宜信公司從2018年初開始建設(shè)容器云,至今,容器云的常用基本功能已經(jīng)趨于完善,主要包括服務(wù)管理、應(yīng)用商店、Nginx配置、存儲管理、CI/CD、權(quán)限管理等,支持100+業(yè)務(wù)線、3500+的容器運(yùn)行。
主講人介紹
[[287112]]
陳曉宇:宜信高級架構(gòu)師 & 宜信PaaS平臺負(fù)責(zé)人
導(dǎo)讀:宜信公司從2018年初開始建設(shè)容器云,至今,容器云的常用基本功能已經(jīng)趨于完善,主要包括服務(wù)管理、應(yīng)用商店、Nginx配置、存儲管理、CI/CD、權(quán)限管理等,支持100+業(yè)務(wù)線、3500+的容器運(yùn)行。伴隨公司去VMware以及DevOps、微服務(wù)不斷推進(jìn)的背景,后續(xù)還會有更多的業(yè)務(wù)遷移到容器云上,容器云在宜信發(fā)揮著越來越重要的作用。本次分享將圍繞容器云展開,主要介紹其設(shè)計思想、技術(shù)架構(gòu)和核心功能,以及容器云在宜信落地的實踐經(jīng)驗。
分享大綱:
一、宜信容器云平臺背景
二、宜信容器云平臺主要功能
三、容器容器云平臺落地實踐
四、宜信容器云未來規(guī)劃
以下為直播視頻,可點擊回放,時長59m21s,建議在WiFi環(huán)境下觀看。
分享實錄
宜信公司從2018年初開始建設(shè)容器云,至今,容器云的常用基本功能已經(jīng)趨于完善,主要包括服務(wù)管理、應(yīng)用商店、Nginx配置、存儲管理、CI/CD、權(quán)限管理等,支持100+業(yè)務(wù)線、3500+的容器運(yùn)行。伴隨公司去VMware以及DevOps、微服務(wù)不斷推進(jìn)的背景,后續(xù)還會有更多的業(yè)務(wù)遷移到容器云上,容器云在宜信發(fā)揮著越來越重要的作用。本次分享主要介紹宜信容器云平臺的背景、主要功能、落地實踐及未來規(guī)劃。
一、容器云平臺的產(chǎn)生背景
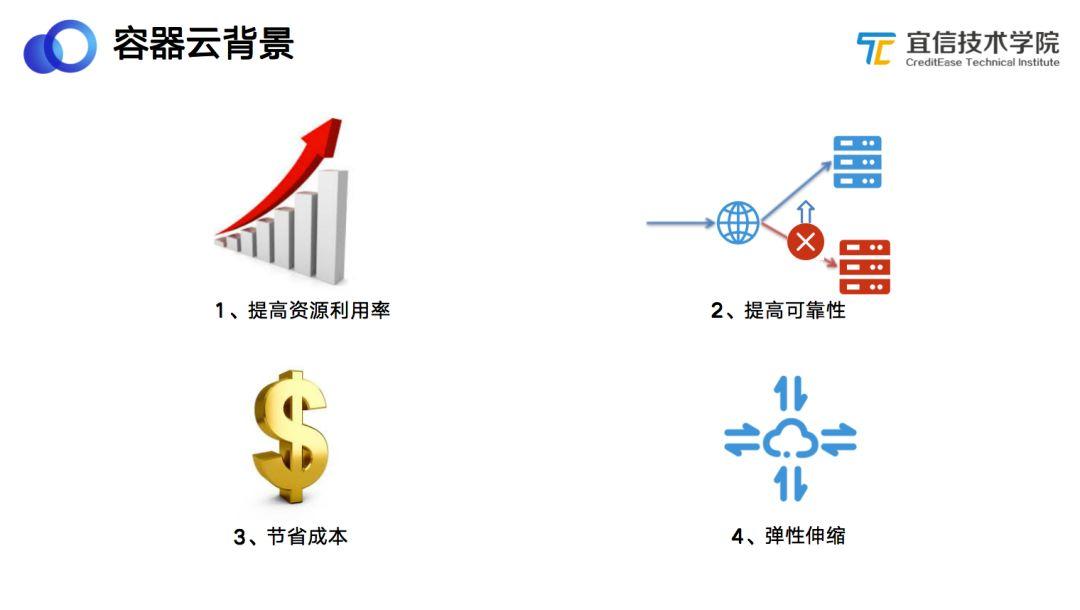
宜信容器云平臺的建設(shè)背景主要包括:
- 提高資源利用率。容器云建設(shè)之前,每臺物理機(jī)上平均運(yùn)行的虛擬機(jī)大概是20個,使用了容器云之后,每臺物理機(jī)上平均運(yùn)行的容器數(shù)達(dá)到50個;之前的CPU利用率大概在10%左右,遷移到容器云后,CPU利用率提高到20%以上,整個資源利用率得到了極大的提升。
- 提升服務(wù)可靠性。傳統(tǒng)的虛擬機(jī)運(yùn)維方式下,當(dāng)機(jī)器宕機(jī)或系統(tǒng)故障時,需要運(yùn)維手動重啟虛擬機(jī)和服務(wù),整個過程最快需要幾十分鐘到幾個小時才能解決;使用容器云后,通過健康檢查的方式,一旦發(fā)現(xiàn)有問題就自動重啟恢復(fù)服務(wù),可以達(dá)到分鐘級甚至秒級的恢復(fù)。
- 節(jié)約成本。通過容器云提高了資源利用率,同時也節(jié)約了成本。公司每年會采購一些商業(yè)化軟件,如虛擬化軟件、商業(yè)存儲等,費(fèi)用動輒千萬。我們基于開源技術(shù)自研一套容器解決方案,每年為公司節(jié)省上千萬的軟件采購和維保費(fèi)用。
- 彈性伸縮。我們公司每年都會組織財富峰會,在這里有一個很經(jīng)典的場景:秒殺,秒殺場景需要很快擴(kuò)展業(yè)務(wù)的計算能力。為了快速應(yīng)對互聯(lián)網(wǎng)突發(fā)流量,如上述的財富峰會、APP線上活動,我們?yōu)榉?wù)設(shè)置了自動伸縮的策略:當(dāng)CPU利用率達(dá)到60%的時候,自動做容器擴(kuò)容,應(yīng)對突發(fā)的業(yè)務(wù)流量,提高響應(yīng)速度;活動過后,自動回收資源,提高資源的利用率。
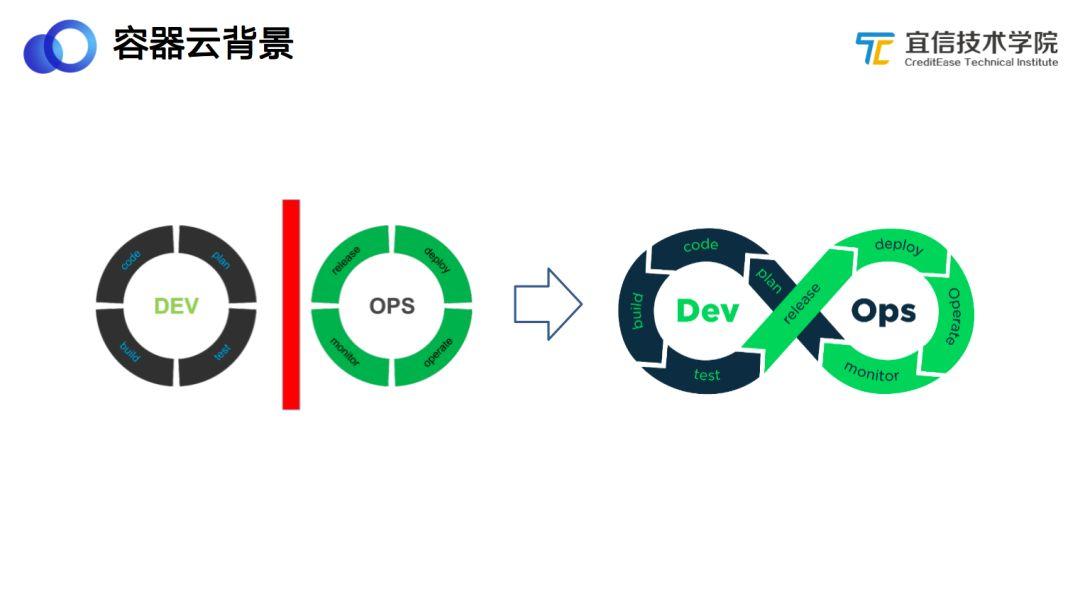
