調(diào)研了10家公司的技術(shù)架構(gòu),我總結(jié)出了一套大數(shù)據(jù)平臺的套路
近年來,隨著IT技術(shù)與大數(shù)據(jù)、機器學(xué)習(xí)、算法方向的不斷發(fā)展,越來越多的企業(yè)都意識到了數(shù)據(jù)存在的價值,將數(shù)據(jù)作為自身寶貴的資產(chǎn)進行管理,利用大數(shù)據(jù)和機器學(xué)習(xí)能力去挖掘、識別、利用數(shù)據(jù)資產(chǎn)。
如果缺乏有效的數(shù)據(jù)整體架構(gòu)設(shè)計或者部分能力缺失,會導(dǎo)致業(yè)務(wù)層難以直接利用大數(shù)據(jù)大數(shù)據(jù),大數(shù)據(jù)和業(yè)務(wù)產(chǎn)生了巨大的鴻溝,這道鴻溝的出現(xiàn)導(dǎo)致企業(yè)在使用大數(shù)據(jù)的過程中出現(xiàn)數(shù)據(jù)不可知、需求難實現(xiàn)、數(shù)據(jù)難共享等一系列問題,本文介紹了一些數(shù)據(jù)平臺設(shè)計思路來幫助業(yè)務(wù)減少數(shù)據(jù)開發(fā)中的痛點和難點。
我調(diào)研了10家公司,寫出了這篇文章。
一、大數(shù)據(jù)技術(shù)棧
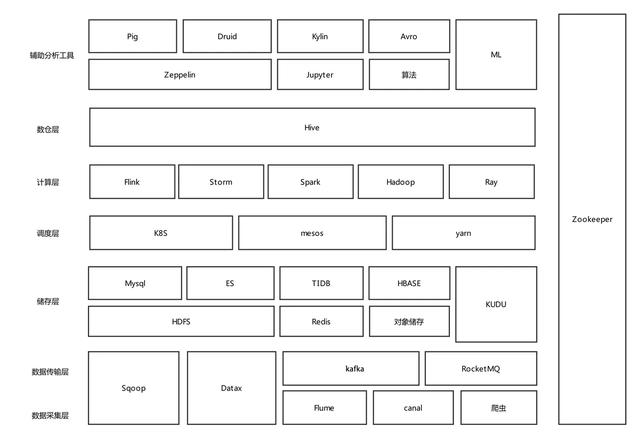
大數(shù)據(jù)整體流程涉及很多模塊,每一個模塊都比較復(fù)雜,下圖列出這些模塊和組件以及他們的功能特性,后續(xù)會有專題去詳細(xì)介紹相關(guān)模塊領(lǐng)域知識,例如數(shù)據(jù)采集、數(shù)據(jù)傳輸、實時計算、離線計算、大數(shù)據(jù)儲存等相關(guān)模塊。
二、lambda架構(gòu)和kappa架構(gòu)
目前基本上所有的大數(shù)據(jù)架構(gòu)都是基于lambda和kappa架構(gòu),不同公司在這兩個架構(gòu)模式上設(shè)計出符合該公司的數(shù)據(jù)體系架構(gòu)。lambda 架構(gòu)使開發(fā)人員能夠構(gòu)建大規(guī)模分布式數(shù)據(jù)處理系統(tǒng)。
它具有很好的靈活性和可擴展性,也對硬件故障和人為失誤有很好的容錯性,關(guān)于lambda架構(gòu)可以在網(wǎng)上搜到很多相關(guān)文章。而kappa架構(gòu)解決了lambda架構(gòu)存在的兩套數(shù)據(jù)加工體系,從而帶來的各種成本問題,這也是目前流批一體化研究方向,很多企業(yè)已經(jīng)開始使用這種更為先進的架構(gòu)。
