 Tensor.to(device) API 可以將中間輸出從一個設(shè)備轉(zhuǎn)移到另一個上。DDP 也可以在多個模型上運(yùn)行。
當(dāng)層(例如 BatchNorm)需要跟蹤狀態(tài),例如運(yùn)行方差和均值時,模型緩沖器(buffer)是非常必要的。DDP 通過讓 rank 為 0 的進(jìn)程獲得授權(quán)來支持模型緩沖器。
核心梯度下降
開發(fā)過程中的主要工作就是梯度降低,它也是 DDP 中決定性能的關(guān)鍵步驟。這個在 reducer.cpp 中的實(shí)現(xiàn)有 4 個主要的組成部分:構(gòu)建 parameter-to-bucket map、安裝 autograd 鉤子,啟動 bucket AllReduce 以及檢測全局未用過的參數(shù)。
Parameter-to-Bucket Mapping 已經(jīng)對 DDP 的速度有了相當(dāng)大的影響。在每次反向傳播中,tensor 從全部的參數(shù)梯度到 bucket 被復(fù)制,平均梯度在 AllReduce 之后又被復(fù)制回 tensor。
Autograd Hook 是 DDP 反向傳播的進(jìn)入點(diǎn)。在構(gòu)造期間,DDP 遍歷模型中的所有參數(shù),找出每個參數(shù)的梯度累加器,并且為每個梯度累加器安裝相同的 post-hook 函數(shù)。當(dāng)相應(yīng)的梯度準(zhǔn)備就緒時,梯度累加器會啟用 post hook,并且當(dāng)整個 bucket 準(zhǔn)備好啟動 AllReduce 操作時,DDP 會確定啟用。
Bucket Allreduce 是 DDP 中通信開銷的主要來源。默認(rèn)情況下,bucket 的大小是 25MB。
實(shí)驗評估
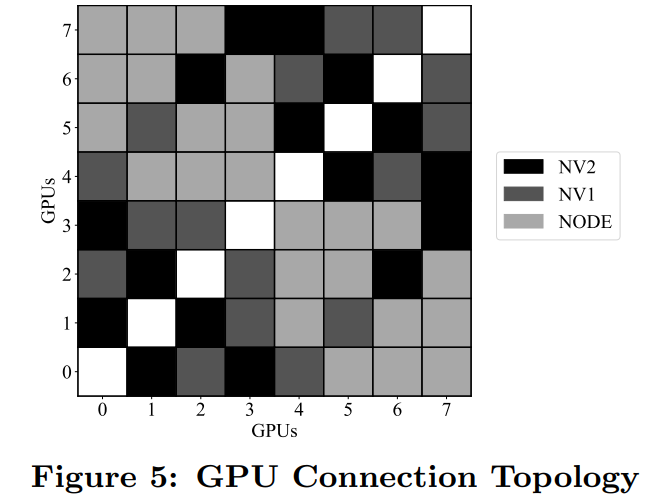
研究者展示了使用專屬 32-GPU 集群和共享權(quán)限時 PyTorch DDP 的評估結(jié)果,其中 GPU 部署在 4 臺服務(wù)器,并通過邁絡(luò)思 MT27700 ConnectX-4 100GB/s 的網(wǎng)卡連接。每臺服務(wù)器配有 8 個英偉達(dá) Tesla V100 GPU。
下圖 5 展示了一臺服務(wù)器上 8 個 GPU 的互連方式:
接下來,研究者利用 ResNet50 和 BERT 這兩個流行的模型度量了 PyTorch DDP 在每次迭代時的延遲和可擴(kuò)展性,并且大多數(shù)實(shí)驗使用隨機(jī)生成的合成輸入和標(biāo)簽,這對于比較每次迭代時的延遲來說足夠了。
延遲故障
為了驗證通信重疊計算的有效性,下圖 6 展示了 ResNet50 和 BERT 模型分別使用 NCCL 和 Gloo 反向傳遞時的延遲故障。所有實(shí)現(xiàn)都用到了 4 臺服務(wù)器上的 32 個 GPU。