- DevOps整合。DevOps和敏捷開發(fā)的理論已經(jīng)提出很多年了,為什么DevOps一直沒有得到很好的推進(jìn)和實踐呢?因為缺乏一種工具把Dev和Ops聯(lián)系起來,而容器的誕生很好地解決了這個問題。開發(fā)人員在開發(fā)完代碼并完成測試以后,可以拿著測試的產(chǎn)物直接到生產(chǎn)環(huán)境部署上線,而部署的問題可以直接反饋給開發(fā),形成閉環(huán)。也就是說,通過容器的方式,可以實現(xiàn)一次構(gòu)建多次運(yùn)行。由此可見,通過容器的方式實現(xiàn)DevOps是最佳的方案,企業(yè)亟需一套成熟的平臺幫助開發(fā)和運(yùn)維人員保持各個環(huán)境的一致性和快速發(fā)布、快速回滾。
在上述背景下,我們結(jié)合宜信的業(yè)務(wù)場景開發(fā)建設(shè)宜信容器云平臺。
二、宜信容器云平臺主要功能
宜信容器云平臺經(jīng)過一年多時間的建設(shè)和開發(fā),基本的常用功能已經(jīng)具備。如圖所示。
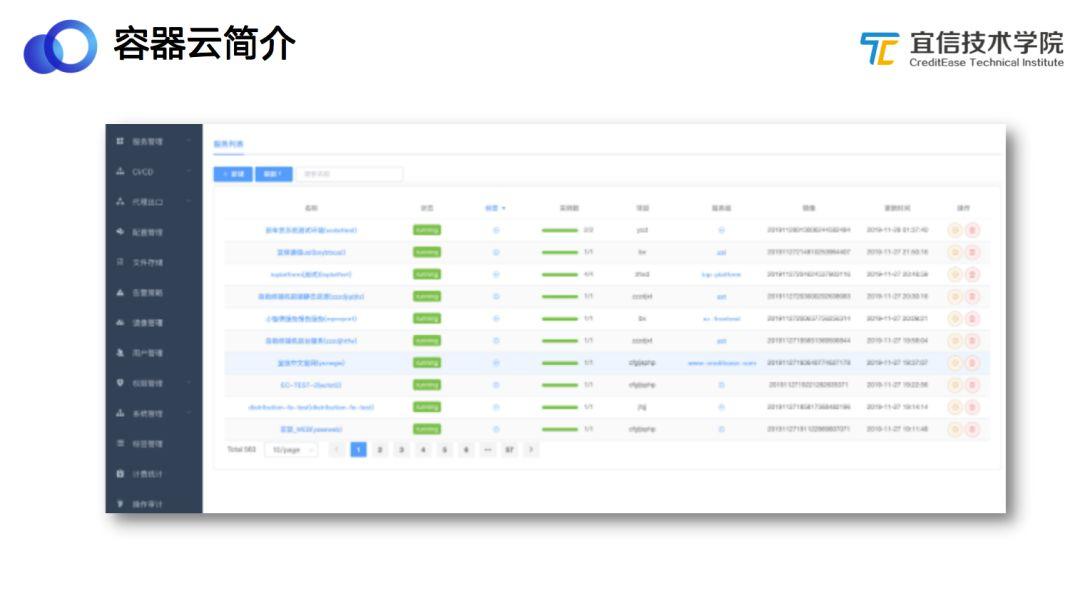
上圖左側(cè)是宜信容器云平臺的主要功能,包括:服務(wù)管理、CI/CD、代理出口、配置管理、文件存儲、告警策略、鏡像管理、用戶管理、權(quán)限管理、系統(tǒng)管理等。右側(cè)是一個服務(wù)管理的界面,從中可以看到服務(wù)列表、服務(wù)名稱、服務(wù)狀態(tài)及當(dāng)前服務(wù)數(shù)量,還有當(dāng)前鏡像版本及更新時間。
2.1 宜信容器云平臺架構(gòu)
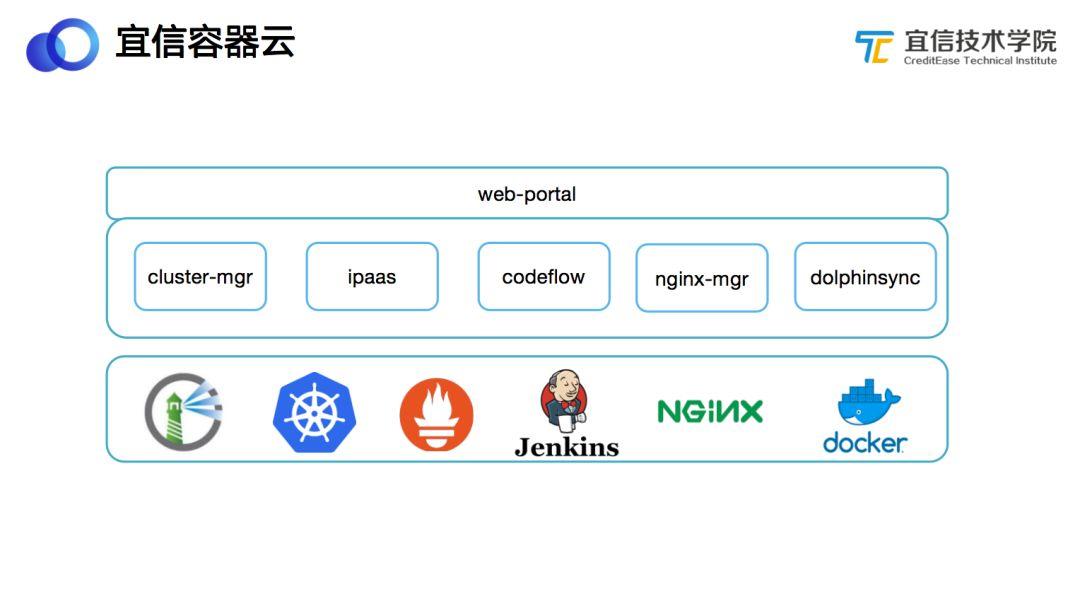
上圖所示為整個容器云平臺的架構(gòu)圖,在各種開源組件(包括Harbor鏡像倉庫、Kubernetes容器管理、Prometheus 監(jiān)控、Jenkins構(gòu)建、Nginx流量轉(zhuǎn)發(fā)和Docker容器虛擬化等)的基礎(chǔ)之上,我們自研開發(fā)了5個核心模塊。
- Cluster-mgr,負(fù)責(zé)多個Kubernetes集群之間的管理和調(diào)度,在一個Kubernetes集群出現(xiàn)問題后,將該集群的容器遷移到其他可用的Kubernetes集群,并且負(fù)責(zé)資源的計量。
- Ipaas,負(fù)責(zé)對接各種資源,如調(diào)用Kubernetes API創(chuàng)建容器、對接Ceph創(chuàng)建存儲、對接Harbor獲取鏡像等。前端頁面通過Ipaas獲取容器相關(guān)的新聞數(shù)據(jù)、監(jiān)控指標(biāo)等。
- Codeflow,負(fù)責(zé)代碼構(gòu)建。通過對接Jenkins實現(xiàn)代碼編譯、打包鏡像以及服務(wù)的滾動升級等工作。
- Nginx-mgr,一個對接多個Nginx集群的管理系統(tǒng),負(fù)責(zé)將用戶在頁面配置的規(guī)則轉(zhuǎn)成Nginx配置,并下發(fā)到對應(yīng)的Nginx集群。
- Dophinsync,和公司CMDB系統(tǒng)打通,從CMDB系統(tǒng)同步公司所有項目和服務(wù)的相關(guān)數(shù)據(jù)和信息。
最上面是對用戶提供的web-portal頁面,一個用戶自助的終端。本次分享的標(biāo)題是《宜信容器云的A點與B點》,之所以稱為A點和B點,這與我們的公司文化有關(guān),我們以“A點”代指現(xiàn)在已經(jīng)做到的事情,以“B點”代指未來或者下個階段要做的事情。目前整個宜信容器云平臺已經(jīng)完成了大部分主要功能點的開發(fā),這部分已經(jīng)實現(xiàn)的功能即為“A點”,包括服務(wù)管理、應(yīng)用商店、域名管理、CI/CD、鏡像管理、文件存儲、監(jiān)控告警、定時任務(wù)、配置管理等。后續(xù)還有部分功能需要添加和完善,即為“B點”,主要包括:對象存儲、大數(shù)據(jù)容器云、全面日志收集、自定義指標(biāo)伸縮、智能調(diào)度和混部、多集群管理、安全隔離、站點監(jiān)控等。
2.2 宜信容器云功能模塊
上圖為宜信容器云平臺的整體功能圖,其中藍(lán)色代表已經(jīng)完成的功能、黃色代表需要優(yōu)化和改善的功能。
- 底層是硬件層面的計算、存儲、網(wǎng)絡(luò);
- 其上是資源管理層,負(fù)責(zé)容器、存儲、域名、鏡像、集群管理;
