宜信鄭赟:大數據金融云的實踐分享
原創宜信積累了九年的數據,有來自合作伙伴的,有用戶授權的,還有一些互聯網公開抓取的數據。所以希望用大數據技術來挖掘其中的數據潛力,尤其是互聯網金融的價值,為客戶提供更好的服務。

鄭赟,宜信技術總監,負責若干大數據驅動的互聯網金融創新產品的研發工作。加入宜信之前,在美國在線視頻公司Hulu任研發經理,負責視頻播放和網站主站的技術研發。并曾在Microsoft從事研發工作。鄭赟畢業于清華大學自動化系,獲碩士學位。
LAIN平臺
鄭赟表示,做云平臺也好,做系統也好,臺子要穩固,要有砥柱。這個砥柱一個是大數據基礎設施,第二個是基于Docker的LAIN平臺。不同業務之間的數據建模是不一樣的。但是比如說像開發環境,像測試,包括自動化測試、常規的測試,包括發布,包括技術服務,比如說像日志收集、監控,包括像分布式架構,像操作系統、網絡、安全等等,這些其實都是通用的,所以我們把這些湊成一個平臺,就是我們的云平臺,就是我們常說的Pass系統。
Docker這兩年以來,特別是今年年初特別火的一項技術,首先它是一個開源容器引擎,第二它其實為了進一步解決虛擬化的問題那么有了這個Docker之后,我們可以把每一個模塊都做到Docker里面去,Docker之間是互相獨立的。然后通過這種微服務的方式,把他們串聯起來,這樣的話就非常靈活。它的性能也非常好,額外開銷幾乎是零。
最中心的是Docker,它外面有三個主要的技術,就是所謂的三架馬車,首先是Docker Swarm,Docker Swarm是Docker官方提供的一個Docker容器管理調度的工具,因為它是官方提供的,所以它有先天集成的優勢。然后是ETCD,ETCD是一個非常著名的,輕量級的分布一致性存儲,我們主要用它來做一些配置存儲,像服務的注冊和服務發現。crlico是某個通信公司開源的一套網絡的技術,它本身是一個三層的SDN可以替代Docker之前傳統的那種通過界定式的方式或者端口移植的方式。
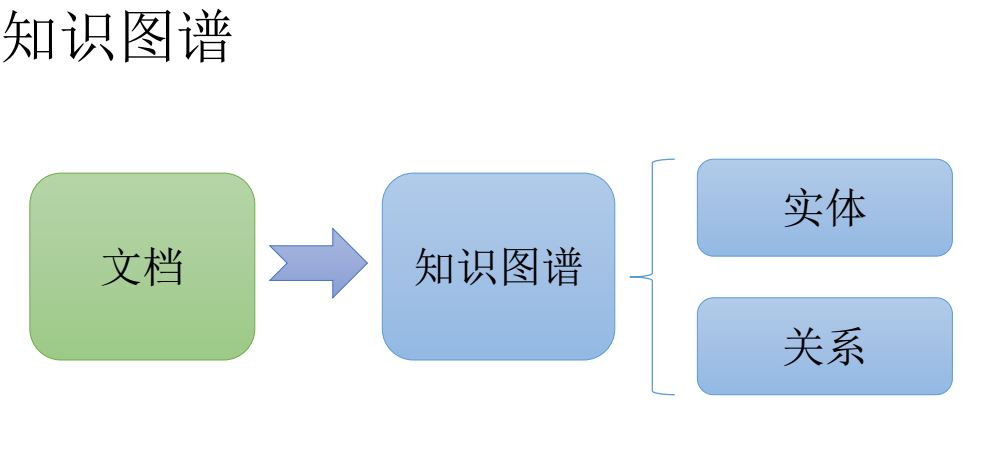
知識圖譜
什么是知識圖譜?相對于傳統的文檔或者是結構化數據來說,它有一個特點,它有實體。最早是google提出來的,用來做搜索優化的,我們用它主要做風控相關的數據建模。還有就是個性化問答,可以根據客戶的信息,甚至個性化的問題用這個來做反欺詐。