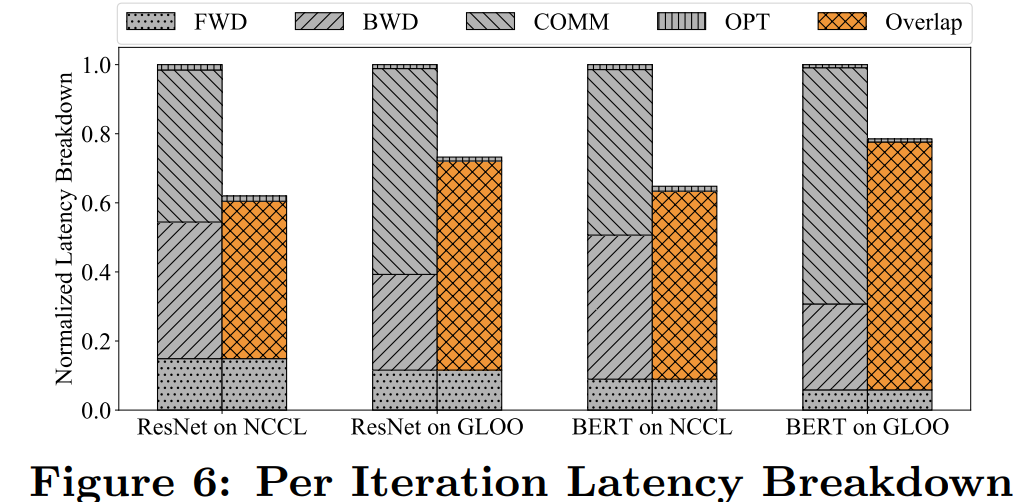
結(jié)果顯示,在 PyTorch DDP 訓(xùn)練時,反向傳遞是耗時最長的步驟,這是因為 AllReduce 通信(即是梯度同步)在這一過程中完成。
Bucket 大小
bucket 大小是一個重要的配置選項。根據(jù)經(jīng)驗,出于最大努力估計,bucket_cap_mb 的默認(rèn)值是 25MB。研究者使用兩臺機(jī)器上的 16 個 GPU 比較不同 bucket 大小下每次迭代的延遲。另一個極端是在短時間內(nèi)傳遞全部的梯度,結(jié)果如下圖 7 所示。
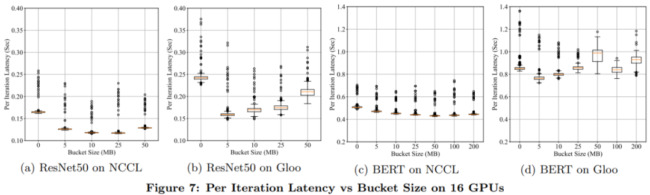
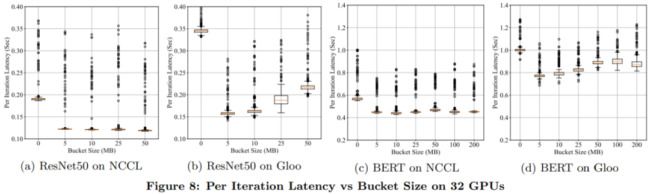
下圖 8 給出了相同設(shè)置下、32 個 GPU 上的實(shí)驗結(jié)果。在這種情況下,離群值(outlier)的跨度更大,這并不意外。因為在有更多參與者的情況下,同步必然要花費(fèi)更長的時間,并且 strangler 的影響更明顯。
可擴(kuò)展性
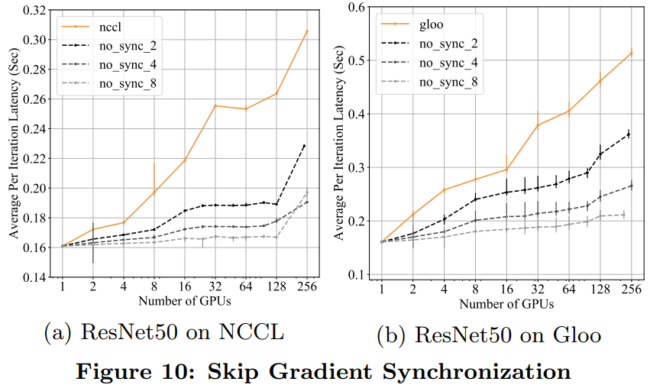
為了理解 DDP 的可擴(kuò)展性,研究者用多達(dá) 256 個 GPU 上的 NCCL 和 Gloo 后端來度量 ResNet50 和 BERT 每次迭代的訓(xùn)練延遲。結(jié)果如下圖 9 所示。

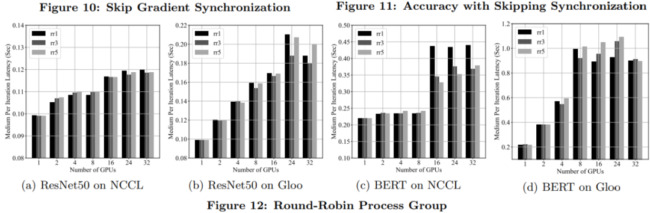
下圖 10 給出了每 1、2、4 和 8 次迭代進(jìn)行梯度下降時每次迭代的平均延遲。
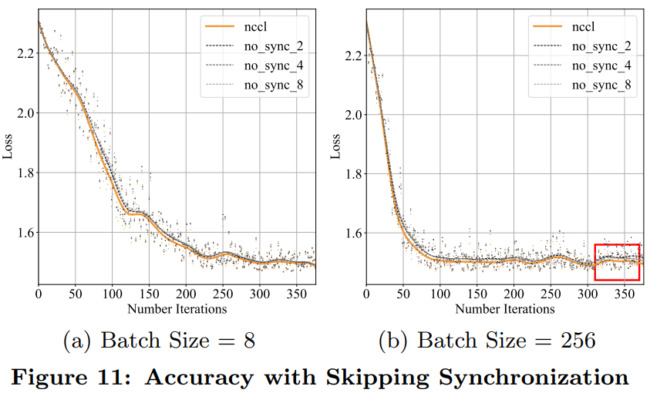
除了每次迭代延遲,測量收斂速度以驗證加速度是否會因收斂放緩而被消除也非常關(guān)鍵。實(shí)驗采用 MNIST 數(shù)據(jù)集來訓(xùn)練 ResNet。學(xué)習(xí)率設(shè)置為 0.02,批處理大小是 8。結(jié)果如下圖 11(a)所示;圖 11(b)是將批處理大小設(shè)為 256,學(xué)習(xí)率設(shè)為 0.06 的測量結(jié)果。
循環(huán)分配(Round-Robin)進(jìn)程組
PyTorch 分布式包支持將 Round-Robin 進(jìn)程組和多個 NCCL 或 Gloo 進(jìn)程組組合在一起,從而按照 Robin-Robin 順序向各個進(jìn)程組實(shí)例分配聚合通信。
下圖 12 展示了使用 1、3 和 5 個 NCCL 或 Gloo 進(jìn)程組的 Round-Robin 進(jìn)程組每次迭代的延遲。最顯著的加速是使用 NCCL 后端的 BERT 模型。