- 往上是中間件層,包括Kafka、MySQL等中間件服務(wù);
- 再往上是應(yīng)用層,提供給用戶使用的終端;
- 兩側(cè)分別是CI/CD的構(gòu)建流程和安全認(rèn)證相關(guān)的功能組件。
下面將通過頁面截圖的方式,詳細(xì)介紹容器云的主要功能點。
2.2.1 主要功能點——服務(wù)管理
上圖是服務(wù)管理頁面的截圖,逐一介紹各個功能。
- 容器列表。上側(cè)的菜單是服務(wù)管理的列表,進(jìn)入到某一個服務(wù)管理,就可以對服務(wù)進(jìn)行具體操作,包括基本配置、升級、擴(kuò)縮容、域名管理、同步生產(chǎn)環(huán)境等。
- 歷史容器。服務(wù)升級或故障遷移之后,容器的名稱、IP地址等會發(fā)生變化,歷史容器的功能是記錄一個服務(wù)下面容器的變化情況,方便我們追蹤容器的變化,追溯性能監(jiān)控數(shù)據(jù),進(jìn)行故障定位。
- 日志下載。可以通過頁面方式直接下載用戶日志數(shù)據(jù)。終端信息與前面的日志輸出是有區(qū)別的。前面的日志下載是應(yīng)用把日志保存到容器里的某一個指定路徑下;終端信息是容器標(biāo)準(zhǔn)輸出的日志,Event信息里主要記錄容器的狀態(tài)信息,比如什么時候拉取鏡像、什么時候啟動服務(wù)等。Webshell主要提供容器登錄,可以像SSH一樣通過頁面的方式登錄到終端。
- 非root登錄。為了保持容器生產(chǎn)環(huán)境的安全,我們以非root的方式登錄容器控制臺,避免誤刪數(shù)據(jù)。
- Debug容器實現(xiàn),通過啟動一個工具容器,掛載到業(yè)務(wù)容器里,共享網(wǎng)絡(luò)、進(jìn)程等數(shù)據(jù)。傳統(tǒng)的方式希望容器鏡像盡可能小、安裝的軟件盡可能少,這樣啟動更快、安全性更高,但由于容器本身只安裝了程序必要的依賴,導(dǎo)致排查文件困難。為了解決這個問題,我們基于開源技術(shù)開發(fā)了debug容器功能:debug容器掛載到業(yè)務(wù)容器中,共享業(yè)務(wù)容器的網(wǎng)絡(luò)內(nèi)存和主機(jī)相關(guān)的各種信息,這樣一來,就相當(dāng)于在業(yè)務(wù)容器中執(zhí)行了debug命令,既方便運(yùn)維和業(yè)務(wù)人員排查故障,保障了容器的快速安全,又為業(yè)務(wù)提供了一種更好的debug方式。安裝的客戶端如Reids客戶端、MySQL客戶端、Tcpdump等。
- 容器性能監(jiān)控,包括CPU、內(nèi)存、網(wǎng)絡(luò)IO、磁盤IO等監(jiān)控指標(biāo)。
- 審計,用戶所有操作命令都會通過審計工具進(jìn)行審核。
- 摘除實例,主要是針對一些異常容器的故障定位,將流量從負(fù)載均衡上摘除。
- 銷毀功能,當(dāng)容器需要重建時會用到銷毀功能。
除了上文介紹的一排容器按鈕以外,還有一些針對服務(wù)的相關(guān)操作,比如服務(wù)的基本配置:環(huán)境變量、域名解析、健康檢查,服務(wù)的升級,替換鏡像、擴(kuò)縮容等操作。
2.2.2 主要功能點——應(yīng)用商店
很多業(yè)務(wù)場景有這樣的需求:希望可以在測試環(huán)境里實現(xiàn)一鍵啟動中間件服務(wù),如MySQL、Zookerper 、Redis、Kafka等,不需要手動去配置kafka等集群。因此我們提供了中間件容器化的解決方案,將一些常用的中間件導(dǎo)入容器中,后端通過Kubernetes維護(hù)這些中間件的狀態(tài),這樣用戶就可以一鍵創(chuàng)建中間件服務(wù)。但由于這些中間件服務(wù)本身相對來說比較復(fù)雜,所以目前我們的應(yīng)用商店功能主要是為大家提供測試環(huán)境,等這部分功能成熟之后,會把應(yīng)用商店這些常用的中間件拓展到生產(chǎn)環(huán)境上,到時候就可以在生產(chǎn)環(huán)境使用容器化的中間件服務(wù)了。
2.2.3 主要功能點——CI/CD