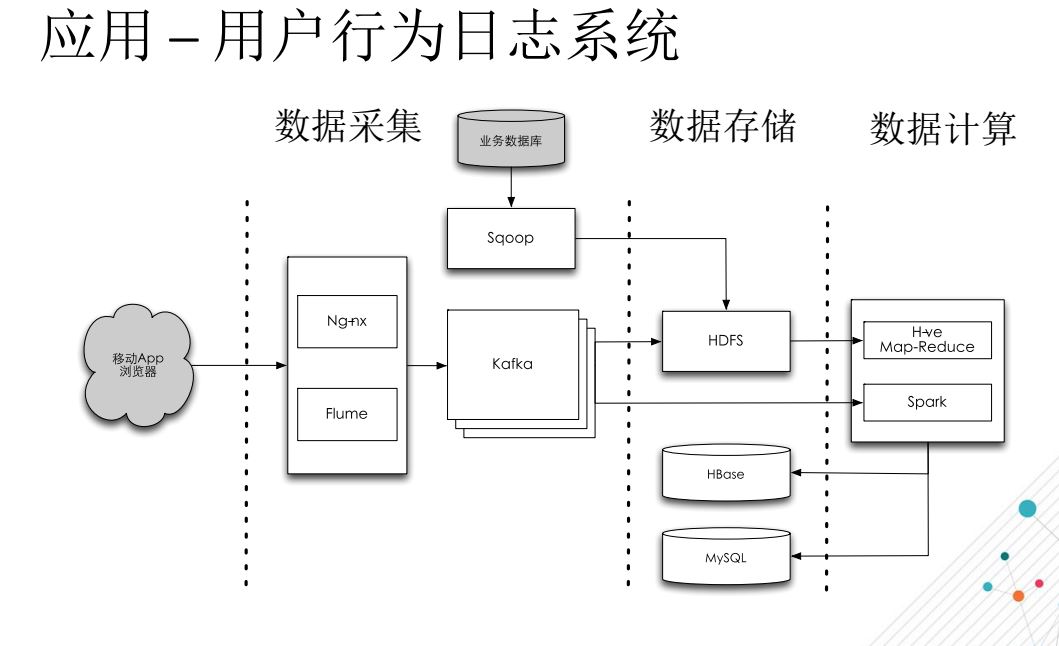
首先在web端,我們會通過我們分布式查詢去排除這些公開的數據以及用戶授權的一些數據,然后把它分到HDFS里面去。然后又把我們業務數據通過Sqoop達到我們的HBase里去,所以我們進行抽取,***結構化形成這樣一個知識圖譜,然后這個知識圖譜里面,我們常用的查詢字段扔到ElasticSearch里面,然后提供給所有的前臺進行使用,同時知識圖譜也可以做規則引擎和機器學習的數據源。
如何解決實時授信中的反欺詐問題
實時授信首先得解決反欺詐的問題。所以我們反欺詐會從三個方面去做。一個是他的身份,首先我們要確定你媽就是你媽,你就是你,所以會從他的平臺賬號是不是真實的,他的個人身份信息是否是真實的,然后通過一些個性化問答來確認他信息的真實性。第二點我們就通過他的行為數據來看,比如說它的經營活動是不是有一些造假痕跡,這個人在互聯網上是不是進過一些中介論壇,他有沒有參與這種活動。第三個方面就是他的關系層級,比如說這個圖上的黑圈是那個黑名單,紅圈是有過逾期的客戶。然后通過各種各樣的數據,***綜合的信用了評分,然后通過評分決定審批和風險評價。
數據驅動的方法論
數據驅動從方法論上來說,首先要有海量數據,第二我得把數據進行歸類,然后再對數據進行分析,***用數據來驅動我們這個產品決策。
對數據進行大分類之后,然后對數據進行進一步的分析。一個是基于已有的數據解釋現象,就是我們知道為什么會是這樣子的。第二更重要的是我們更希望通過這個,能用數據來指導優化未來,這也是大家很多公司都想追求的目標。
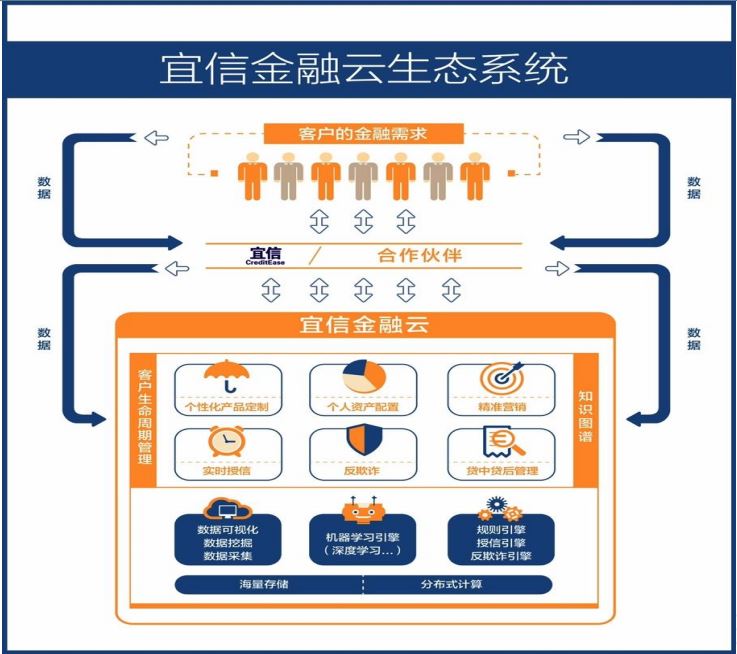
總結整個演講:首先我們整個金融云需要一個底層的支柱,就是我剛才所說的大數據的基礎設施和剛才說云平臺,在它之上,我們通過像姨搜這樣的應用快速搭建一些比較核心的模塊,比如說像反欺詐,像實時授信,***我們通過兩個端的產品,商貸和理財的產品自己用這樣的平臺不斷地去優化整個產品,以及優化下面核心模塊,然后使得整個平臺形成一套完整的框架。在這個框架之上,我們希望給我們的用戶提供更好的服務。也正在跟合作伙伴進行數據對接,提供一些服務化的場景。