Lambda架構(gòu)
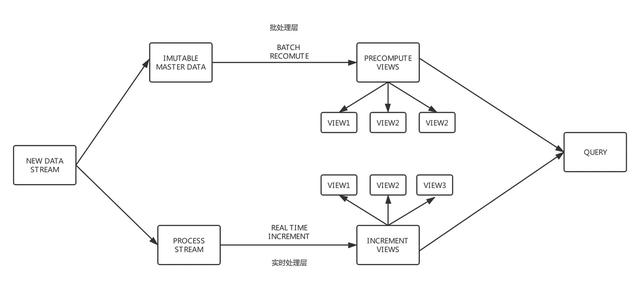
Kappa架構(gòu)
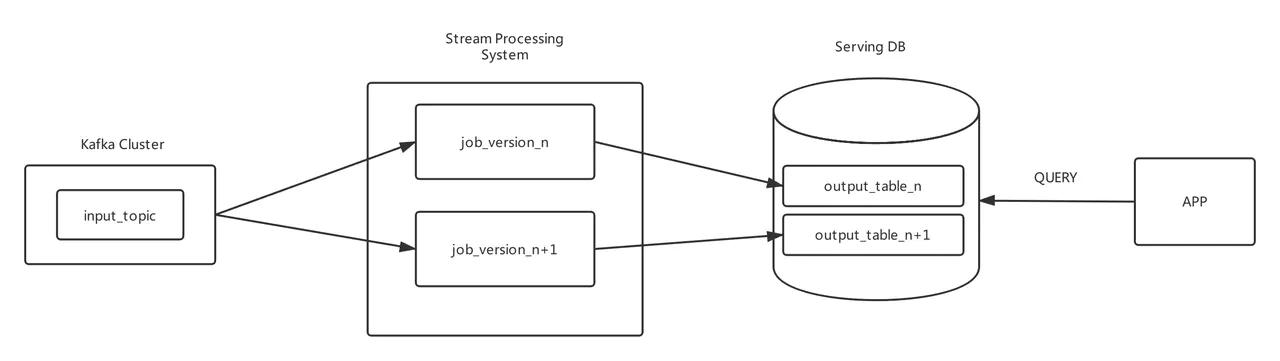
三、kappa架構(gòu)和lambda架構(gòu)下的大數(shù)據(jù)架構(gòu)
目前各大公司基本上都是使用kappa架構(gòu)或者lambda架構(gòu)模式,這兩種模式下大數(shù)據(jù)整體架構(gòu)在早期發(fā)展階段可能是下面這樣的:
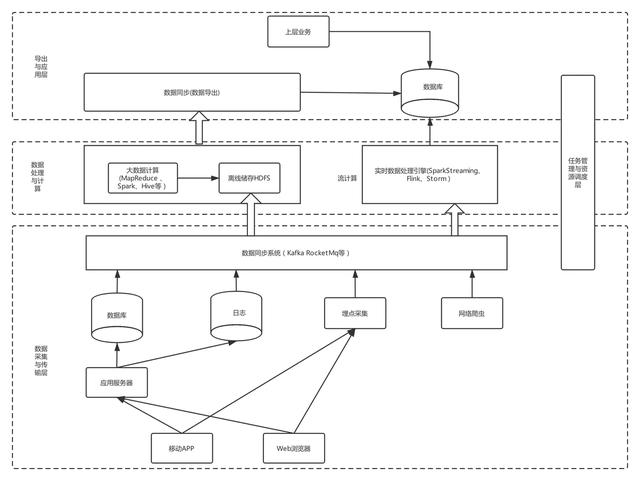
四、數(shù)據(jù)端到端痛點
雖然上述架構(gòu)看起來將多種大數(shù)據(jù)組件串聯(lián)起來實行了一體化管理,但是接觸過數(shù)據(jù)開發(fā)的人會感受比較強烈,這樣的裸露架構(gòu)業(yè)務(wù)數(shù)據(jù)開發(fā)需要關(guān)注很多基礎(chǔ)工具的使用,實際數(shù)據(jù)開發(fā)中存在很多痛點與難點,具體表現(xiàn)在下面一些方面。
- 缺乏一套數(shù)據(jù)開發(fā)IDE來管理整個數(shù)據(jù)開發(fā)環(huán)節(jié),長遠(yuǎn)的流程無法管理起來。
- 沒有產(chǎn)生標(biāo)準(zhǔn)數(shù)據(jù)建模體系,導(dǎo)致不同數(shù)據(jù)工程師對指標(biāo)理解不同計算口徑有誤。
- 大數(shù)據(jù)組件開發(fā)要求高,普通業(yè)務(wù)去直接使用Hbase、ES等技術(shù)組件會產(chǎn)生各種問題。
- 基本上每個公司大數(shù)據(jù)團隊都會很復(fù)雜,涉及到很多環(huán)節(jié),遇到問題難以定位難以找到對應(yīng)負(fù)責(zé)人。
- 難以打破數(shù)據(jù)孤島,跨團隊跨部門數(shù)據(jù)難以共享,互相不清楚對方有什么數(shù)據(jù)。
- 需要維護兩套計算模型批計算和流計算,難以上手開發(fā),需要提供一套流批統(tǒng)一的SQL。
- 缺乏公司層面的元數(shù)據(jù)體系規(guī)劃,同一條數(shù)據(jù)實時和離線難以復(fù)用計算,每次開發(fā)任務(wù)都要各種梳理。