CI/CD是代碼構(gòu)建流,我們內(nèi)部稱為codeflow。其實代碼構(gòu)建流程非常簡單,一句話概括起來,就是:拉取倉庫源代碼,通過用戶指定的編譯腳本構(gòu)建出執(zhí)行程序,將執(zhí)行程序放到用戶指定部署路徑,并通過啟動命令啟動這個服務(wù)。系統(tǒng)會為每個codeflow生成對應(yīng)的Dockerfile用于構(gòu)建鏡像,用戶不需要具備Docker使用經(jīng)驗。上面的流程是代碼編譯,下面是通過系統(tǒng)預(yù)先生成的Dockerfile,幫用戶打包成Docker Image,這就是從代碼拉取、代碼編譯、打包到Docker Image并推送到鏡像倉庫的整個流程。用戶完成配置并點擊提交代碼后,就可以通過手動或Webhook的方式觸發(fā)整個構(gòu)建流程。也就是說只要用戶一提交代碼,就會觸發(fā)整個構(gòu)建流程,編譯源代碼、打包Docker鏡像、推送鏡像倉庫并觸發(fā)滾動升級,用戶可以在分鐘級別看到效果。在這里我們還做了一些小的功能:
- 非root構(gòu)建。我們的后端其實是在一個Jenkins集群下構(gòu)建的,這樣就存在一個問題:如果用戶在編輯腳本的時候,不小心寫錯代碼就可能會將整個主機(jī)上的東西都刪除,非常不安全。為了解決這個問題,我們在整個構(gòu)建過程中采用非root構(gòu)建的方式,避免某個用戶因編譯腳本執(zhí)行某些特權(quán)操作而影響系統(tǒng)安全。
- 自定義Dockerfile。支持某些用戶使用自己的Dockerfile構(gòu)建鏡像,用戶通過上傳Dockerfile的方式,覆蓋系統(tǒng)生成的Dockerfile。
- 預(yù)處理腳本,主要針對Python類的鏡像構(gòu)建,Python類的鏡像構(gòu)建本身不需要編譯源代碼,但運(yùn)行環(huán)境需要依賴很多第三方的包和庫,如果將這些依賴包都安裝到基礎(chǔ)鏡像,不僅會導(dǎo)致基礎(chǔ)鏡像過大,而且后期維護(hù)也很麻煩。為了支持Python軟件容器化的運(yùn)行,我們提供了預(yù)處理腳本,即在業(yè)務(wù)鏡像之前先執(zhí)行預(yù)處理腳本,幫用戶安裝好所需要的依賴包,然后再把用戶的代碼拷貝過來,基于預(yù)處理腳本之后的鏡像去生成業(yè)務(wù)鏡像,下次構(gòu)建的時候,只要預(yù)處理腳本不變,就可以直接構(gòu)建業(yè)務(wù)鏡像了。
- Webhook觸發(fā)和Gitlab集成,通過Gitlab的Webhook,當(dāng)用戶在提交代碼或者merge pr的時候便可以觸發(fā)codeflow,執(zhí)行自動上線流程。
2.2.4 主要功能點——文件存儲
容器通常需要業(yè)務(wù)進(jìn)行無狀態(tài)的改造,所謂“無狀態(tài)”是需要把一些狀態(tài)數(shù)據(jù)放在外部的中間件或存儲里。我們提供了兩種存儲方式:NFS和Cephfs文件存儲。用戶在頁面選擇存儲的容量,然后點擊創(chuàng)建,就可以直接創(chuàng)建一個Cephfs文件存儲,并且可以在服務(wù)管理頁面指定將這一存儲掛載到容器的某一個路徑下,當(dāng)容器重啟或者遷移后,文件存儲會保持之前的目錄掛載,從而保障數(shù)據(jù)不丟失。
2.2.5 主要功能點——Nginx配置
公司有大概100多個Nginx集群,之前這些Nginx集群都是通過運(yùn)維人員手動方式變更配置和維護(hù),配置文件格式不統(tǒng)一,且容易配置錯誤,問題和故障定位都很困難。為此我們在容器云集成了Nginx配置管理,通過模板的方式生產(chǎn)Nginx配置。Nginx配置的功能比較多,包括健康檢查規(guī)則、灰度發(fā)布策略等相關(guān)配置。上圖是一個系統(tǒng)管理員可以看到的頁面,其中部分項目開放給業(yè)務(wù)用戶,允許用戶自己定義部分Nginx配置,如upstream列表,從而將公司域名配置模板化。除此之外,我們還做了配置文件的多版本對比,Nginx的每次配置都會生成一個對應(yīng)的版本號,這樣就可以看到在什么時間Nginx被誰修改了哪些內(nèi)容等,如果發(fā)現(xiàn)Nginx配置修改有問題,可以點擊回滾到Nginx的歷史版本。泛域名解析,主要適用于測試環(huán)境。之前每一個測試服務(wù)都需要聯(lián)系運(yùn)維人員單獨(dú)申請一個域名,為了節(jié)省用戶申請域名的時間,我們?yōu)槊總€服務(wù)創(chuàng)建一個域名,系統(tǒng)通過泛域名解析的方式,將這些域名都指定到特定的Nginx集群。Nginx后端可以包含容器也可以包含虛擬機(jī),這是在業(yè)務(wù)遷移過程中非常常見的,因為很多業(yè)務(wù)遷移到容器都并非一蹴而就,而是先將部分流量切換到容器內(nèi)運(yùn)行。
2.2.6 主要功能點——配置文件管理
現(xiàn)在的架構(gòu)提倡代碼和配置分離,即在測試環(huán)境和生產(chǎn)環(huán)境使用相同的代碼,不同的配置文件。為了能夠動態(tài)變更配置文件,我們通過Kubernetes的Configmap實現(xiàn)了配置文件管理的功能:將配置文件掛載到容器內(nèi),用戶可以在頁面上傳或者編輯配置文件,保存后,系統(tǒng)將配置文件更新到容器內(nèi)。就是說當(dāng)用戶在頁面上傳或編譯某個配置文件以后,平臺會自動把配置文件刷新到容器里,容器就可以使用最新的配置文件了。為了避免用戶誤刪配置文件,當(dāng)系統(tǒng)發(fā)現(xiàn)配置文件被使用則不允許刪除。
2.2.7 主要功能點——告警管理
告警管理功能基于Prometheus實現(xiàn)。平臺會把所有的監(jiān)控數(shù)據(jù),包括容器相關(guān)的(CPU、內(nèi)存、網(wǎng)絡(luò)IO等)、Nginx相關(guān)的、各個組件狀態(tài)相關(guān)的數(shù)據(jù),都錄入到Prometheus里,用戶可以基于這些指標(biāo)設(shè)置監(jiān)控閾值,如果達(dá)到監(jiān)控閾值,則向運(yùn)維人員或業(yè)務(wù)人員發(fā)送告警。值得一提的是,我們提供了一種特殊的告警:單個容器性能指標(biāo)。按常理,每個容器監(jiān)控指標(biāo)應(yīng)該是類似的,沒有必要針對單個容器設(shè)置告警,但在實際生產(chǎn)環(huán)境中,我們遇到過多次由于某個特定請求觸發(fā)的bug導(dǎo)致CPU飆升的場景,所以開發(fā)了針對單個容器的性能告警。
三、容器容器云平臺落地實踐
前面介紹了系統(tǒng)的一些常用功能,接下來介紹宜信容器云平臺落地過程中的實踐。
3.1 實踐——自定義日志采集
容器的使用方式建議用戶將日志輸出到控制臺,但傳統(tǒng)應(yīng)用的日志都是分級別存儲,如Debug日志、Info日志、Error日志等,業(yè)務(wù)需要采集容器內(nèi)部指定目錄的日志,怎么實現(xiàn)呢?我們通過二次開發(fā)Kubelet,在容器啟動前判斷是否有“KUBERNETES_FILELOGS”這個環(huán)境變量,如果存在,則將“KUBERNETES_FILELOGS”指定的容器目錄掛載到宿主的“/logs/容器名稱”這個目錄下面,配合公司自研的日志采集插件Watchdog便可以將宿主機(jī)上這個目錄下的文件統(tǒng)一收集。
3.2 實踐——TCP代理出口
在實際過程中我們經(jīng)常遇到網(wǎng)絡(luò)對外提供服務(wù)的場景,系統(tǒng)中除了Nginx提供的 HTTP反向代理以外,還有一些需要通過TCP的方式對外提供的服務(wù),我們通過系統(tǒng)中指定的兩臺機(jī)器安裝Keepalive和配置虛IP的方式,對外暴露TCP服務(wù)。
3.3 實踐——自動擴(kuò)容
自動擴(kuò)容,主要是針對業(yè)務(wù)指標(biāo)的一些突發(fā)流量可以做業(yè)務(wù)的自動伸縮。其原理非常簡單:因為我們所有的性能指標(biāo)都是通過Prometheus統(tǒng)一采集,而Cluster-mgr負(fù)責(zé)多集群管理,它會定時(默認(rèn)30s)去Prometheus獲取容器的各種性能指標(biāo),通過上圖的公式計算出每個服務(wù)的最佳副本個數(shù)。公式很簡單:就是每個容器的性能指標(biāo)求和,除以用戶定義目標(biāo)指標(biāo)值,所得結(jié)果即為最佳副本數(shù)。然后Cluster-mgr會調(diào)用Ipaas操作多個集群擴(kuò)容和縮容副本數(shù)。舉個例子,現(xiàn)在有一組容器,我希望它的CPU利用率是50%,但當(dāng)前4個副本,每個副本都達(dá)到80%,求和為320,320除以50,最大副本數(shù)為6,得到結(jié)果后就可以自動擴(kuò)容容器的副本了。
3.4 實踐——多集群管理
傳統(tǒng)模式下,單個Kubernetes集群是很難保證服務(wù)的狀態(tài)的,單個集群部署在單個機(jī)房,如果機(jī)房出現(xiàn)問題,就會導(dǎo)致服務(wù)不可用。因此為了保障服務(wù)的高可用,我們開發(fā)了多集群管理模式。多集群管理模式的原理:在多個機(jī)房分別部署一套Kubernetes集群,并在服務(wù)創(chuàng)建時,把應(yīng)用部署到多個Kubernetes集群中,對外還是提供統(tǒng)一的負(fù)載均衡器,負(fù)載均衡器會把流量分發(fā)到多個Kubernetes集群里去。避免因為一個集群或者機(jī)房故障,而影響服務(wù)的可用性。如果要創(chuàng)建Kubernetes相關(guān)或Deployment相關(guān)的信息,系統(tǒng)會根據(jù)兩個集群的資源用量去分配Deployment副本數(shù);而如果要創(chuàng)建PV、PVC以及Configmap等信息,則會默認(rèn)在多個集群同時創(chuàng)建。集群控制器的功能是負(fù)責(zé)檢測Kubernetes集群的健康狀態(tài),如果不健康則發(fā)出告警,通知運(yùn)維人員切換集群,可以將一個集群的服務(wù)遷移到另一個集群。兩個集群之外通過Nginx切換多集群的流量,保障服務(wù)的高可用。
- 存儲遷移。底層提供了多機(jī)房共享的分布式存儲,可以隨著容器的遷移而遷移。
- 網(wǎng)絡(luò)互通。網(wǎng)絡(luò)是通過Flannel + 共享etcd的方案,實現(xiàn)跨機(jī)房容器互通及業(yè)務(wù)之間的相互調(diào)用。
- 鏡像倉庫間的數(shù)據(jù)同步。為了實現(xiàn)兩個鏡像倉庫之間鏡像的快速拉取,我們在兩個機(jī)房內(nèi)都部署了一個鏡像倉庫,這兩個鏡像倉庫之間的數(shù)據(jù)是互相同步的,這樣就不用跨機(jī)房拉取鏡像了。
3.5 實踐——如何縮短構(gòu)建時間
如何加速整個CI/CD構(gòu)建的流程?這里總結(jié)了四點:
- 代碼pull替換clone。在構(gòu)建代碼的過程中,用pull替換clone的方式。用clone的方式拉取源代碼非常耗時,特別是有些源代碼倉庫很大,拉取代碼要耗費(fèi)十幾秒的時間;而用pull的方式,如果發(fā)現(xiàn)代碼有更新,只需要拉取更新的部分就可以了,不需要重新clone整個源代碼倉庫,從而提高了代碼拉取的速度。
- 本地(私有)倉庫、mvn包本地緩存。我們搭建了很多本地(私有)倉庫,包括Java、Python的倉庫,不需要再去公網(wǎng)拉取依賴包,這樣不僅更安全,而且速度更快。
- 預(yù)處理腳本。只在第一次構(gòu)建時觸發(fā),之后便可以基于預(yù)處理腳本構(gòu)建的鏡像自動構(gòu)建。
- SSD加持。通過SSD硬件的加持,也提高了整個代碼構(gòu)建的速度。
3.6 實踐——什么樣的程序適合容器
- 無操作系統(tǒng)依賴。目前主流容器方案都是基于Linux內(nèi)核的cgroup和namespace相關(guān)技術(shù)實現(xiàn)的,這就意味著容器只能在Linux系統(tǒng)運(yùn)行,如果是Windows或者C#之類的程序是無法運(yùn)行到容器里面的。
- 無固定IP依賴。這個其實不算硬性要求,雖然容器本身是可以實現(xiàn)固定IP地址的,但固定的IP地址會為Deployment的自動伸縮以及集群遷移帶來很多麻煩。
- 無本地數(shù)據(jù)依賴。容器的重新發(fā)布是通過拉取新的鏡像啟動新的容器進(jìn)程的方式,這就希望用戶不要將數(shù)據(jù)保存到容器的本地,而是應(yīng)該借助外部的中間件或者分布式存儲保存這些數(shù)據(jù)。
3.7 避坑指南
在實踐過程中會遇到很多問題,本節(jié)將列舉一些已經(jīng)踩過的坑,逐一與大家分享我們的避坑經(jīng)驗。
3.7.1 為啥我的服務(wù)沒有起來?