基本上大多數(shù)公司在數(shù)據(jù)平臺治理上和提供開放能力上都存在上述問題和痛點。在復(fù)雜的數(shù)據(jù)架構(gòu)下,對于數(shù)據(jù)適用方來說,每一個環(huán)節(jié)的不清晰或者一個功能的不友好,都會讓復(fù)雜鏈路變更更加復(fù)雜起來。想要解決這些痛點,就需要精心打磨每一個環(huán)節(jié),將上面技術(shù)組件無縫銜接起來,讓業(yè)務(wù)從端到端使用數(shù)據(jù)就像寫SQL查詢數(shù)據(jù)庫一樣簡單。
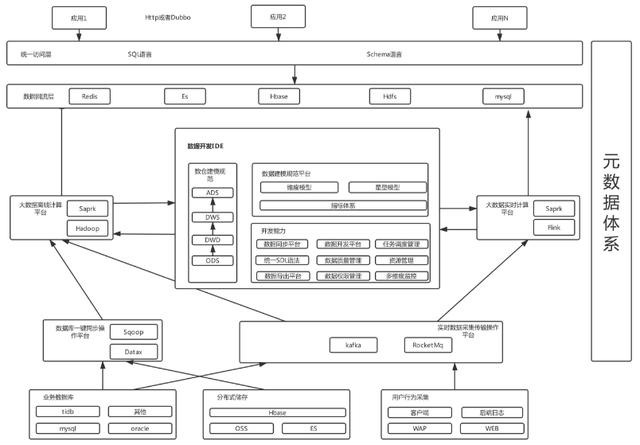
五、優(yōu)秀的大數(shù)據(jù)整體架構(gòu)設(shè)計
提供多種平臺以及工具來助力數(shù)據(jù)平臺:多種數(shù)據(jù)源的數(shù)據(jù)采集平臺、一鍵數(shù)據(jù)同步平臺、數(shù)據(jù)質(zhì)量和建模平臺、元數(shù)據(jù)體系、數(shù)據(jù)統(tǒng)一訪問平臺、實時和離線計算平臺、資源調(diào)度平臺、一站式開發(fā)IDE。
六、元數(shù)據(jù)-大數(shù)據(jù)體系基石
元數(shù)據(jù)是打通數(shù)據(jù)源、數(shù)據(jù)倉庫、數(shù)據(jù)應(yīng)用,記錄了數(shù)據(jù)從產(chǎn)生到消費的完整鏈路。元數(shù)據(jù)包含靜態(tài)的表、列、分區(qū)信息(也就是MetaStore)。
動態(tài)的任務(wù)、表依賴映射關(guān)系;數(shù)據(jù)倉庫的模型定義、數(shù)據(jù)生命周期;以及ETL任務(wù)調(diào)度信息、輸入輸出等元數(shù)據(jù)是數(shù)據(jù)管理、數(shù)據(jù)內(nèi)容、數(shù)據(jù)應(yīng)用的基礎(chǔ)。例如可以利用元數(shù)據(jù)構(gòu)建任務(wù)、表、列、用戶之間的數(shù)據(jù)圖譜;構(gòu)建任務(wù)DAG依賴關(guān)系,編排任務(wù)執(zhí)行序列;構(gòu)建任務(wù)畫像,進行任務(wù)質(zhì)量治理;提供個人或BU的資產(chǎn)管理、計算資源消耗概覽等。
可以認(rèn)為整個大數(shù)據(jù)數(shù)據(jù)流動都是依靠元數(shù)據(jù)來管理的,沒有一套完整的元數(shù)據(jù)設(shè)計,就會出現(xiàn)上面的數(shù)據(jù)難以追蹤、權(quán)限難以把控、資源難以管理、數(shù)據(jù)難以共享等等問題。
很多公司都是依靠hive來管理元數(shù)據(jù),但是個人認(rèn)為在發(fā)展一定階段還是需要自己去建設(shè)元數(shù)據(jù)平臺來匹配相關(guān)的架構(gòu)。
七、流批一體化計算
如果維護兩套計算引擎例如離線計算Spark和實時計算Flink,那么會對使用者造成極大困擾,既需要學(xué)習(xí)流計算知識也需要批計算領(lǐng)域知識。
如果實時用Flink離線用Spark或者Hadoop,可以開發(fā)一套自定義的DSL描述語言去匹配不同計算引擎語法,上層使用者無需關(guān)注底層具體的執(zhí)行細(xì)節(jié),只需要掌握一門DSL語言,就可以完成Spark和Hadoop以及Flink等等計算引擎的接入。
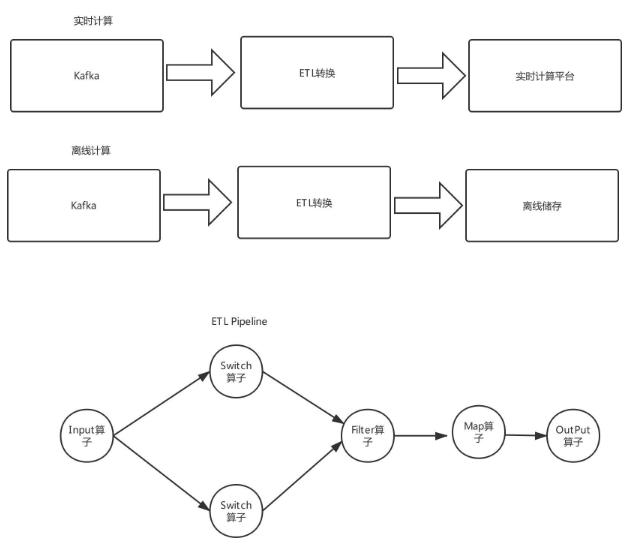
八、實時與離線ETL平臺
ETL 即 Extract-Transform-Load,用來描述將數(shù)據(jù)從來源端經(jīng)過抽取(extract)、轉(zhuǎn)換(transform)、加載(load)至目的端的過程。ETL 一詞較常用在數(shù)據(jù)倉庫,但其對象并不限于數(shù)據(jù)倉庫。一般而言ETL平臺在數(shù)據(jù)清洗、數(shù)據(jù)格式轉(zhuǎn)換、數(shù)據(jù)補全、數(shù)據(jù)質(zhì)量管理等方面有很重要作用。作為重要的數(shù)據(jù)清洗中間層,一般而言ETL最起碼要具備下面幾個功能:
- 支持多種數(shù)據(jù)源,例如消息系統(tǒng)、文件系統(tǒng)等
- 支持多種算子,過濾、分割、轉(zhuǎn)換、輸出、查詢數(shù)據(jù)源補全等算子能力
- 支持動態(tài)變更邏輯,例如上述算子通過動態(tài)jar方式提交可以做到不停服發(fā)布變更。
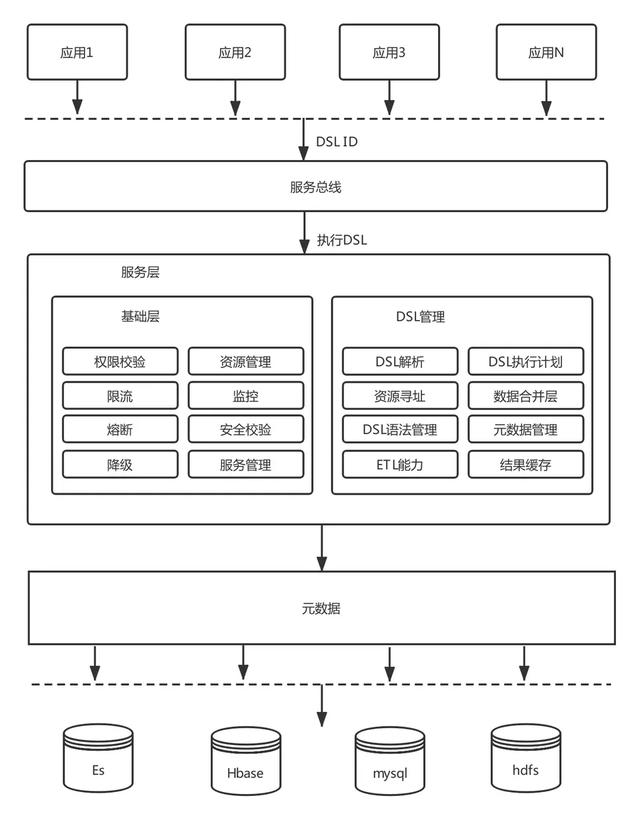
九、智能統(tǒng)一查詢平臺
大多數(shù)數(shù)據(jù)查詢都是由需求驅(qū)動,一個需求開發(fā)一個或者幾個接口,編寫接口文檔,開放給業(yè)務(wù)方調(diào)用,這種模式在大數(shù)據(jù)體系下存在很多問題:
- 這種架構(gòu)簡單,但接口粒度很粗,靈活性不高,擴展性差,復(fù)用率低.隨著業(yè)務(wù)需求的增加,接口的數(shù)量大幅增加,維護成本高企。