這種情況可能是因為服務(wù)被放在了后臺啟動,容器的方式和之前虛擬機(jī)的方式有很大區(qū)別,不能把容器服務(wù)放在后臺啟動,容器啟動的進(jìn)程的PID是1,這個程序進(jìn)程是容器里唯一的啟動進(jìn)程,如果程序退出了容器就結(jié)束了,這就意味著程序不能退出。如果把程序放到后臺啟動,就會出現(xiàn)進(jìn)程起來了但容器服務(wù)沒有起來的情況。
3.7.2 為啥服務(wù)啟動/訪問變慢?
之前使用虛擬機(jī)的時候,由于配置比較高(4核8G),很多業(yè)務(wù)人員沒有關(guān)心過這個問題。使用容器之后,平臺默認(rèn)會選中1核1G的配置,運(yùn)行速度相對較慢,這就導(dǎo)致了業(yè)務(wù)在訪問業(yè)務(wù)的時候會覺得服務(wù)啟動和訪問變慢。
3.7.3 為啥服務(wù)會異常重啟?
這和配置的健康檢查策略有關(guān),如果某應(yīng)用的配置健康檢查策略不通過的話,Kubernetes的Liveness探針將會重啟該應(yīng)用;如果業(yè)務(wù)是健康的,但提供的健康檢查接口有問題或不存在,也會重啟這個容器,所以業(yè)務(wù)要特別注意這個問題。
3.7.4 本地編譯可以,為啥服務(wù)器上代碼編譯失敗?
這個問題非常常見,大多是由于編譯環(huán)境和服務(wù)器環(huán)境的不一致導(dǎo)致的。很多業(yè)務(wù)在本地編譯的時候,本地有一些開發(fā)工具的加持,有一些工作開發(fā)工具幫助完成了,而服務(wù)器上沒有這些工具,因此會出現(xiàn)這個問題。
3.7.5 為啥我的歷史日志找不到了?
這個問題和容器使用相關(guān),容器里默認(rèn)會為用戶保存最近兩天的日志,主機(jī)上有一個清理的功能,日志超過兩天就會被清理掉。那這些超過兩天的日志去哪里查看呢?我們公司有一個統(tǒng)一的日志采集插件Watchdog,負(fù)責(zé)采集存儲歷史日志,可以在日志檢索系統(tǒng)中檢索到這些歷史日志。
3.7.6 為啥IP地址會變化?
每次容器重啟,其IP地址都會發(fā)生變化,希望業(yè)務(wù)人員的代碼不要依賴這些IP地址去配置服務(wù)調(diào)用。
3.7.7 為啥流量會打到異常容器?
容器已經(jīng)異常了,為什么還有流量過來?這個問題具體表現(xiàn)為兩種情況:業(yè)務(wù)沒起來,流量過來了;業(yè)務(wù)已經(jīng)死了,流量還過來。這種兩種情況都是不正常的。
- 第一種情況會導(dǎo)致訪問報錯,這種場景一般是通過配合健康檢查策略完成的,它會檢查容器服務(wù)到底起沒起來,如果檢查OK就會把新的流量打過來,這樣就解決了新容器啟動流量的異常。
- 第二種情況是和容器的優(yōu)雅關(guān)閉相結(jié)合的,容器如果沒有匹配優(yōu)雅關(guān)閉,會導(dǎo)致K8s先去關(guān)閉容器,此時容器還沒有從K8s的Service中摘除,所以還會有流量過去。解決這個問題需要容器里面應(yīng)用能夠支持優(yōu)雅關(guān)閉,發(fā)送優(yōu)雅關(guān)閉時,容器開始自己回收,在優(yōu)雅關(guān)閉時間后強(qiáng)制回收容器。
3.7.8 為啥沒法登錄容器?
很多時候這些容器還沒有起來,此時當(dāng)然就無法登陸。
3.7.9 Nginx后端應(yīng)該配置幾個?OOM?Cache?
這幾個問題也經(jīng)常遇到。在業(yè)務(wù)使用過程中會配置CPU、內(nèi)存相關(guān)的東西,如果沒有合理配置,就會導(dǎo)致容器的OOM。我們新版的容器鏡像都是自適應(yīng)、自動調(diào)整JVM參數(shù),不需要業(yè)務(wù)人員去調(diào)整配置,
3.8 faketime
容器不是虛擬機(jī),所以有些容器的使用方式并不能和虛擬機(jī)完全一致。在我們的業(yè)務(wù)場景里還有一個問題:業(yè)務(wù)需要調(diào)整時鐘。容器和虛擬機(jī)的其中一個區(qū)別是:虛擬機(jī)是獨(dú)立的操作系統(tǒng),修改其中一個虛擬機(jī)里的任何東西都不會影響其他虛擬機(jī)。而容器除了前面說的幾種隔離以外,其他東西都不是隔離的,所有的容器都是共享主機(jī)時鐘的,這就意味著如果你改了一個容器的時鐘,就相當(dāng)于改了整個所有容器的時鐘。如何解決這個問題呢?我們在網(wǎng)上找到一種方案:通過劫持系統(tǒng)調(diào)用的方式修改容器的時鐘。但這個方案有一個問題:faketime不能睡著了。 經(jīng)過幾年的推廣,目前宜信容器云平臺上已經(jīng)支持了100多條業(yè)務(wù)線,運(yùn)行了3700個容器,累計發(fā)布17萬次,還榮獲了“CNCF容器云優(yōu)秀案例”。
務(wù)線、累計發(fā)布17萬次|宜信容器云的A點與B點(分享實錄)")
前文介紹了宜信容器云平臺目前取得的一些小成就,即宜信容器云平臺的A點,接下來介紹宜信容器云的B點,即未來的一些規(guī)劃。
4.1 對象存儲
公司有很多文件需要對外提供訪問,如網(wǎng)頁中的圖片、視頻、pdf、word文檔等,這些文件大部分都是零散地保存在各自系統(tǒng)的存儲中,沒有形成統(tǒng)一的存儲管理。如果文件需要對外提供訪問,則是通過Nginx反向代理掛載NAS存儲的方式,這些文件的維護(hù)成本非常高,安全性也得不到保障。我們基于Ceph開發(fā)一個統(tǒng)一的對象存儲服務(wù),把公司零散在各個系統(tǒng)的小文件集中到對象存儲中去,對于可以提供外網(wǎng)或公網(wǎng)訪問的部分,生成外網(wǎng)訪問的HTTP的URL。目前對象存儲已經(jīng)在業(yè)務(wù)的測試環(huán)境上線。
4.2 站點監(jiān)控
站點監(jiān)控是一個正在重點研發(fā)的功能。公司開源了智能運(yùn)維工具UAVstack,側(cè)重于應(yīng)用的監(jiān)控,還缺乏服務(wù)外部的站點監(jiān)控。站點監(jiān)控是為了監(jiān)控服務(wù)接口的運(yùn)行狀態(tài),并發(fā)送告警。我們通過在公司外部部署采集Agent,這些Agetnt會根據(jù)用戶定義的監(jiān)控URL定時調(diào)用接口是否正常運(yùn)行,如果接口返回數(shù)據(jù)不符合用戶設(shè)定條件則發(fā)出告警,如HTTP返回5xx錯誤或者返回的body中包含ERROR字符等。
4.3 大數(shù)據(jù)容器云
在大部分業(yè)務(wù)遷移到容器后,我們開始嘗試將各種大數(shù)據(jù)中間件(如Spark、Flink等)也遷移到Kubernetes集群之上,利用Kubernetes提供的特性更好地運(yùn)維這些中間件組件,如集群管理、自動部署、服務(wù)遷移、故障恢復(fù)等。
4.4 混合部署
公司有很多長任務(wù),這些長任務(wù)有一個非常明顯的特點:白天訪問量較高,晚上訪問量較低。對應(yīng)的是批處理任務(wù),批處理主要指公司的跑批任務(wù),如報表統(tǒng)計、財務(wù)賬單等,其特點是每天凌晨開始執(zhí)行,執(zhí)行時對CPU和內(nèi)存的消耗特別大,但只運(yùn)行十幾分鐘或幾個小時,白天基本空閑。為了得到更高的資源利用率,我們正在嘗試通過歷史數(shù)據(jù)進(jìn)行建模,將批處理任務(wù)和長任務(wù)混合部署。
4.5 未來規(guī)劃——DevOps平臺
最后介紹我們整個平臺的DevOps規(guī)劃。回到之前容器云的背景,業(yè)務(wù)需要一套統(tǒng)一的DevOps平臺,在這個平臺上,可以幫助業(yè)務(wù)完成代碼構(gòu)建、自動化測試、容器發(fā)布以及應(yīng)用監(jiān)控等一系列功能。其實這些功能我們基礎(chǔ)研發(fā)部門都有所涉及,包括自動化測試平臺 Gebat、應(yīng)用監(jiān)控UAVStack、容器云平臺等,但是業(yè)務(wù)需要登錄到不同的平臺,關(guān)聯(lián)不同的數(shù)據(jù),而各個平臺之間的數(shù)據(jù)不一致、服務(wù)名稱不對應(yīng),沒辦法直接互通,操作起來非常麻煩。我們希望通過建立一個統(tǒng)一的DevOps平臺,把代碼發(fā)布、自動化測試、容器運(yùn)行和監(jiān)控放到同一個平臺上去,讓用戶可以在一個平臺完成所有操作。
【本文是51CTO專欄機(jī)構(gòu)宜信技術(shù)學(xué)院的原創(chuàng)文章,微信公眾號“宜信技術(shù)學(xué)院( id: CE_TECH)”】
戳這里,看該作者更多好文














務(wù)線、累計發(fā)布17萬次|宜信容器云的A點與B點(分享實錄)")
務(wù)線、累計發(fā)布17萬次|宜信容器云的A點與B點(分享實錄)")
務(wù)線、累計發(fā)布17萬次|宜信容器云的A點與B點(分享實錄)")
務(wù)線、累計發(fā)布17萬次|宜信容器云的A點與B點(分享實錄)")
務(wù)線、累計發(fā)布17萬次|宜信容器云的A點與B點(分享實錄)")
務(wù)線、累計發(fā)布17萬次|宜信容器云的A點與B點(分享實錄)")
務(wù)線、累計發(fā)布17萬次|宜信容器云的A點與B點(分享實錄)")
務(wù)線、累計發(fā)布17萬次|宜信容器云的A點與B點(分享實錄)")
務(wù)線、累計發(fā)布17萬次|宜信容器云的A點與B點(分享實錄)")
務(wù)線、累計發(fā)布17萬次|宜信容器云的A點與B點(分享實錄)")
務(wù)線、累計發(fā)布17萬次|宜信容器云的A點與B點(分享實錄)")
務(wù)線、累計發(fā)布17萬次|宜信容器云的A點與B點(分享實錄)")
務(wù)線、累計發(fā)布17萬次|宜信容器云的A點與B點(分享實錄)")
務(wù)線、累計發(fā)布17萬次|宜信容器云的A點與B點(分享實錄)")
務(wù)線、累計發(fā)布17萬次|宜信容器云的A點與B點(分享實錄)")
務(wù)線、累計發(fā)布17萬次|宜信容器云的A點與B點(分享實錄)")
務(wù)線、累計發(fā)布17萬次|宜信容器云的A點與B點(分享實錄)")
務(wù)線、累計發(fā)布17萬次|宜信容器云的A點與B點(分享實錄)")
務(wù)線、累計發(fā)布17萬次|宜信容器云的A點與B點(分享實錄)")
務(wù)線、累計發(fā)布17萬次|宜信容器云的A點與B點(分享實錄)")