- 同時,開發(fā)效率不高,這對于海量的數(shù)據(jù)體系顯然會造成大量重復(fù)開發(fā),難以做到數(shù)據(jù)和邏輯復(fù)用,嚴(yán)重降低業(yè)務(wù)適用方體驗。
- 如果沒有統(tǒng)一的查詢平臺直接將Hbase等庫暴露給業(yè)務(wù),后續(xù)的數(shù)據(jù)權(quán)限運維管理也會比較難,接入大數(shù)據(jù)組件對于業(yè)務(wù)適用方同樣很痛苦,稍有不慎就會出現(xiàn)各種問題。
通過一套智能查詢解決上述大數(shù)據(jù)查詢痛點問題
十、數(shù)倉建模規(guī)范體系
隨著業(yè)務(wù)復(fù)雜度和數(shù)據(jù)規(guī)模上升,混亂的數(shù)據(jù)調(diào)用和拷貝,重復(fù)建設(shè)帶來的資源浪費,數(shù)據(jù)指標(biāo)定義不同而帶來的歧義、數(shù)據(jù)使用門檻越來越高。以筆者見證實際業(yè)務(wù)埋點和數(shù)倉使用為例,同一個商品名稱有些表字段是good_id,有些叫spu_id,還有很多其他命名,對于想利用這些數(shù)據(jù)人會造成極大困擾。因此沒有一套完整的大數(shù)據(jù)建模體系,會給數(shù)據(jù)治理帶來極大困難,具體表現(xiàn)在下面幾個方面:
- 數(shù)據(jù)標(biāo)準(zhǔn)不一致,即使是同樣的命名,但定義口徑卻不一致。例如,僅uv這樣一個指標(biāo),就有十幾種定義。帶來的問題是:都是uv,我要用哪個?都是uv,為什么數(shù)據(jù)卻不一樣?
- 造成巨大研發(fā)成本,每個工程師都需要從頭到尾了解研發(fā)流程的每個細(xì)節(jié),對同樣的“坑”每個人都會重新踩一遍,對研發(fā)人員的時間和精力成本造成浪費。這也是目標(biāo)筆者遇到的困擾,想去實際開發(fā)提取數(shù)據(jù)太難。
- 沒有統(tǒng)一的規(guī)范標(biāo)準(zhǔn)管理,造成了重復(fù)計算等資源浪費。而數(shù)據(jù)表的層次、粒度不清晰,也使得重復(fù)存儲嚴(yán)重。
因此大數(shù)據(jù)開發(fā)和數(shù)倉表設(shè)計必須要堅持設(shè)計原則,數(shù)據(jù)平臺可以開發(fā)平臺來約束不合理的設(shè)計,例如阿里巴巴的OneData體。一般而言,數(shù)據(jù)開發(fā)要經(jīng)過按照下面的指導(dǎo)方針進行: